
を作る方法を紹介しよう。 サーバーの応答時間分析 TTFB、TTI、FCP、LCPが単なる測定ノイズではなく、真の情報を提供するように。そうすることで しきい値 現実的に、原因を正しく分類し、ロード時間とインタラクティブ性を顕著に改善する対策を導き出す。
中心点
以下の重要な記述は、優先順位を明確に設定し、結果を確実に解釈するのに役立つ。
- TTFBサーバー性能のための開始信号、通常600ミリ秒以下が目標
- TTI目に見えるコンテンツだけでなく、双方向性が重要
- 原因レイテンシー、サーバー負荷、データベース、スクリプト、プラグイン
- ツールPSI、Lighthouse、文脈を読むWebPageTest
- ホスティングスタック、キャッシュ、CDN、ロケーションの決定

TTFBは何を測定しているのか?
TTFBはリクエストから始まり、ブラウザがサーバーから受け取る最初のバイトで終わる。 タイムスパン 孤立していない。この数字には、DNS解決、TCPハンドシェイク、TLS、サーバー処理、最初のバイトの送信が含まれる。 チェーン 最終的な値だけでなく、ステップの値も確認すること。経験則として、TTFBが一貫して約600ミリ秒以下であれば、サーバーのレスポンスは通常良い一致です。私は個々の異常値を、一連の遅いレスポンスとは異なる方法で評価します。綿密な分析を避けるのではなく、クライアントからオリジンまでのパスをセクションに分け、ログ、CDN統計、ホスティングモニタリングと比較します。計測のセットアップと落とし穴については、コンパクトなガイドを参照してください。 TTFBを正しく測定する典型的なエラーの原因を明確に示している。
TTIがわかりやすく説明:レンダリングだけでなくインタラクティブ性を実現
TTIは、ユーザーが遅延なく入力を実行できる時間を表す。 インタラクティブ 目に見える構造から厳密に分離されています。ボタンが使えない高速FCPは、長いタスクがメインスレッドをブロックしてクリックが止まってしまうなら、ほとんど意味がない。 応答行動 を入力する。長いJavaScriptタスク、レンダリングをブロックするアセット、余計なサードパーティ製スクリプトは、TTIを著しく長くする。私はスクリプトを分割し、クリティカルでないタスクを非同期でロードしたり、重いジョブを最初のインタラクションの後ろに移動させたりしている。こうすることで、個々のアセットのロードが続いても、ページがより速くなり、より快適に使えるようになる。
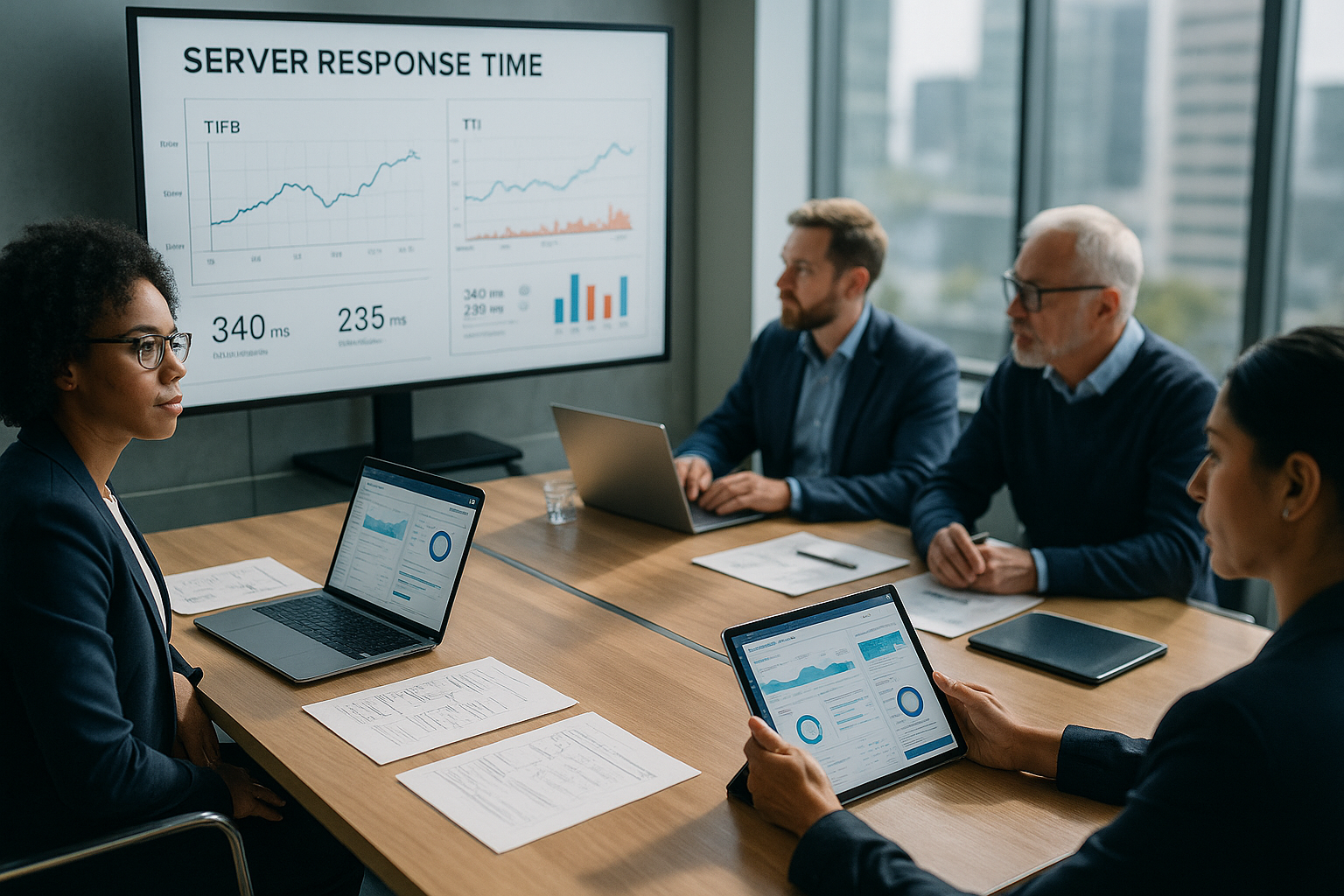
TTFB、FCP、LCP、TTIの相互作用
TTFBが高いと、FCPとLCPは自動的に遅延する。 レンダー 重要なスクリプトの準備が遅れている場合、TTIも抑制される。TTFBが一時的に上がっても、FCPとLCPの遅れは続く。FCPとLCPがしっかりしているにもかかわらず、TTIが遅れている場合、問題は通常 JavaScript そしてスレッドの利用。WordPressでは、ページビルダー、たくさんのプラグイン、凝ったテーマがしばしば重いバンドルにつながる。依存関係が明確になって初めて、私は症状を治すのではなく、適切な対策を講じるのです。
