Pāriet uz saturu
Pāriet uz saturu 
Es paļaujos uz GPU hostings, lai darbinātu mākslīgā intelekta un ML slodzes tīmekļa mitināšanā bez sastrēgumiem. Tas ir veids, kā es izmantoju paralēli skaitļošanas jaudu, ievērojami saīsina apmācības laiku un nodrošina prognozējamas ekspluatācijas izmaksas.
Centrālie punkti
Pirms detalizētākas informācijas sniegšanas es apkopošu šādus galvenos aspektus.
- Power izmantojot GPU, ievērojami paātrina apmācību un secinājumu izdarīšanu.
- Mērogmaiņa pēc vajadzības nodrošina elastīgus projektu posmus.
- Izmaksas samazinās, izmantojot uz lietošanu balstītu rēķinu izrakstīšanu mākonī.
- Atbilstība tāpat kā GDPR aizsargā sensitīvus datus hostingā.
- Programmatūra-TensorFlow, PyTorch un Docker atbalsts ir obligāts.

Kas ir GPU hostings - un kāpēc tas pārspēj CPU konfigurācijas?
Es izmantoju GPU-Tas ir tāpēc, ka grafikas procesori vienlaicīgi aprēķina tūkstošiem pavedienu un tādējādi ievērojami ātrāk trenē mākslīgā intelekta modeļus. Klasiskie procesoru gadījumi ir spēcīgi secīgos uzdevumos, bet ML apmācības pamatā ir masveida paralēlisms. Mākslīgā intelekta slodzes mitināšanā ir svarīga katra apmācības laika minūte, un grafikas procesori ievērojami samazina šo laiku. Tas attiecas arī uz secinājumiem, piemēram, NLP, attēlu klasifikāciju vai valodas modeļiem. Mūsdienīgām tīmekļa lietojumprogrammām ar reāllaika prasībām GPU hostings Tas nozīmē reālu ātrumu un prognozējamību.
Es skaidri nošķīru apmācību, secinājumu izdarīšanu un datu sagatavošanu, jo resursu izmantošana ir atšķirīga. Apmācība pastāvīgi izmanto GPU kodolus un VRAM, savukārt secinājumi bieži tiek veikti pa daļām. Datu sagatavošana gūst labumu no ātras NVMe krātuves un augstas tīkla caurlaidspējas. Piemēroti serveru profili un tiem pielāgota izvietošana nodrošina labu izmantojumu. Šādā veidā es izvairos no pārmērīgas rezervēšanas un saglabāju Izmaksas kontrolē.
Infrastruktūra un atlases kritēriji: Ko es meklēju uzstādīšanā
Vispirms pārbaudu GPU-tipu un ģenerāciju, jo tam ir vislielākā ietekme uz izpildes laiku. Kritiskām ML un mākslīgā intelekta slodzēm atkarībā no budžeta es izmantoju NVIDIA H100, A100 vai RTX L40S. Projekti ar mazākiem modeļiem tīri tīri labi darbojas ar RTX sērijas iekārtām, taču tiem nepieciešama laba VRAM pārvaldība. Pēc tam izvērtēju datu glabāšanas ceļu: NVMe SSD, pietiekams RAM un 10 Gbit/s+ paātrina datu konveijeru. Ja cauruļvads ir pareizs, konfigurācija mērogojas ievērojami labāk nekā tīri CPU skursteņi.
Es paļaujos uz automātisko mērogošanu, kad darba slodzes svārstās, un izmantoju API kontrolētu nodrošināšanu. Pakalpojumu sniedzējs ar bezserveru arhitektūru ļauj ātri ieslēgt un izslēgt gadījumus. Man ir svarīga arī komplektētā programmatūra: Docker, CUDA, cuDNN un tādiem ietvariem kā TensorFlow un PyTorch jābūt gataviem tūlītējai lietošanai. Tas man palīdz sākt darbu GPU hostinga infrastruktūra kā trieciena barjeru. Reāllaika uzraudzība un uzticams Failover papildiniet iepakojumu.

Pakalpojumu sniedzēju salīdzinājums 2025: veiktspēja, darbības laiks un cenu struktūra
Es salīdzinu pakalpojumu sniedzējus pēc Power, SLA un cenu noteikšanas modeli, jo tas man palīdz vēlāk izvairīties no sastrēgumiem. Labs GPU paaudžu apvienojums palīdz uzsākt projektus pa posmiem. GDPR prasībām atbilstoši datu centri man sniedz drošību attiecībā uz sensitīviem datiem. 24/7 atbalsts ir obligāts, ja ražošana vai secinājumu izdarīšana apstājas. Man ir vajadzīgi arī pārredzami darbības laika, tīkla latentuma un datu glabāšanas caurlaidspējas rādītāji.
