 コンテンツにスキップ
コンテンツにスキップ 
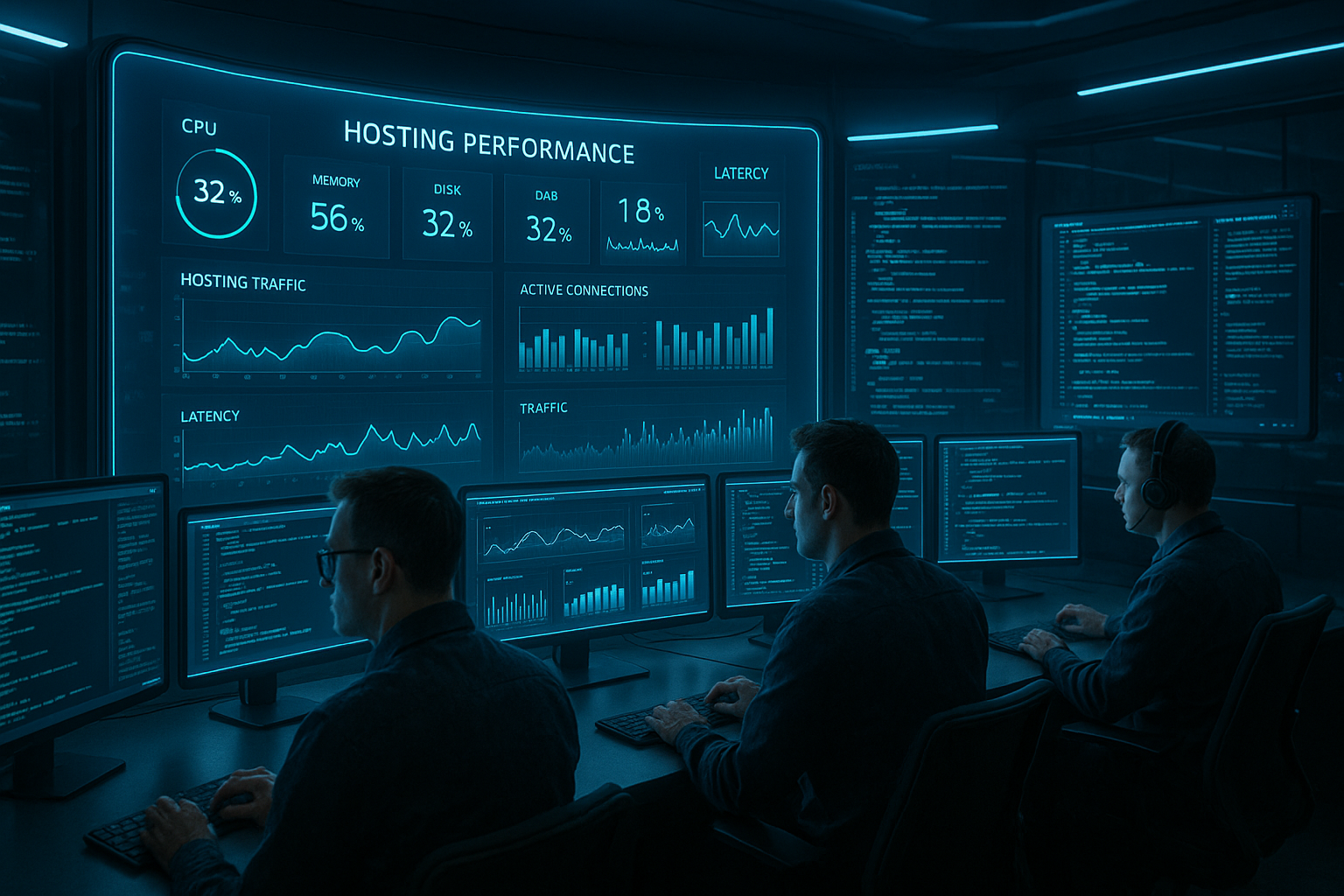
ホスティングのパフォーマンス監視では、パフォーマンスのボトルネックを早い段階で認識できます。 ツール そして 過去ログ は、関連するシグナルをリアルタイムで提供してくれます。プロアクティブ・アラート、異常検知、きれいに相関したログ・データによって、私はレイテンシーを低く保ち、機能停止を防ぎ、検索における可視性をサポートしています。
中心点
私は、明確な主要数値、自動化された警告、意味のあるログデータを優先しています。なぜなら、これらによって迅速な診断が可能になり、オペレーションを守ることができるからです。構造化されたセットアップ・プロセスは、計測の混乱を防ぎ、根拠のある意思決定のための信頼できるデータ基盤を作ります。私は、ストレスの多い状況で物事を見失わないように、数は少ないが意味のあるダッシュボードを選んでいる。チャットとチケッティングの統合は、応答時間を短縮し、エスカレーションを減らす。最終的に重要なのは、モニタリングがさらなる複雑さを生み出すのではなく、ダウンタイムを減らし、ユーザー・エクスペリエンスを向上させることです。 規格 そして一貫した チューニング.