フィールドデータとラボデータ:実際の使用と合成テストを比較する
とは厳密に区別している。 ラボデータ (管理された環境、再現性)と フィールドデータ (実際のユーザー、実際のデバイス、ネットワーク)。意思決定のために、私はフィールド測定からのP75値をカウントする。なぜなら、それらは異常値を平滑化し、典型的なユーザーエクスペリエンスに対応するからである。また、デバイスの種類(ローエンドのアンドロイドとハイエンドのデスクトップ)、地域、ネットワークの品質によってセグメント化します。私はラボのデータを次のように使用しています。 原因 現場データは、最適化が全体的に有効かどうかを示す。私は個々の値ではなく時系列を比較し、時間帯(負荷のピーク)、リリース時間、季節的影響をチェックする。また 冷たい そして 暖かい キャッシュ:キャッシュの状態が同一でない場合のA/B比較は、特にTTFBとLCPにおいて誤った結論を導く。
診断:数秒でボトルネックを見つける方法
デスクトップとモバイルで再現性のある測定を行い、ネットワークプロファイルを変化させ、次のような分析を行う。 滝 結論を出す前に。それから、サーバーのログ、キャッシュヒット、CPUとI/Oの負荷、データベースの潜在的なロックの問題をチェックします。フロントエンドの診断では、直感に頼るのではなく、ライトハウス・トレースとWebPageTestのビデオを使って障害を視覚化します。一貫性のあるダッシュボードは、スナップショットではなく傾向を見るのに役立ちます。 PSIとライトハウスこれは、測定環境と測定基準を明確に分けている。この組み合わせにより、ネットワーク、サーバー、スクリプトのどれが待ち時間の大半を占めているのかがすぐにわかり、後で時間を大幅に節約できる。

サーバーのタイミングとトレース:見えない部分を測定可能にする
TTFBがブラックボックスにならないように、私は次のようにしている。 サーバータイミング-ヘッダーを作成し、アプリケーション・ログと関連付ける。これにより、ルーティング、テンプレート化、キャッシュ・ミス、データベース・クエリ、外部API、レンダリングのシェアを見ることができる。ネットワーク・レベルでは、DNS、TCP、TLS、リクエスト・キューイングを分離している。TLSの時間が変動している場合は、セッション再開の不足や、暗号/OCSPのステープリングが最適でないことを示すことが多い。また コネクションの再利用 HTTP/2/3では、不要なハンドシェイクがレイテンシの連鎖を伸ばすからだ。トレースでは、"のこぎり歯 "パターン(キャッシュ状態の変化)、デプロイ後のレイテンシジャンプ(オペキャッシュのコールドスタート)、バックエンドのN+1クエリなどを確認することができる。この透明性によって、間違ったエンドでの最適化を防ぐことができる。
