Ugrás a tartalomra
Ugrás a tartalomra 
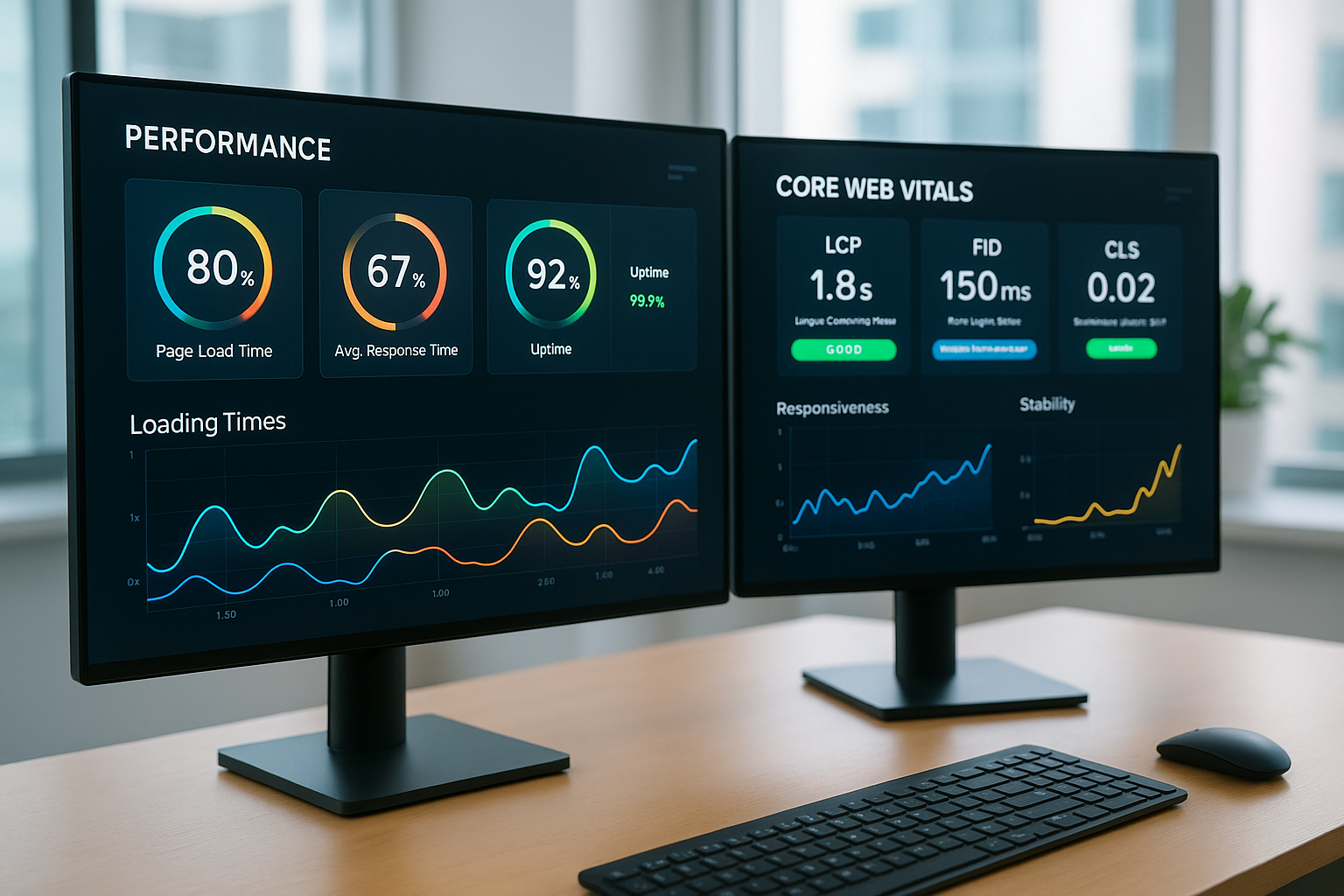
Az AI monitoring új szintre emeli az autonóm web hostingot: valós időben elemzem a naplókat, automatizálom a riasztásokat és azonosítom a trendeket, mielőtt a felhasználók bármit is észrevennének. Ez lehetővé teszi számomra az öngyógyító munkafolyamatok vezérlését, a kapacitások előrelátó tervezését és a szolgáltatások megbízhatóan zöld zónában tartását - emberi jóváhagyások sorban állása nélkül és egyértelmű Döntési szabályok.