- 指標 優先順位をつける:遅延、エラー率、利用率
- 過去ログ 一元化:構造化フィールド、コンテキスト、リテンション
- アラート を自動化する:しきい値、SLO、エスカレーションパス
- 統合 使用するSlack/Eメール、チケット、ChatOps
- 比較 ツールの機能、コスト、労力

プロアクティブ・モニタリングが重要な理由
サポートからの苦情を待たずに、私はそれを理解する。 予想 そして アノマリー システムの方向性を早期に把握する。1ミリ秒単位の遅延がコンバージョンやSEOに影響するため、私は単発のピークではなく、永続的なトレンドを観察している。これにより、負荷のピークが発生する前に不要な依存関係を断ち、バッファを作ることができる。エラー率の増加、キューの増加、ガベージコレクタの頻繁な実行。これらの兆候を読み取ることで、ダウンタイムを防ぎ、コストを削減し、信頼を高めることができる。
どの指標が本当に重要か
ApdexやP95のレイテンシー、エラー率、CPU/RAM、I/O、ネットワークのレイテンシー、利用可能なDB接続などです。リソースを明確にしないと、原因を見逃すことが多いので、私はあらゆるレベルの相関ビューに注意を払っています。ホスト・ビューについては、次のようなものが役立っている。 サーバー稼働率の監視ノードレベルでのボトルネックを素早く確認するためだ。60秒のスクレイプは短いスパイクを見逃すのに対し、10秒のインターバルはより細かいパターンを示すので、私は測定間隔を意図的に評価している。定義されたSLOに対してメトリクスをミラーリングすることが重要であることに変わりはない。 優先順位 そして コンテクスト.
指標設計:USE/RED、ヒストグラム、カーディナリティ
私は実績のある方法に従って信号を構成する:ホスト・レベルではUSEフレームワーク(利用率、飽和度、エラー)を、サービス・レベルではREDモデル(レート、エラー、継続時間)を使用しています。これにより、各グラフが的を絞った検証可能なものとなります。P95/P99が信頼でき、回帰が見えるように、平均値だけでなくヒストグラムでレイテンシーを測定しています。きれいに定義されたバケットはエイリアシングを防ぎます:粗すぎるとスパイクを飲み込み、細かすぎるとメモリとコストが肥大化します。粗すぎるとスパイクを飲み込み、細かすぎるとメモリとコストが肥大化する。高頻度のエンドポイントについては、個々の遅いリクエストをトレースできるようにコピーデータを用意しておく。
user_idやrequest_idのようなラベルは、ログやトレースには含まれますが、メトリクスにはほとんど含まれません。私はラベルセットを小さく保ち、サービス/バージョン/リージョン/環境に依存し、命名基準を文書化します。これにより、ダッシュボードは高速になり、ストレージは計画しやすくなり、クエリは明確になります。過去の比較が古くならないように、バケットを変更したときにメトリクス(http_server_duration_seconds_v2など)をバージョンアップしています。

早期警告システムとしてのログ
ログは、コードパス、タイミング、ユーザーコンテキストを可視化するため、実際に何が起こっているかを教えてくれる。trace_id、user_id、request_id、serviceなどのフィールドを構造化して、リクエストをエンドツーエンドで追跡できるようにしています。運用作業には ログの分析エラーの発生源、待ち時間のピーク、セキュリティのパターンをより早く認識するためだ。明確に定義されたログ・レベルがなければ、その量は高くつく。これが、デバッグを控えめに使い、短期間だけログを増やす理由だ。そのため、私はデバッグを控えめにし、短期間だけログを増やすようにしている。 クリア の代わりに だだっ広い.