応答時間が長くなる一般的な原因
CPUやRAMが少なすぎる過負荷のマシンは、TTFBを悪化させる。 利用 ピーク時と変動するレイテンシー。非効率なデータベースクエリはサーバー処理を長引かせる。私はクエリログとインデックスチェックでこれを記録し、最適化やキャッシュによって解決する。大きなスクリプトやクリティカルでないスクリプトが早期にロードされると、レンダリングパスがブロックされ、人為的なレイテンシが発生する。 フェーズ ドロー。適切なキャッシュのない高トラフィックはリソースを消耗し、CDNが近くにない場合はレイテンシーが著しく増加する。応答が非常に遅いサードパーティの呼び出しもTTIを消耗させるが、タイムアウト戦略と遅延ロードで軽減している。
ホスティング戦略:高速スタックが提供すべきもの
私は、NGINXや最新のHTTPスタック、最新のPHPバージョン、OPCache、オブジェクトキャッシング、Brotli、TLS 1.3、そして、以下のものに注意を払っています。 シーディーエヌ-これらのコンポーネントがTTFBとTTIを大きく形成するからだ。WordPressは、サーバーサイドのキャッシュと賢明なデータベースとRedisの設定から大きな恩恵を受けている。さらに、高いIOPSを持つクリーンなストレージがあるため、メディアやキャッシュファイルがもたつくことはありません。 応答時間.比較すると、最適化されたWordPressスタックは、一般的な共有パッケージよりも常に優れたパフォーマンスを発揮します。その結果、負荷がかかっても短いレスポンスタイムを実現し、同時に信頼性を維持するセットアップが可能になります。
| プロバイダ | サーバー応答時間(TTFB) | パフォーマンス | ワードプレスの最適化 |
|---|---|---|---|
| webhoster.de | 1(テスト勝者) | 非常に高い | 素晴らしい |
| その他のプロバイダー | 2-5 | 可変 | 中~良 |

キャッシュ戦略の詳細キャッシュ・アーキテクチャを弾力的にする
私はキャッシュキー(言語、デバイス、通貨、ログイン状態を含む)を意識的にデザインし、不必要なキャッシュキーは避けている。 可変-クッキーとヘッダーによる爆発。可能な限り キャッシュ・コントロール 常識的なTTLで、 有効期限切れ そして もしエラーなら 負荷のピークやブリッジの停止を吸収するためです。Originがいずれにせよ計算しなければならないのであれば、バリデーションはハードヒットよりも利点がないことがよくあります。動的なページでは、私は次のようにしています。 穴あけ (ESI/フラグメントキャッシュ)の95%のドキュメントがキャッシュから出てきて、パーソナライズされたブロックだけが新しくレンダリングされる。私はサロゲート・キーを使ってパージ処理を制御し、ゾーン全体をフラッシュするのではなく、特に無効化するようにしています。ウォームキャッシュについては、次のように計画しています。 プレウォーミング-最初のユーザーがコールドスタート費用を全額負担しないようにするためである。