Központi pontok
A következő szempontok alkotják a témával kapcsolatos részletes vita és gyakorlati példák kompakt keretét. autonóm felügyelet:
- Valós idejű elemzések a naplóáradatokat használható tippekké alakítja át.
- Automatizált riasztások speciális munkafolyamatok és öngyógyítás kiváltása.
- Trend modellek a kapacitástervezés és a költségellenőrzés támogatása.
- Biztonsági események még a kár bekövetkezése előtt észreveszik.
- Irányítási politikák a döntések érthetővé tétele.

Mi az autonóm felügyelet a web hostingban?
Az autonóm felügyelet olyan rendszereket ír le, amelyek önállóan figyelik és értékelik a naplókat, mérőszámokat és nyomokat, és ezekből merev szabályoktól függetlenül intézkedéseket vezetnek le; ezeket a képességeket napi szinten használom a válaszidők drasztikus csökkentésére és a kockázatok mérséklésére. Köszönhetően a Gépi tanulás-modellek alapján azonosítom az alapvonalakat, felismerem az eltéréseket és munkafolyamatokat indítok, amelyek jegyeket, szkripteket vagy API-hívásokat hajtanak végre. Ez lehetővé teszi számomra, hogy korábban beavatkozzak, a szolgáltatásokat elérhetővé tegyem és a csapatokat mentesítsem a rutinmunkától. A döntési logika átlátható és ellenőrizhető marad, így minden művelet nyomon követhető marad. Ez lehetővé teszi számomra, hogy magas szolgáltatásminőséget érjek el, még akkor is, ha az adatmennyiség és a rendszerek sokfélesége növekszik.
A merev küszöbértékektől a tanuló rendszerekig
A múltban a merev küszöbértékek és az egyszerű regex szabályok elzárkóztak a lényeges dolgok elől, mert zajt generáltak, vagy figyelmen kívül hagyták a kritikus mintákat. Ma a modellezés AI a tipikus terhelési profilok, a hibafrekvenciák és a szezonális csúcsok automatikusan. Folyamatosan tanulom és frissítem a modelleket, hogy figyelembe vegyék a napszakokat, a kiadási ciklusokat és az ünnepnapok hatásait. Ha egy érték kívül esik a megtanult spektrumon, azonnal anomáliaként jelölöm meg az eseményt, és olyan kontextusokhoz rendelem, mint a szolgáltatás, a fürt vagy az ügyfél. Ily módon a merev szabályokat dinamikus normalitással helyettesítem - és jelentősen csökkentem a téves riasztásokat.

Hogyan olvassa és használja a naplófájlokat valós időben a mesterséges intelligencia?
Először is, minden lényeges ponton adatokat gyűjtök: A rendszernaplók, az alkalmazási naplók, a hozzáférési naplók, a metrikák és az események egy folyamba áramlanak, amelyet szabványosított módon osztályozok és dúsítok. A heterogén formátumok esetében elemzőket és sémákat használok, hogy a strukturált és strukturálatlan bejegyzéseket hasznosítani lehessen; egy tiszta Napló-aggregáció a tárhelyen. Ezután modelleket képzek a történelmi és friss adatokon, hogy felismerjem az alapvonalakat és a szignatúrákat; ez lehetővé teszi számomra, hogy megkülönböztessem a tipikus hibákat a szokatlan mintáktól. Éles üzemben minden bejövő bejegyzést elemzek, kiszámítom az eltéréseket, és ezeket kontextuális információkkal együtt incidensekké aggregálom. Ha rendellenességek fordulnak elő, meghatározott játékmenet-könyveket indítok el, és minden műveletet dokumentálok a későbbi ellenőrzésekhez - ez megkönnyíti a döntéshozatalt. érthető.