管理下のコスト:カーディナリティ、リテンション、サンプリング
私は積極的にコストを管理している。ログデータをホット/ウォーム/コールドの階層に分け、それぞれに保持と圧縮を設定している。ダッシュボードを支配しないように、インジェスト時にエラーや極端に大きな音量のイベントを正規化または重複排除します。トレースは動的にサンプリングする。エラーと高レイテンシーは常にサンプリングし、正常なケースは比例的にサンプリングする。メトリックスについては、長期的なトレンドのためにダウンサンプリングを選択し、ストレージの使用率が予測できるように生データを短くしている。€/ホスト、€/GB、€/アラートによるコストダッシュボードは、消費を可視化し、予算アラートは月末のサプライズを防ぐ。
ツール比較:一目でわかる強み
私は、ログ、メトリクス、トレースを組み合わせたソリューションを好む。Better Stack、Sematext、Sumo Logic、Datadogは多くのアプリケーションシナリオをカバーしているが、フォーカスしているもの、運用、価格ロジックが異なる。KubernetesとAWSを使うチームにとって、緊密なクラウド統合は有益だ。データを保持したい場合は、エクスポート機能と長期保存に注意を払う必要がある。決定する前に、TCO、セットアップの手間、学習曲線をチェックする。 調査結果 最後に まばら は残る。
| 工具 | フォーカス | 強み | こんな方に最適 | 価格/ヒント |
|---|---|---|---|---|
| ベター・スタック | ログ+アップタイム | シンプルなインターフェース、素早い検索、優れたダッシュボード | 新興企業、明確なワークフローを持つチーム | 数量により月額約2桁ユーロから |
| セマテキスト | ELKのようなログ管理 | 多くの統合、リアルタイムアラート、インフラ+アプリ | ハイブリッド環境、多様な遠隔測定 | GB/日単位で、月額2桁ユーロから。 |
| 相撲ロジック | ログ分析 | トレンド検出、異常、予測分析 | セキュリティおよびコンプライアンスチーム | ボリュームベース、中〜上級€レベル |
| Datadog | ログ+メトリクス+セキュリティ | ML異常値、サービスマップ、強力なクラウド接続 | クラウドワークロードのスケーリング | モジュール価格、機能別、€は範囲による |
人工的なサンプルではなく、実際のピークを使ってツールをテストすることで、パフォーマンスの限界を正直に見ることができる。堅牢なPOCには、データ・パイプライン、アラート、オンコール・ルーティング、オーソリゼーションのコンセプトが含まれる。私は、解析、保持、コスト曲線が適切である場合にのみ動きます。こうすることで、後々の摩擦を回避し、ツール・ランドスケープをスリムに保つことができる。結局のところ、重要なのは、そのツールが私の次のような要求に応えてくれるかどうかである。 チーム より速く エラー引用プレス
自動アラートの設定
アラームの信頼性を維持するために、私は勘ではなくSLOに基づいてしきい値を定義している。P95のレイテンシー、エラー率、キューの長さは最初のガードレールとして適している。すべてのシグナルにはエスカレーションパスが必要です:チャット、電話、そして明確な所有権を持つインシデントチケットです。時間ベースの抑制は、計画的な配備中にアラームが殺到するのを防ぐ。新しいチームメンバーが自信を持って行動できるように、私は基準と責任を文書化しています。 準備 ない アラーム疲れ を傾ける。
インシデントへの備え:ランブック、ドリル、事後調査
私はランブックを小説ではなく、短い決定木のように考えている。良いアラームは、診断ステップ、チェックリスト、ロールバック・オプションにリンクしている。私はドライランやゲームデーでエスカレーションの練習をし、実際のケースでもチームが冷静でいられるようにしている。インシデントが発生した後は、責任を問わない事後報告を書き、オーナーと期日を定めた具体的な対策を定義し、ロードマップに定着させる。私はMTTA/MTTRとアラームの精度(真陽性/偽陽性)を測定し、自分の改善がうまくいっているかどうかを認識できるようにしている。
日常生活で機能する統合
私は重要なアラートをSlackやメールに転送し、優先度が高い場合は電話も使って、誰もイベントを見逃さないようにしている。チケットの統合により、アラートからコンテキストを持つタスクが自動的に作成されるようにしています。私は、アクションステップを提案するランブックとWebhookを接続し、さらには修復をトリガーします。優れた統合は、MTTAとMTTRを顕著に短縮し、神経を落ち着かせる。特に夜間に重要なのは、プロセスが効果的であること、役割が明確であること、そして アクション よりも速い。 不確実性.