即効性のある具体的なTTFBの最適化
TTLを考慮したフルページ・キャッシングを有効にし、動的な部分にはホール・パンチにします。 キャッシュ-ヒット率はサーバーの負荷を軽減します。エッジ・キャッシュを備えたCDNは、距離を短縮し、特に国際的な視聴者の待ち時間のピークを最小限に抑えます。ハードウェアを拡張する前に、インデックス、プリペアドステートメント、クエリーリファクタリングを使ってデータベースクエリーを最適化する。 スリム.PHPの時間を節約するために、重いプラグインを入れ替えたり、イコライズしたりする。また、距離も重要なので、ロケーションとルーティングもチェックする:その背景については、以下のガイドにまとめている。 サーバーの場所とレイテンシー コンパクトにまとめられている。
TTIの代わりにINP:現場での双方向性をどう評価するか
研究室でTTIを使うとしても、私は現場で次のような方向付けをする。 インピー (インタラクション・トゥ・ネクスト・ペイント)。INPは、1回の訪問で最も長いインタラクションを測定するもので、TTIよりも顕著なハングをより明確に表す。実際、私の目標値は200ミリ秒以下です(P75)。これを達成するために、イベントハンドラを短くし、同期的なレイアウトのスラッシュを避け、高価な計算を分割し、以下の作業を延期する。 ウェブワーカー可能であれば。データクエリからレンダリングを切り離し、楽観的なUIを表示し、長時間実行タスクでメインスレッドのループをブロックしない。フレームワークをコード分割と 島-のアプローチにより、ページ全体を一度に潤す必要がなくなった。結果:ボタンが直接反応し、入力が「飲み込まれる」ことがなくなり、知覚速度が向上した。
TTIの削減:レンダーブロックと長いタスクの排除
私は重要なCSSを最低限に減らし、残りは遅延属性かメディア属性で読み込んでいる。 JS をパスからdefer/asyncすることで、メインスレッドがフリーな状態を維持できる。長いタスクは分割して、50ミリ秒以上のブロックがないようにしている。サードパーティーのスクリプトは、インタラクションの後か、パフォーマンス予算によってのみロードし、不必要にTTIを伸ばさないようにしています。クライアントのCPU負荷を軽減し、ネットワーク転送を短くするため、サーバー側で画像のサイズを縮小し、最新のフォーマットで配信しています。重要なAPIコールをキャッシュし、UIが外部サービスを待つことがないようにしています。

フロントエンドの優先順位付け:最初に何が起こるかをコントロールする