Automatizálja a riasztásokat és szervezze meg az öngyógyítást
Egy riasztás önmagában nem oldja meg a problémát; a jelzéseket konkrét intézkedésekkel kapcsolom össze. Megnövekedett késleltetés esetén például újraindítok bizonyos szolgáltatásokat, ideiglenesen bővítem az erőforrásokat vagy kiürítem a gyorsítótárakat, mielőtt a felhasználók késést észlelnének. Ha egy telepítés meghiúsul, automatikusan visszaállítom az utolsó stabil verzióra, és szinkronizálom a konfigurációkat. Minden lépést playbookként tartok nyilván, rendszeresen tesztelem őket, és finomítom a triggereket, hogy a beavatkozások hajszálpontosan történjenek. Ily módon a műveletek proaktívak maradnak, és a MTTR alacsony.
Trendelemzések és kapacitástervezés
A hosszú távú minták kézzelfogható támpontokat nyújtanak a kapacitások, a költségek és az építészeti döntések tekintetében. Összefüggésbe hozom a kihasználtságot a kiadásokkal, kampányokkal és szezonalitásokkal, és szimulálom a terhelési csúcsokat, hogy a szűk keresztmetszeteket már korai szakaszban tompítsam. Ennek alapján előrelátóan tervezem meg a skálázást, a tárolást és a hálózati tartalékokat ahelyett, hogy spontán reagálnék. A műszerfalak hőtérképeket és SLO-eltolódásokat mutatnak nekem, így kiszámítható módon tudom kezelni a költségvetést és az erőforrásokat; az olyan kiegészítések, mint pl. Teljesítményfigyelés növeli az információs értéket. Így tartom a szolgáltatásokat egyszerre hatékonyak és biztonságosak Puffer előre nem látható eseményekre.

Gyakorlat: tipikus hosting munkafolyamatok, amelyeket automatizálok
A javításkezelés idővezérelt, előzetes kompatibilitás-ellenőrzéssel és egyértelmű visszaállítási lehetőséggel, ha a telemetria kockázatokat mutat. A biztonsági mentéseket kockázatalapú alapon tervezem, és a gyakoriságot és a megőrzést a meghibásodási valószínűségekből és az RPO/RTO célokból vonom le. Konténerproblémák esetén átütemezem a podokat, friss képeket húzok és megújítom a titkokat, amint a jelek sérült példányokat jeleznek. A több felhőből álló beállításoknál szabványosított megfigyelhetőséget használok, hogy központilag alkalmazhassam a házirendeket, és a reakciók konzisztensek maradjanak. Az adathozzáféréseket auditálhatóvá teszem, hogy a biztonsági csapatok minden változásról értesüljenek. ellenőrizze a címet. lehet.
Irányítás, adatvédelem és megfelelés
Az autonómiának védőkorlátokra van szüksége, ezért fogalmazom meg az irányelveket kódként, és határozok meg jóváhagyási szinteket a kritikus műveletekhez. Minden mesterséges intelligencia döntést naplózok időbélyeggel, kontextussal és tartaléktervvel, hogy az ellenőrzések zökkenőmentesek maradjanak, és a kockázatok korlátozottak legyenek. A szükséges minimumra csökkentett, álnevesített és titkosított adatokat dolgozom fel; szigorúan betartom az adatmegmaradási szabályokat. Elkülönítem a szerepkör- és jogosultsági fogalmakat, hogy a meglátások széles körben lehetségesek legyenek, miközben csak a kiválasztott fiókok avatkozhatnak be. A játéknapokon célzott zavarokat állítok be, hogy az öngyógyító mechanizmusok megbízhatóan megvalósíthatók legyenek. reagálj.
