 コンテンツにスキップ
コンテンツにスキップ 
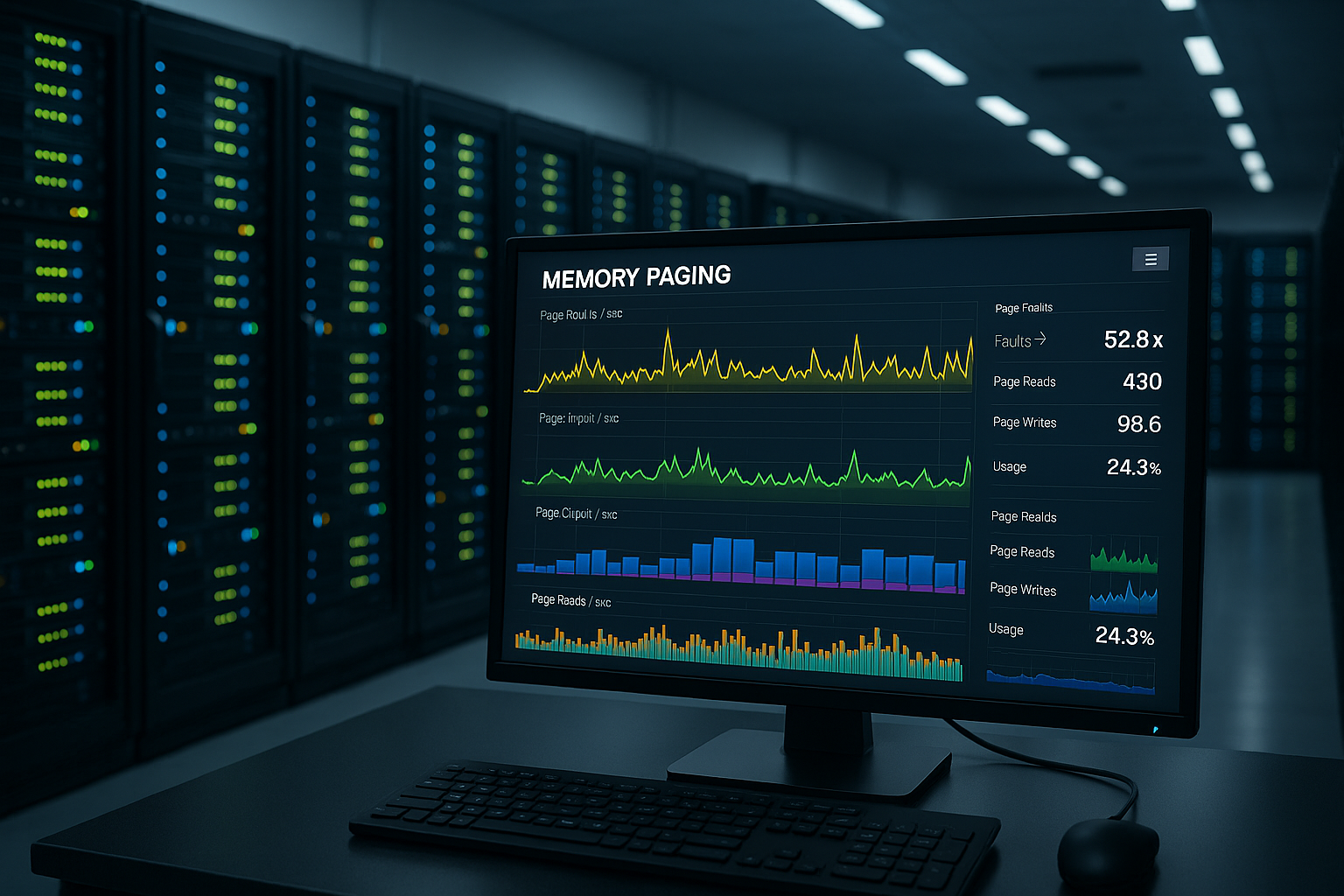
A メモリー・ページング・サーバー RAMからスワップに移動するページが多すぎると、負荷がかかったときにレスポンスタイムとスループットが著しく低下することがあります。この記事では、ページングを遅くしてサーバーのパフォーマンスを顕著に向上させるための原因、測定値、具体的な調整方法を紹介する。.