| Vieta | Nodrošinātājs | GPU veidi | Īpašās iezīmes | Darbības laiks | Cena/mēnesī |
|---|---|---|---|---|---|
| 1 | webhoster.de | NVIDIA RTX UN H100 | NVMe SSD, GDPR, 24/7 atbalsts, skala. | 99,99 % | no 129,99 € |
| 2 | Atlantic.Net | NVIDIA A100 UN L40S | HIPAA, VFX, ātra ieviešana | 99,98 % | no 170,00 € |
| 3 | Linode | NVIDIA RTX sērija | Kubernetes, elastīgi mērogojama | 99,97 % | no 140,00 € |
| 4 | Genesis Cloud | RTX 3080, HGX B200 | Zaļā elektroenerģija, automātiska mērogošana | 99,96 % | no 110,00 € |
| 5 | HostKey | GeForce 1080Ti | Globālā iestatīšana, pielāgotās konfigurācijas | 99,95 % | no 135,00 € |
Man patīk uzticēt sākuma līmeņa projektus RTX-un vajadzības gadījumā pārslēgties uz H100. Izmantotība joprojām ir noteicošais faktors: es izvairos no dīkstāves, apvienojot mācību logus. VFX vai renderēšanas saimniecībām es dodu priekšroku augstiem VRAM profiliem un lielai vietējai NVMe kešatmiņai. Ražošanas secinājumiem es dodu priekšroku darbspējas laikam un atiestatīšanas stratēģijām. Šādi es nodrošinu veiktspēju un Drošība stabils pat pie maksimālās slodzes.
Izmaksu modeļi un budžeta kontrole: kontrolēt skaitļus
Es aktīvi pārvaldu budžetu, plānojot darba slodzi un Vietne-līdzīgi piedāvājumi. Nekas tik ātri neiztērē naudu kā nekontrolēts GPU laiks, kas netiek izmantots. Tāpēc es izmantoju automātisko izslēgšanu, brīdinājumus par dīkstāvi un skaidras kvotas. Iknedēļas grafiks ar definētiem laika logiem ir lietderīgs atkārtotiem uzdevumiem. Es kontrolēju arī glabāšanas izmaksas, jo NVMe un momentuzņēmumu glabāšana summējas. ātri.
Aprēķinu kopējās īpašumtiesību izmaksas ar cauruļvada posmiem, nodošanu un atbalsta pakalpojumiem. Spēcīga atbalsta līnija ietaupa manu iekšējo laiku un samazina dīkstāves laiku. ML komandām es iesaku atsevišķi mērogot skaitļošanas un glabāšanas iekārtas. Tas samazina atkarības un atvieglo turpmākās izmaiņas. Prognozējamās uzturēšanas scenārijiem es atsaucos uz Prognozējamās tehniskās apkopes hostings, prognozējami pagarināt darbības laiku un Riski pazemināt.

Mērogošana, orķestrācija un programmatūras kaudze: no Docker līdz Kubernetes
Es paļaujos uz Konteineri, jo tas ļauj man panākt reproducējamu vidi un ātru izvietošanu. Docker tēli ar CUDA, cuDNN un piemērotiem draiveriem man ietaupa stundām ilgu iestatīšanas laiku. Es izmantoju Kubernetes ar GPU plānošanu un nosaukumu telpām vairākām komandām. Tas man ļauj skaidri nodalīt darba slodzes un novērst to, ka darba uzdevumi palēnina cits citu. Es izmantoju CI/CD, lai kontrolēti izlaistu modeļus un nodrošinātu izlaidumu organizētību.
Es mēra veiktspēju par katru nodošanu un pārbaudu regresijas agrīnā posmā. Modeļu reģistrs man palīdz izsekojamā veidā pārvaldīt versijas un metadatus. Attiecībā uz secinājumiem es dodu priekšroku mērogošanas pakalpojumiem ar automātisku iesildīšanu. Tas nodrošina zemu latentuma līmeni, kad tiek saņemti jauni pieprasījumi. Es arī veidoju rezerves kopijas Artefakti izmantojot ar S3 saderīgas glabāšanas sistēmas ar dzīves cikla vadlīnijām.
Drošība, datu aizsardzība un atbilstība: pareiza GDPR piemērošana
Es pārbaudu GDPR-atbilstību, datu centru atrašanās vietu un pasūtījumu apstrādi pirms pirmās mācību sesijas. Es šifrēju sensitīvus datus, kad tie tiek saglabāti un pārraidīti. Uz lomām balstīta piekļuve novērš ļaunprātīgu izmantošanu un palīdz veikt revīzijas. Man ir nepieciešama atslēgu pārvaldība un rotācija produktīvām datu plūsmām. Es loģiski nodalu dublējumus no primārās datu glabātuves, lai samazinātu izpirkuma maksu risku. samazināt ..
Uzturu žurnālus, kas ir droši pret revīziju, un skaidri dokumentēju datu plūsmas. Tas atvieglo speciālistu nodaļu pieprasījumus un paātrina apstiprināšanu. Es darbinu tikai tādus modeļus, kuros personas dati ir redzami reģionos ar skaidru juridisko situāciju. Es pievienoju papildu aizsardzības mehānismus medicīniskiem vai finanšu lietojumiem. Tas nodrošina, ka mākslīgā intelekta projekti paliek pārbaudāmi atbilstoši un uzticams.