Építészet: az ügynöktől a döntésig
A könnyűsúlyú ügynökök a munkaterheléshez közeli jeleket gyűjtenek, normalizálják azokat, és elküldik a deduplikációval és sebességkorlátozással rendelkező, ingest-képes végpontokra. Egy feldolgozási réteg topológiával, telepítésekkel és szolgáltatáscímkékkel gazdagítja az eseményeket, hogy gyorsabban azonosíthassam a kiváltó okokat. A jellemzőtárolók alapvonalakat és szignatúrákat biztosítanak, hogy a modellek a következtetés során folyamatosan az aktuális kontextusokat használják. A döntési szint összekapcsolja az anomáliákat a playbookokkal, amelyek jegyeket, API-hívásokat vagy javító szkripteket indítanak; a visszajelzés pedig a modell visszajelzéseibe áramlik. Így az egész ciklus felismerhető, mérhető és mérhető marad. szabályozható.
Szolgáltatói ellenőrzés: AI monitoring összehasonlításban
A funkciók jelentősen különböznek egymástól, ezért vizsgálom a valós idejű képességeket, az automatizálás mélységét, az öngyógyítást és a trendelemzéseket. Különösen fontos a meglévő eszközláncokba való tiszta integráció, mivel az interfészek határozzák meg a ráfordítást és a hatást. Számos projektben a webhoster.de magas pontszámot ér el a végponttól végpontig terjedő AI-mechanizmusokkal és az erős orchestrálással; a prediktív megközelítések támogatják a prediktív karbantartást, amit egyértelmű előnynek tekintek. Gyors indítást biztosítok azáltal, hogy előre meghatározom az alapvető mérőszámokat, és lépésről lépésre bővítem a playbookokat; így az automatizálás kockázat nélkül növekszik. Alaposabb tervezéshez Előrejelző karbantartás újrafelhasználhatónak Építőkocka.
| Szolgáltató | Valós idejű megfigyelés | Előrejelző karbantartás | Automatizált riasztások | Öngyógyító | Az integráció mélysége | Mesterséges intelligencia által támogatott trendelemzés |
|---|---|---|---|---|---|---|
| webhoster.de | Igen | Igen | Igen | Igen | Magas | Igen |
| B szolgáltató | Igen | Részben | Igen | Nem | Közepes | Nem |
| Szolgáltató C | Részben | Nem | Részben | Nem | Alacsony | Nem |
KPI-k és mérőszámok, amelyek számítanak
A mesterséges intelligencia felügyeletét egyértelmű számokkal ellenőrzöm: SLO teljesítés, MTTR, anomáliasűrűség, téves riasztási arány és eseményenkénti költség. Az adatok késleltetését és a rögzítési arányt is figyelemmel kísérem, hogy a valós idejű állítások a gyakorlatban is megállják a helyüket. A kapacitás tekintetében a kihasználtsági csúcsokat, a 95. és 99. percentiliseket, az I/O-várakozási időket és a memória fragmentáltságát figyelem. A biztonsági oldalon a szokatlan bejelentkezési mintákat, a házirendek megsértését és az adatkiáramlások anomáliáit ellenőrzöm, hogy az incidenseket időben felismerhessem. Ezeket a KPI-ket összekapcsolom a műszerfalakkal és a költségvetési célokkal, hogy a technológia és a jövedelmezőség összekapcsolható legyen. munka.
Adatminőség, kardinalitás és sémafejlődés
A jó döntések tiszta adatokkal kezdődnek. Egyértelmű sémákat és verziókezelést hozok létre, hogy a naplók, a mérőszámok és a nyomvonalak hosszú távon kompatibilisek maradjanak. Szándékosan korlátozom a nagy kardinalitású mezőket (pl. a címkékben szereplő szabad felhasználói azonosítók), hogy elkerüljem a költségrobbanásokat és a nem hatékony lekérdezéseket. Az ellenőrizetlen címkeáradat helyett fehér listákat, hashinget használok a szabad szöveghez és dedikált mezőket az aggregációkhoz. A strukturálatlan naplók esetében a strukturálást lépésről lépésre vezetem be: először durva osztályozás, majd finomabb kinyerés, amint a minták stabilak. A mintavételt differenciáltan alkalmazom: Fejmintavételezés a költségvédelem érdekében, farokalapú mintavételezés a ritka hibákhoz, hogy az értékes részletek ne vesszenek el. A séma módosításakor közzéteszem a migrációs útvonalakat, és betartom az átállási időket, hogy a műszerfalak és a riasztások folyamatosan működjenek.