中心点
明確な方向性を示すために、重要なメッセージを簡単に要約し、典型的なボトルネックがどこにあり、どのように解決するかを紹介する。高いページングレートは大きなコスト パフォーマンス, データキャリアのアクセスはRAMよりはるかに遅いからだ。利用可能MBytes、アクセスされたBytes、Pages/Secondのような測定値は、私に信頼できる情報を与えてくれる。 信号 スラッシングが迫っているためである。仮想化は、ホストがオーバーブッキングしている場合、バルーニングやハイパーバイザーのスワップによってスワッピング効果を悪化させる。私は、RAMのアップグレード、THP/巨大ページ、NUMAチューニング、クリーンなアロケーションパターンでページフォールトを減らしています。定期的なモニタリングで リスク そして、負荷のピークを計算可能にする。.
- スワップとRAMの比較RAMのナノ秒とデータキャリアのマイクロ/ミリ秒の比較
- スラッシング有用な作業よりもページ転送が多く、レイテンシが爆発的に増加
- フラグメンテーションメモリが „解放 “されているにもかかわらず、大きな割り当てに失敗する。
- 指標利用可能MBytes、アクセスされたバイト、ページ/秒。.
- チューニングTHP/巨大ページ、vm.min_free_kbytes、NUMA、RAM

サーバーでのページングの仕組み
私は、仮想メモリと物理メモリを固定ページ(通常は4KB)に分けている。 エムエムユー ページ・テーブルを経由する。RAMが不足すると、オペレーティング・システムは非アクティブなページをスワップまたはスワップ領域に移動させる。ページフォールトが発生するたびに、カーネルはデータキャリアからデータをフェッチしなければならず、貴重なRAMを消費する。 時間. .THP(Transparent Huge Pages)のような大きなページは、管理者の労力を軽減し、TLBのミスを最小限に抑える。初心者には 仮想メモリ, プロセス、ページフレーム、スワップの関係をよりよく理解するために。.
スワップとRAMの比較:レイテンシーとスラッシング
RAMがナノ秒単位で反応するのに対し、SSD/HDDはマイクロ秒からミリ秒単位で反応するため、桁違いに速い。 低調 である。負荷が物理的な作業メモリを超えると、ページング速度が上がり、CPUはI/Oを待つことになる。この影響はスラッシングにつながりやすく、生産的な作業よりもスワッピングに多くの時間が費やされることになる。 労働 が失われる。特に80-90%を使用すると、双方向性とリモート・セッションが悪化します。私は スワップ利用率 そして、システムがひっくり返る前に境界線を引く。.

指標としきい値
クリーンな測定値で意思決定 RAM とチューニング。Windowsでは、Available MBytes、cessed Bytes、Pages/Second、Pool paged/nonpaged bytesに注目している。Linux側では、vmstat、free、sar、ps meminfo、dmesgでメモリ不足のイベントをチェックする。MBytesの空き容量が減少するにつれてページの問題が増加している場合は、ボトルネックが差し迫っていることを示しています。クリティカルなしきい値を控えめに計画し、負荷のピークを回避できるようにしています。 強盗 迎撃する。.
| パフォーマンス指標 | 健康 | 警告 | クリティカル |
|---|---|---|---|
| \ページド・バイト/非ページド・バイト | 0-50% | 60-80% | 80-100% |
| 使用可能MBytes | >10%または4GB | <10% | <1%または<500MB |
| % 保存バイト数 | 0-50% | 60-80% | 80-100% |
Linux:スワップネス、Zswap/ZRAM、ライトバック・パラメーター
THP/巨大ページに加えて、スワッピングとライトバックのアグレッシブさをコントロールすることで、ページングを顕著に減らしている。. vm.swappiness は、カーネルがどの程度早い段階でページをスワップにプッシュするかを制御する。多くのRAMを搭載したサーバーでは、ページキャッシュが大きく保たれ、非アクティブなヒープが早期に移行しないように、私は通常1~10を使用する。非常に乏しいシステムでは、キャッシュが完全に枯渇しないため、少し高い値を設定することでインタラクティブ性を保つことができる。.