をセットした。 プリロード LCPリソースに特化するには フェッチプライオリティ ブラインド・プリロードの代わりに、優先順位ヒンティングを使用し、現実的な定義が可能です。 資源予算.私は重要なフォントをスリムにロードする。 フォント表示:スワップテキストがすぐに見えるように。 プリコネクト パイプラインを詰まらせることなく事前にハンドシェイクを引き出すために、やむを得ないサードパーティプロバイダーには控えめに使っている。画像については、私はクリーンな サイズ-属性、コンパクト ソースセット-チェーンと decoding="async"メインスレッドが空くように。こうすることで、帯域幅とCPUを、ユーザーが最初に見たいもの、使いたいものに振り向けることができる。
測定ミスを避けるデータを正しく解釈する方法
CDNヒット、DNSキャッシュ、ブラウザのキャッシュが測定するためです。 偽る ができます。コールドスタート、空のキャッシュ、デプロイ後の最初のリクエストは、ウォームフェーズとは別に評価する。私の場合、単発のテストは大まかな指標としてしか役に立ちません。 構成.地域、プロキシ、ピアリング・パスは重要な役割を果たします。そのため、私はローカルでテストするだけでなく、ユーザーの近くに測定ポイントを設定しています。測定環境、測定基準、ターゲットが明確に定義されて初めて、私は経時的な数値を比較し、信頼できるベンチマークを設定することができます。
WordPressに特化したディープ・オプティマイゼーション:私はまず最大のブレーキを取り除く
私はまず プラグイン/テーマの監査 と重複を削除する。オートロードのオプション wp_options 各リクエストが不必要な量のバラストをロードしないように、無駄のないようにしている。ページが呼び出されたときに計算されないように、トランジェントを永続オブジェクトキャッシュ(Redisなど)に移行する。データベースレベルでは ポストメタ そして オプションN+1クエリを削除し、メニュー、クエリ、フラグメント結果のキャッシュを設定する。その結果 WP-クーロン サーバー側でこれを計画し、ユーザーが起動したときにジョブがランダムに起動しないようにしています。私は、サーバーサイド・レンダリングによってページ・ビルダーを最適化します。 パーシャル-テンプレートとメディア・ギャラリーの一貫した延期。その結果、PHPの実行時間が短縮され、クエリが減り、TTFBがより安定しました。
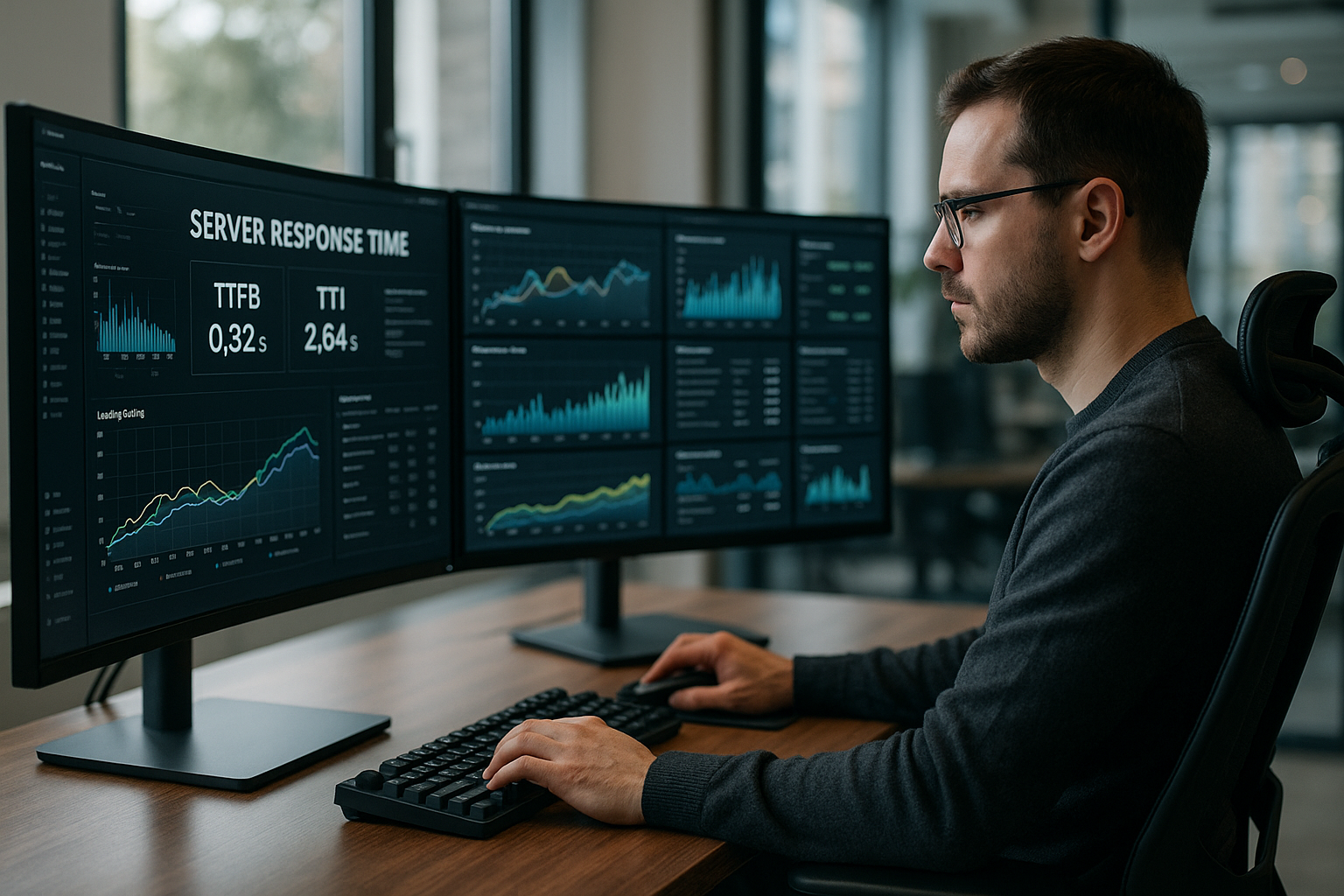
バックエンドとプロトコル:最新のトランスポート・ルートを利用している。