Folyamatosan ellenőrzöm a nyers adatokat a minőségi szabályok alapján: Kötelező mezők, értéktartományok, időbélyegek eltolódása, deduplikáció. Ha jogsértések merülnek fel, külön incidensként jelölöm meg őket, hogy az okokat - például egy szolgáltatás hibás naplóformázója - még korai szakaszban korrigálhassuk. Így megakadályozom, hogy a mesterséges intelligencia kétes jelekből tanuljon, és magasan tartom a modellek érvényességét.
MLOps: Modell életciklus a megfigyelésben
A modellek csak akkor teljesítenek, ha életciklusukat szakszerűen kezelik. Az anomália-érzékelőket múltbeli adatokon képzem ki, és olyan „kalibrált heteken“ validálom őket, amelyekben ismert incidensek vannak. Ezután árnyék üzemmódban indulok el: az új modell kiértékeli az élő adatokat, de nem indít el semmilyen műveletet. Ha a pontosság és a visszahívás megfelelő, átváltok ellenőrzött aktiválásra, szigorú védőkorláttal. A verziókezelés, a funkciótárolók és a reprodukálható csővezetékek kötelezőek; sodródás vagy teljesítménycsökkenés esetén automatikusan visszaállítom a modelleket. Az incidensekből származó visszajelzések (igaz/hamis pozitív) képzési jelként visszaáramlanak, és javítják az osztályozókat. Ez egy folyamatos tanulási ciklust hoz létre a stabilitás feláldozása nélkül.

Az SLO-k, SLI-k és hibakövetelmények operacionalizálása
A riasztásokat már nem a csupasz küszöbértékekre alapozom, hanem az SLO-kra és a hibabüdzsékre. Több időablakon (gyors és lassú) átívelő égési sebesség-stratégiákat használok, hogy a rövid távú kiugró értékek ne eszkalálódjanak azonnal, de a tartós romlás gyorsan észrevehető legyen. Minden egyes eszkalációs szint speciális intézkedéseket hordoz: a terheléskiegyenlítéstől és a gyorsítótár felmelegítésétől kezdve a forgalom alakításáig és a csak olvasható üzemmódig. Az SLO-eltolódások megjelennek a műszerfalakon és beépülnek a postmortemekbe, így láthatóvá válik, hogy mely szolgáltatások fogyasztják szisztematikusan a költségvetést. Ez a kapcsolódás biztosítja, hogy az automatizmusok egyszerre tartsák tiszteletben a gazdasági és minőségi célokat.
Többszemélyes használat és több ügyfélképesség
A tárhely-környezetben gyakran dolgozom megosztott platformokkal. Szigorúan elkülönítem a jeleket ügyfél, régió és szolgáltatási szint szerint, hogy az alapvonalak kontextusonként tanuljanak, és a „zajos szomszédok“ ne vetítsenek árnyékot. A kvóták, sebességkorlátozások és a priorizálás a csővezetékbe tartozik, hogy egy naplótüskékkel rendelkező bérlő ne veszélyeztesse más szolgáltatások megfigyelhetőségét. Az ügyféljelentésekhez érthető összefoglalókat készítek a hatás, az ok-okozati hipotézis és a megtett intézkedések feltüntetésével - ellenőrizhetően és érzékeny kereszthivatkozások nélkül. Ez biztosítja az elszigeteltséget, a méltányosságot és a nyomon követhetőséget.