と一緒に ツースワップ (RAM内の圧縮スワップ)、短時間に大量のコールドページがある場合、I/Oプレッシャーを軽減する。これにはCPUサイクルがかかるが、ブロックI/Oよりは安いことが多い。エッジやラボのシステムには ZRAM 小規模ホストをより堅牢にするための主要なスワップとして。本番では、CPUのヘッドルームに余裕があるときに、的を絞った方法で使っている。.
パスの書き込みは vm.dirty_*-パラメータで指定します。パーセンテージ値ではなく、絶対バイト数で作業する方が、RAM容量が大きくてもライトバックの嵐を避けられる。バックグラウンド・フラッシュは十分に早い段階で開始される。 ダーティバイト は、遅延ワークロードに対する厳しい上限値を設定します。私が出発点として使用している値の例:
#によるスワップ抑制
sysctl -w vm.swappiness=10
# ライトバックをチェック(パーセントではなくバイト)
sysctl -w vm.dirty_background_bytes=67108864 # 64 MB
sysctl -w vm.dirty_bytes=268435456 # 256 MB
# VFSキャッシュを積極的に破棄しない
sysctl -w vm.vfs_cache_pressure=50
時点では スワップデザイン 私は高速なNVMeデバイスを好み、カーネルが最も高速なスワップを最初に使うように優先順位を設定する。専用のスワップ・デバイスは、スワップ・ファイルの断片化を防ぎます。.
# スワップの優先順位をチェックする
swapon --show
優先順位の高い高速デバイスで#スワップを有効にする。
swapon -p 100 /dev/nvme0n1p3
重要 重大/軽微な故障 I/Oキューの深さを並列で確認することで、スワッピーの減少やZswapが実際のレイテンシーのピークを平滑化しているかどうかを確認することができる。.
ページングレートが高くなる原因
物理的なワーキングメモリがない場合は、内蔵メモリ経由でアクセスバイトが増える。 RAM となり、スワップに切り替わる。断片化されたメモリは大規模な割り当てを困難にするため、アプリケーションは „空き “RAMにもかかわらずブロックする。不十分なクエリやインデックスの欠落は、データアクセスを不必要に増加させ、作業負荷を増大させる。バックアップ、デプロイメント、ETL、クーロン・ジョブによるピーク負荷は、メモリ要件を短い時間ウィンドウに束ねる。仮想マシンは、ホストがRAMをオーバーブッキングしたり、ハイパーバイザーのスワップを密かに実行したりすることで、さらなるプレッシャーにさらされます。 アクティベート.
仮想化、バルーン化、オーバーコミットメント
仮想化環境では、ハイパーバイザーは実際のRAMの状況を隠蔽し、バルーンとスワッピングに頼っている。 ゲスト. .ホストがボトルネックに陥った場合、VMはそれぞれが「グリーン」であるにもかかわらず、同時にパフォーマンスを失う。起動中のスマート・ページングはコールドスタートを隠しますが、コストはI/Oパイプラインにシフトします。ホストとゲストのメトリクスを一緒にチェックし、ユーザーが気付く前にオーバーコミットを減らします。オーバーコミットの効果の詳細については、以下のセクションで説明します。 メモリのオーバーコミットメント, そうすることで、キャパシティ・プランニングは弾力性を保つことができる。.
コンテナとKubernetes:cgroups、制限と立ち退き
コンテナは、ストレージの制限をVMから cgroups. .決定的なのは リクエスト そして 制限 は現実的に設定される:厳しすぎる制限は早期のメモリ不足キルを引き起こし、寛大すぎる要求は利用率を悪化させ、リザーブを装う。私は、JVM/Node/.NETからのヒープを一貫してコンテナの制限(例えばパーセンテージのヒューリスティック)に縛り付けておき、ランタイムのGCがcgroupにぶつからないようにしている。.
Kubernetesでは、QoSクラス(Guaranteed、Burstable、BestEffort)に注意しています。 立ち退き をノードレベルで使用する。メモリ・プレッシャーがかかると、KubeletはBestEffortポッドを優先する。SLOを維持したければ、リソースを適切に予算化しなければならない。. 生販在 (圧力失速情報)はcgroup-localの圧力を可視化する。私はこれらのシグナルを使って、ポッドをプロアクティブにスケールしたり、スケジュールを変更したりする。ページ数の多いワークロードでは、ポッドごとに明示的にHugePageリクエストを定義して、スケジューラが適切なノードを選択するようにしています。.