パケットロスやモバイルネットワークでより安定したパフォーマンスを得るためにHTTP/3 (QUIC)を有効にし、TLSセッションの再開を確認し、次のように設定します。 初期のヒント (103)LCPアセットを早めに開始するためです。サーバー側では、HTML ストリーミング そして、処理完了後にすべてを出力するのではなく、重要な折り畳み以上の構造を早期にフラッシュする。レイテンシーとスループットがバランスするように、出力バッファリングと圧縮レベルを選択する。バックエンドでは、opcacheを暖かく保ち、PHPに特定のJIT設定を使い、マシンがスワッピングに陥らないように同時ワーカーの制限を設定する。外部サービスはキューとキャッシュで切り離し、サードパーティのAPIを待たせるようなリクエストを出さないようにしている。
継続的な測定、レポート、SEO効果
私は業績予算を設定し、変動に対するアラートをチェックし、ダッシュボードに指標を記録することで、チームが迅速に対応できるようにしています。 反応.定期的にチェックすることで、アップデートや新しいプラグイン、広告スクリプトがTTFB、FCP、LCP、TTIを動かしているかどうかがわかる。Googleはローディング時間をランキングシグナルとして評価しており、過度のレスポンスタイムは視認性とコンバージョンを著しく低下させます。TTFBについては、600ミリ秒以下のしきい値を現実的な目標としていますが、デバイス、地域、コンテンツの種類によって調整し、ステートメントが有効であるようにしています。明確な指標を持つ透明性の高いレポートは、合理的な方法でバックログに優先順位をつける根拠となります。
SLI、SLO、ワークフロー:パフォーマンスをチームタスクにする
私はサービスレベル指標(P75-LCP、P95-TTFB、エラー率など)を定義し、以下のことに同意する。 SLO ページタイプごとに。私は段階的に変更を展開し、相関関係が見えるようにダッシュボードにタグを付ける。個々の値に対してアラートを発するのではなく、傾向や予算違反に対してアラートを発する。典型的なエラー・パターン(キャッシュ・クラッシュ、DBロックの増加、サードパーティのタイムアウトなど)のプレイブックを文書化し、インシデント発生時にチームが迅速に対応できるようにしている。このような規律により、良好なフェーズの後にパフォーマンスが再び「低下」することを防ぎ、プロフェッショナルとしても組織としても、最適化を持続可能なものにしています。
要約:サーバーの応答時間を分析する方法
私は次のように始める。 TTFBDNSから最初のバイトまでのチェーン全体をチェックし、測定値をログや負荷プロファイルと比較します。そして、レンダー・ブロッキングを除去し、長いタスクを分割し、サードパーティのコードを調整することで、TTIを確保します。距離、I/O、処理が調和し、負荷のピークがスムーズに吸収されるように、ホスティング、キャッシュ、CDNを的を絞った方法で組み合わせる。ツールはヒントを与えてくれますが、最終的には一貫性が重要なので、再現可能なシリーズと明確な測定環境の後にのみ決定を下します。こうして私は、サーバーの応答時間、双方向性、視認性を、ユーザーにも検索エンジンにも感動を与える安定したレベルにまで高めているのです。