Biztonsági integráció: a jelektől az intézkedésekig
A megfigyelhetőséget és a biztonsági adatokat úgy kapcsolom össze, hogy a támadások már korai szakaszban láthatóvá váljanak. Összefüggésbe hozom a szokatlan auth-mintákat, az oldalirányú mozgásokat, a gyanús folyamatok indítását vagy a felhőkonfiguráció sodródását a szolgáltatási telemetriával. A reakcióláncok a munkamenet-elszigeteléstől és a titokforgatástól az ideiglenes hálózati szegmentációig terjednek. Minden művelet visszafordítható, naplózott és kiadási irányelvekhez kötött. Az alacsony és lassú észlelések különösen értékesek: a lassú adatkiszivárgás vagy a jogok kúszó kiterjesztése trendtörésekkel és anomáliák összegzésével észlelhető - gyakran még a hagyományos aláírások hatása előtt.
Költségellenőrzés és FinOps a nyomon követésben
A megfigyelhetőség önmagában nem válhat költségtényezővé. Meghatározom az eseményenkénti költségeket, és költségvetést állítok be az adatbevitelre, a tárolásra és a számítástechnikára. Az aktuális incidensek számára a forró tárolóhelyeket szűkösnek tartom, míg a régebbi adatokat olcsóbb szintekre helyezem át. Az aggregációk, a mérőszámok összevonása és a differenciált mintavételezés a diagnosztikai képességek elvesztése nélkül csökkenti a mennyiséget. A prediktív elemzések segítenek elkerülni a túlellátást: Előre látva méretezek ahelyett, hogy állandóan nagy tartalékokat tartanék. Ugyanakkor figyelemmel kísérem a „költségkésleltetést“ - vagyis azt, hogy milyen gyorsan válnak nyilvánvalóvá a költségrobbanások -, hogy az ellenintézkedések időben kifejthessék hatásukat.

Tesztelés, káosz és folyamatos ellenőrzés
Csak akkor bízom az automatizálásban, ha az bizonyítani tudja magát. A szintetikus monitorozás folyamatosan ellenőrzi az alapvető útvonalakat. Káoszkísérletek szimulálják a csomópontok meghibásodását, a hálózati késleltetéseket vagy a hibás telepítéseket - mindig egyértelmű törlési kritériummal. A playbookokat úgy tesztelem, mint a szoftvereket: egység- és integrációs tesztek, száraz futtatási mód és verziókezelés. A staging környezetekben ellenőrzöm a visszaállításokat, a hitelesítő adatok cseréjét és az adatok helyreállítását a meghatározott RPO/RTO célokkal szemben. A megállapításokat átviszem a futtatókönyvekbe, és az ügyeleti csapatokat kifejezetten a ritka, de kritikus forgatókönyvekre képzem ki.
A végrehajtás ütemezése: 30/60/90 nap
A strukturált kezdés minimalizálja a kockázatokat és korai eredményeket hoz. 30 nap alatt konszolidálom az adatgyűjtést, meghatározom az alapvető mérőszámokat, létrehozom a kezdeti műszerfalakat és 3-5 játékkönyvet (pl. cache visszaállítása, szolgáltatás újraindítása, visszaállítás). 60 nap alatt SLO-kat állítok fel, árnyékmodelleket vezetek be az anomáliákhoz, és az alacsony kockázatú esetekben bekapcsolom az öngyógyítást. Ezt követik 90 napon belül az ügyféljelentések, költségellenőrzések, biztonsági összefüggések és játéknapok. Minden fázis felülvizsgálattal és a tanulságok levonásával zárul a minőség és az elfogadottság növelése érdekében.
Perem- és hibrid forgatókönyvek
A peremcsomópontokkal és hibrid felhőkkel rendelkező elosztott beállításoknál figyelembe veszem az időszakos kapcsolatokat. Az ügynökök helyben pufferelnek, és szinkronizálnak a visszanyomással, amint a sávszélesség rendelkezésre áll. A forráshoz közeli döntések lerövidítik a késleltetési időt - például az instabil konténerek helyi izolálása. A konfigurációs állapotokat deklaratívan tartom, és megbízhatóan replikálom őket, hogy a peremhelyzetek determinisztikusan viselkedjenek. Így az autonómia még akkor is hatékony marad, ha a központi rendszerek csak átmenetileg érhetők el.