最適化戦略ハードウェアとOS
最も地味な調整ネジから始めよう。 RAM 多くの場合、最大のレイテンシはすぐに解消される。並行して、レイテンシプロファイルが許せば、„on “または „madvise “モードのTHPでページフォールトを減らす。予約された巨大なページは、インメモリエンジンに予測可能性を提供しますが、正確なキャパシティプランニングが必要です。vm.min_free_kbytesを使用することで、コンパクションを補うことなく、アロケーションのピークに対処するための賢明なリザーブを作成します。ファームウェアとカーネルのアップデートは、エッジエラーを排除し、メモリ管理と NUMA-バランス。.
| セッティング | ゴール | ベネフィット | ヒント |
|---|---|---|---|
| vm.min_free_kバイト | 配分のピークに備える | OOM/コンパクションの減少 | RAMの5-10% |
| THPについて | 大きなページを使う | 断片化の減少 | 待ち時間の観測 |
| 巨大なページ | 連続ブロック | 予測可能な配分 | しっかりとした予備能力 |
データベースとホスティング・ワークロード
バッファーキャッシュが縮小し、クエリがスワップインによって実行されると、データベースはすぐにダメージを受ける。 入出力 を溺死させる。ハード的に制限された最大メモリ設定により、SQL/NoSQLはファイルシステムのキャッシュとの相互置換から保護されます。インデックス、サーガビリティ、カスタマイズされた結合ストラテジーは、ワークロードを減らし、RAMへの負担を軽減する。ホスティングのセットアップでは、負荷プロファイルが衝突しないように、ピーク時に検索インデックス、キャッシュ、PHP FPMワーカーを計画する。バッファとページの寿命を監視することで、次のことを早期に警告してくれる。 下降トレンド.

練習:測定計画と調整スケジュール
私は、日々のパターンや仕事が見えるように、24時間から72時間のベースラインから始める。 になる. .それから、RAMヘッドの空き容量、許容ページ数/秒、最大I/O待ち時間の目標プロファイルを設定する。最初に制限、次にTHP/巨大ページ、最後に容量というように、段階的に変更を加えていく。同じ方法で、少なくとも1回の負荷サイクルにわたって各変更を測定します。悪影響が出た場合に迅速に対応できるよう、事前にキャンセルと分解を計画しています。 リダイレクト.
再現可能な負荷試験と能力予測
信頼できる判断のために、典型的な作業セットを再現する:キャッシュのウォーム/コールド、バッチウィンドウ、ログイン/チェックアウトのピーク。合成ツール(メモリーパスにはstress-ng、I/Oにはfio、キャッシュタイプにはmemcached/Redisベンチマークなど)を使って、特にメモリープレッシャーをシミュレートする。アプリのみ、アプリ+コ・ランナー(バックアップ、AVスキャン)、アプリ+I/Oピーク。これにより、アプリのみのテストでは隠れたままになっている干渉を認識することができる。.
それぞれの変更について、同一の測定パネル(メモリ、PSI、I/Oウェイト、CPUスティール/レディ、フォールト)を収集する。5-10%トラフィックを使ったカナリア・ロールアウトは、コンフィギュレーションを広く展開する前に、早期にリスクを発見する。キャパシティについては、平滑化された平均値ではなく、ワーストケースの作業セットと予備で計画を立てる。.
トラブルシューティング:ツールとサイン
Linuxでは、vmstat、sar、iostat、perf、straceが最も重要な情報を提供してくれる。 備考 ページフォールト、待ち時間、ヒープについて。Windows側では、パフォーマンスモニター、リソースモニター、ETWのトレースを頼りにしている。compaction stalls」、「kswapd high CPU」、「OOM kills」などのメッセージは、深刻なボトルネックを示している。変動するインタラクティブ性、長いGCポーズ、増大するダーティページがその疑いを裏付けている。私はヒープダンプとメモリプロファイラを使って、リークや不適切なページを見つける。 割り当て.

Windows特有の練習:ページファイル、ワーキング・セット、ページド・プール
Windowsサーバーでは、十分なサイズの スワップファイル を高速なSSD上で使用し、「ページファイルなし」のセットアップを避けることができます。最小サイズを固定することで、ピーク時にシステムが予期せず縮小したりトリミングしたりするのを防ぎます。必要であれば、ページファイルを複数のボリュームに分散させ、次のことを守っています。 ハード障害/秒 とページド/ノンページドプールの利用状況である。.