症状から原因へ:APM + ログ
私は、アプリケーション・パフォーマンス・モニタリング(APM)とログの相関を組み合わせて、強調表示されたエラー・パスを確認している。トレースはどのサービスがスローダウンしているかを示し、ログは例外の詳細を提供する。これにより、N+1クエリ、低速のサードパーティAPI、または欠陥のあるキャッシュを、暗闇の中で探ることなく明らかにすることができます。サンプリングは対象を絞って行うので、コストは手頃なまま、ホットパスは完全に可視化される。このカップリングによって、私は的を絞った方法で修正を設定し、リリースのテンポを守り、次のような効果を上げている。 品質 より少なく ストレス.

カウントするDB、キャッシュ、キューのシグナル
データベースについては、CPUだけでなく、コネクションプールの利用率、ロック待ち時間、レプリケーションの遅延、最も遅いクエリの割合も監視している。キャッシュについては、ヒット率、退去、リフィル・レイテンシー、陳腐化したリードの割合に関心があります。ヒット率が低下すると、データベースに雪崩のような影響が出る危険性があります。キューについては、バックログ年齢、コンシューマー・ラグ、コンシューマーあたりのスループット、デッドレター率に注目しています。JVM/.NET側では、GCポーズ、ヒープ利用率、スレッドプール飽和度を測定し、ヘッドルームを正直に確認できるようにしている。
実践的なプレイブックモニタリング開始から30日間
週目には、目標、SLO、メトリクスを明確にし、基本的なダッシュボードを設定し、トップサービスを記録する。2週目には、ログパイプラインを有効化し、フィールドを正規化し、最初のアラートを設定する。3週目には、しきい値を修正し、ランブックをリンクさせ、ドライランでエスカレーションをテストする。4週目には、リテンション・プロファイルでコストを最適化し、ダッシュボードの理解度をチェックする。最終的な結果は、明確なプレイブック、信頼できるアラーム、そして測定可能なものである。 改善点で持っている チーム の部品だ。
キャパシティ・プランニングと回復力テスト
私は直感ではなく、トレンド、SLO消費量、負荷プロファイルに基づいてキャパシティを計画する。実際のユーザーフローからのトラフィックリプレイは、ピークパターン下でシステムがどのように反応するかを示してくれる。コールドスタートが私を冷え込ませないように、ランプアップ時間とスケールバックアップ(最小/最大)で自動スケーリングをテストします。カナリアリリースとプログレッシブロールアウトでリスクを抑える。リリースごとのエラーバジェット消費を監視し、SLOがひっくり返ったらデプロイを止める。カオスとフェイルオーバーのドリルは、HAが希望的観測ではないことを証明する。
ホスティングプロバイダー選び:ホスティングプロバイダー選びのポイント
私は、契約上の可用性、サポートの応答時間、負荷がかかった状態での実際のパフォーマンスをチェックする。私にとって重要なのは、サーバーのレスポンスの速さ、ストレージのパフォーマンスの安定性、パッチの提供の速さです。webhoster.deのようなプロバイダーは、優れたパッケージと信頼性の高いインフラで得点を稼いでおり、プロジェクトの安全性が際立っています。私は、透明性のあるステータスページ、明確なメンテナンスウィンドウ、意味のあるメトリクスを求めます。これらのポイントを満たせば、リスクを減らし、プロジェクトの安全性を高めることができます。 モニタリング を保護する。 予算.