Kockázatok és antiminták - és hogyan kerülöm el őket
Az automatizálás eszkalációs hurkokat hozhat létre: az agresszív újbóli próbálkozások súlyosbítják a terhelési csúcsokat, a csapkodó riasztások kifárasztják a csapatokat, a hiszterézis hiánya pedig „fidgeting-effektusokhoz“ vezet. Visszavonást, megszakítókat, kvórumokat, karbantartási ablakokat és hiszterézisgörbéket használok. A műveletek idempotens módon futnak, időkorlátokkal és egyértelmű megszakítási szabályokkal. A kritikus útvonalak mindig rendelkeznek kézi felülbírálási mechanizmussal. És: Nincs játékkönyv dokumentált kilépési és visszaállítási útvonal nélkül. Ezáltal az előnyök magasak, a kockázatok pedig kezelhetőek maradnak.
Gyakorlati példák mélységében
Példa 1: Egy termékkampány 5x forgalmat generál. A trendmodellek már a csúcsidőszakok előtt felismerik a növekvő kérésszámot és a növekvő 99 késleltetést. Előmelegítem a gyorsítótárakat, növelem a replikák számát és skálázom az adatbázis-olvasó csomópontokat. Amikor az égési ráta meghalad egy küszöbértéket, a számításigényes másodlagos feladatokat visszafogom, hogy a hibaköltségvetés ne boruljon fel. A csúcs után a kapacitásokat rendezett módon visszavezetem, és dokumentálom a költség- és SLO-hatásokat.
2. példa: A konténerfürtökben az OOM-ölések felhalmozódnak egy névtérben. Az AI korrelálja a telepítési időket, a konténerváltozatot és a csomópontok típusait, és egy szűk időablakot anomáliaként jelöl meg. Elindítom a hibás kép visszaállítását, ideiglenesen megnövelem az érintett podok limitjeit, és megtisztítom a szivárgásokat az oldalkocsikban. Ezzel egyidejűleg egy házirend segítségével blokkolom az új telepítéseket, amíg a javítás nem kerül ellenőrzésre. Az MTTR alacsony marad, mivel az észlelés, az ok és az intézkedések láncolata összekapcsolódik.
Kilátások: merre tart az autonóm felügyelet
A generatív asszisztensek létrehozzák, tesztelik és verziózzák a játékkönyveket, míg az autonóm ügynökök a kockázatoktól függően maguk delegálják vagy hajtják végre a döntéseket. Az építészeti döntések inkább a tanulási görbéken alapulnak majd; a modellek felismerik a korábban észrevétlenül maradt finom változásokat. Arra számítok, hogy a megfigyelhetőség, a biztonság és a FinOps szorosabban összekapcsolódik majd, hogy a jelzéseknek átfogó hatása legyen, és a költségvetéseket kíméljük. Ezzel egyidejűleg a megmagyarázhatóság jelentősége is növekszik, hogy a mesterséges intelligencia döntései átláthatóak és ellenőrizhetők maradjanak. Azok, akik az alapelemeket már most lefektetik, már korán profitálhatnak a termelékenységből és a Rugalmasság.
Összefoglaló
Az autonóm felügyelet a valós idejű elemzéseket, az automatikus reagálást és a tervezhető optimalizálást egy folyamatos ciklusban egyesíti. Folyamatosan olvasom a naplókat, felismerem az anomáliákat és célzott intézkedéseket kezdeményezek, mielőtt a felhasználók bármilyen korlátozást észlelnének. A trendmodellek tervezési biztonságot nyújtanak számomra, míg az irányítási szabályok minden döntést biztosítanak. A tiszta kezdés adatgyűjtéssel, alapvonalakkal és néhány, jól tesztelt playbookkal történik; ezután lépésről lépésre skálázom fel. Így a tárhely elérhető, hatékony és biztonságos marad - és AI a műveletek és a növekedés multiplikátorává válik.