メモリを大量に消費するサービスでは、特に次のようにする。 メモリ内のページをロックする (カーネルがワークロードを作業セットから押し出さないようにするためだ。同時に、システムが他の方法で枯渇しないように、アプリのキャッシュをきれいに制限している。障害が発生した場合、スタンバイ・リストをコントロールしながら切り詰めることで、短期的にインタラクティブ性を回復させることができます。.
また、省電力プランが「最大パフォーマンス」に設定されていること、最新のNIC/ストレージ・ドライバとファームウェアであることも重要だ。スケジューラーの癖や古いフィルター・ドライバは、驚くほどしばしばメモリとI/Oのピークを引き起こし、純粋なRAM不足と誤解されることがある。.
THP、NUMA、ページサイズを賢く使う
Transparent Huge PagesはTLB-Pressureを軽減するが、散発的なプロモーションはレイテンシ・スパイクを引き起こす可能性がある。 生成する. .厳密なSLOを持つワークロードの場合、私はしばしば „madvise “または固定巨大ページに頼る。NUMAバランシングは、スレッドとメモリがローカルのままであれば、マルチソケットシステムで効果を発揮する。私はサービスをNUMAノードに固定し、ローカルのミスレートを監視している。巨大ページはスループットを向上させるが、私は内部フラグメンテーションをチェックする。 あげる.
ファイルシステムのキャッシュ、mmap、I/Oパス
空き」メモリの大部分は ページキャッシュ. .私は、エンジンがOSのキャッシュ(バッファードI/O)を使うか、自分自身のキャッシュ(ダイレクトI/O)を使うかを意識的に決めている。ダブルキャッシュはRAMを浪費する。 先行-レイテンシー。ストリームワークロードの場合は、デバイスごとのリードアヘッドを増やすかもしれない。.
# 例: リードアヘッドを 256 セクタにする
blockdev --setra 256 /dev/nvme0n1
メモリ・マップI/O (ミマップ)はコピーを保存するが、ページキャッシュに圧力を移す。例外的に、重要なページを モック (またはmemlock ulimits)を使用して、再生によるジッターを回避している。.
メモリー・プレッシャーの緊急対策
- トップコンシューマ(ps/top/procdump)を特定し、必要に応じて再起動または再スケジュールする。.
- 一時的に同時実行(ワーカー/スレッド)をスロットルして、フォールトレートとライトバックを減らす。.
- ダーティー・リミットを短期的に縮小し、ライトバックの効果を早め、リザーブに余裕を持たせる。.
- コンテナのオーバーコミットに対しては、特定のポッドを退避させ、VMのリソースを一時的に引き上げるか、バルーニングを緩和する。.
- OOM戦略のチェック:systemd-oomd/earlyoomを有効にして、次のようにする。 cgroup-を実行し、„正しい “プロセスが最初に進むようにする。.
キャパシティ・プランニングとコスト
RAMにはコストがかかるが、度重なる故障は収益を圧迫する。 評判. .ウェブサーバーやデータベースサーバーの場合、私は通常、稀なピークをカバーするために20-30%の予備を計算する。追加で64GBのモジュールを180~280ユーロで購入すれば、常時消火するより早く償却できることが多い。クラウド環境では、オーバーブッキングを避け、負荷パターンに合わせて段階的にバッファを予約する。冷静なTCO計算は、レイテンシーの損害とオペレーターの時間を考慮するため、きれいなチャートよりも優れている。 価格.

簡単にまとめると
A メモリー・ページング・サーバー 十分なRAM、クリーンなTHP/巨大ページのセットアップ、現実的なオーバーコミットが最大のメリットだ。私は、利用可能MBytes、アクセス済みBytes、ページ/秒などの明確な指標を頼りにしています。バルーンやホストスワップが隠れたパフォーマンスを奪わないように、仮想化環境をダブルチェックしている。データベースは、定義されたキャッシュと制限を持つスワップから遠ざける。これらのステップを一貫して実行すれば、待ち時間を短縮し、スラッシングを防ぎ、そして パフォーマンス 負荷がピークに達しても安定している。.