エッジ、DNS、証明書が一目でわかる
オリジンだけでなく、エッジも監視している:CDNキャッシュのヒット率、オリジンのフォールバック、HTTPの状態分布、POPごとのレイテンシー。DNSのチェックは複数のリージョンから行い、NSの健全性、TTL、再帰エラー率をチェックしている。TLS証明書の有効期限を早め(30日/14日/7日前にアラーム)、暗号スイートとハンドシェイク時間を監視する。シンセティック・ジャーニーは重要なユーザー・パス(ログイン、チェックアウト、検索)をマッピングし、RUMは実際のエンド・デバイス、ネットワーク、ブラウザーのバリエーションを示してくれる。これらの両方が一緒になって外部からの視点を表し、サーバー・メトリクスをうまく補完しています。
アップタイム、SLO、予算
可用性を内部だけでなく外部のチェックで測定し、実際のユーザー経路をマッピングできるようにしている。測定ポイントのないサービスレベル目標はアサーションのままなので、私はSLOと独立したチェックを組み合わせている。次のような比較 アップタイム監視カバレッジ、間隔、コストを迅速に評価するためです。私は、コストが予測可能であるように、GB ログごと、ホストごと、チェック間隔ごとに予算を計画している。SLO のエラーを可視化し、ロードマップをクリーンに議論し、勝利する者 バッキング すべての 優先順位付け.

データパイプラインとコンテキスト:遠隔測定をきれいにつなぐ
trace_idとspan_idがログに残っているので、エラーログからトレースに直接ジャンプできる。デプロイイベント、機能フラグ、設定変更を個別のイベントとして記録し、グラフ上の相関オーバーレイで、変更がメトリクスに影響するかどうかを示す。私はラベルの衛生に注意を払っています。明確な名前空間、一貫したキー、無秩序な増加を防ぐためのハードリミットです。テールベースのサンプリングは異常なスパンを優先し、ヘッドベースのサンプリングは負荷を軽減する。これにより、洞察は鋭くなり、コストは安定する。
オンコールの人間工学とチームの健康
私は、すべてのスパイクがあなたを起こさないように、重要度に応じてアラームを構成しています。イベントの要約(グループ化)と静粛時間は、リスクを増やすことなくノイズを減らす。ローテーションは公平に配分され、引き継ぎは文書化され、バックアップは明確に指名される。アラーム疲れを防ぐため、一人当たりのポケベル負荷、誤報率、夜間介入率を測定している。訓練された応急処置の手順(ファーストレスポンダー・プレイブック)が安全を提供し、より詳細な分析は状況が安定してから行う。こうすることで、即応態勢は持続し、チームは回復力を保つことができる。
セキュリティとコンプライアンス信号の統合
ログイン率の異常、異常なIPクラスタ、4xx/5xxパターン、WAF/監査ログがダッシュボードに流れてきます。私は一貫してPIIをマスクし、診断に必要なものだけを見えるようにしています。監査証跡は機密データのクエリを文書化します。これにより、運用スピードを落とすことなく、セキュリティ、診断、コンプライアンスのバランスを保っている。
簡単な要約
私は、モニタリングが日常的に機能するよう、無駄がなく、測定可能で、行動指向であるよう心がけています。中核となるメトリクス、一元化されたログ、明確なアラートにより、診断と対応のスピードが向上しました。集中的なツール・スタックにより、私は洞察を犠牲にすることなくコストを削減しています。統合、プレイブック、SLOは、インシデント作業をより円滑にし、追跡可能にします。つまり、ホスティング・パフォーマンス・モニタリングはそれ自体が目的ではなく、次のようなものなのです。 レバー より良い 空室状況 そして安定したユーザー・ジャーニー。