Malu un hibrīda arhitektūras: secinājumi lietotāja tuvumā
Es bieži dot secinājumu uz Edge tīklā, lai atbildes ātrāk sasniegtu lietotāju. Robežmezgli pārņem pirmapstrādi, filtrē datus un samazina tranzīta izmaksas. Centrālie GPU klasteri pārņem apmācības un smagu sērijveida darbu izpildi. Šāds sadalījums padara sistēmas reaģētspējīgas un rentablas. Ievadam es atsaucos uz Mākslīgais intelekts tīkla malā ar praktiskām arhitektūras idejām.
Es sinhronizēju modeļus, izmantojot versiju atlasi, un pirms aktivizēšanas pārbaudu kontrolsummas. Telemetrija tiek nosūtīta atpakaļ uz vadības centru, lai es varētu savlaicīgi konstatēt novirzes. Ja rodas kļūmes, es pārslēdzos uz mazākiem rezerves modeļiem. Tas nodrošina pakalpojumu pieejamību pat tad, kad joslas platums ir ierobežots. Šādā veidā saglabāju ciešu saikni ar lietotāja pieredzi un nodrošinu. kvalitāte zem slodzes.
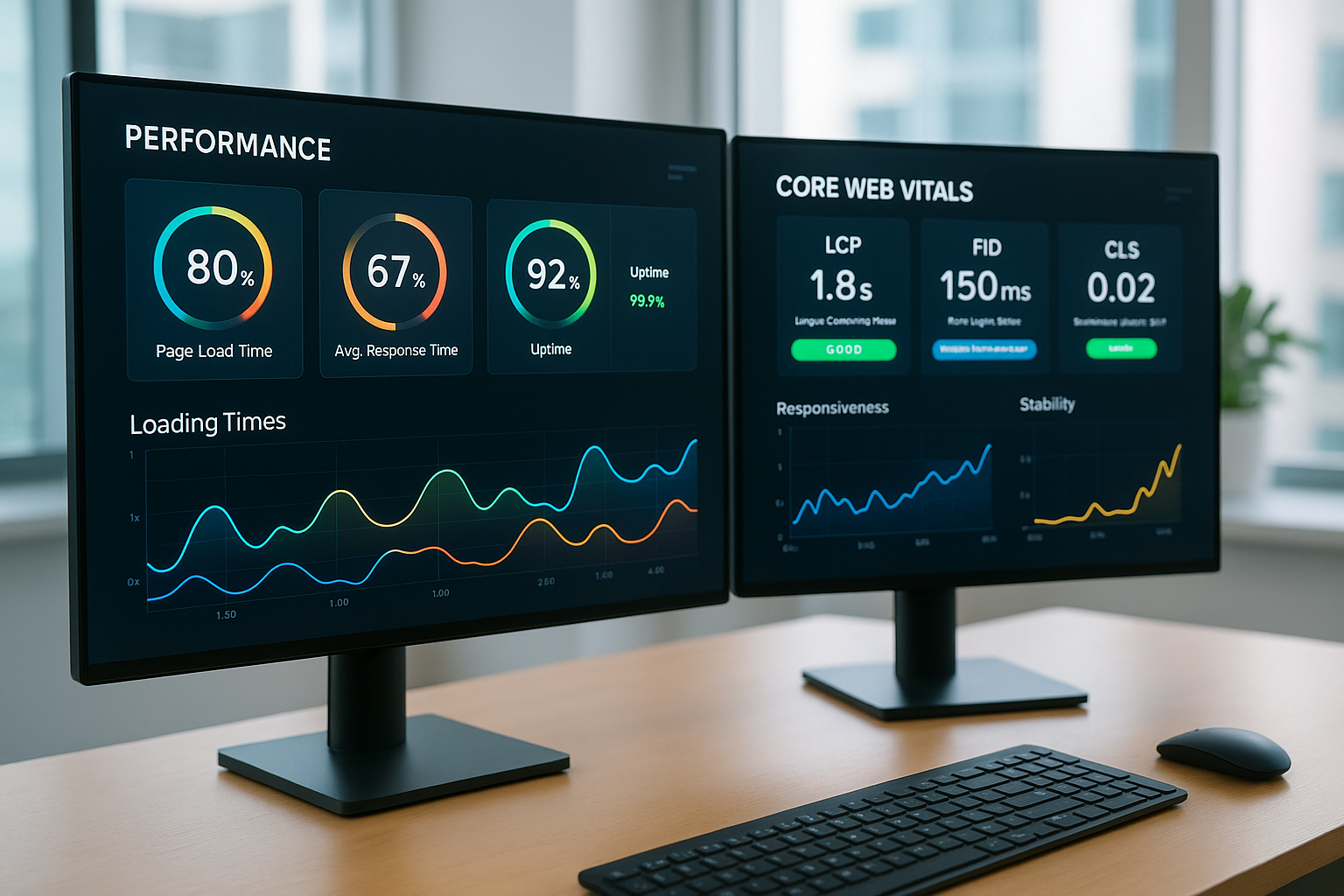
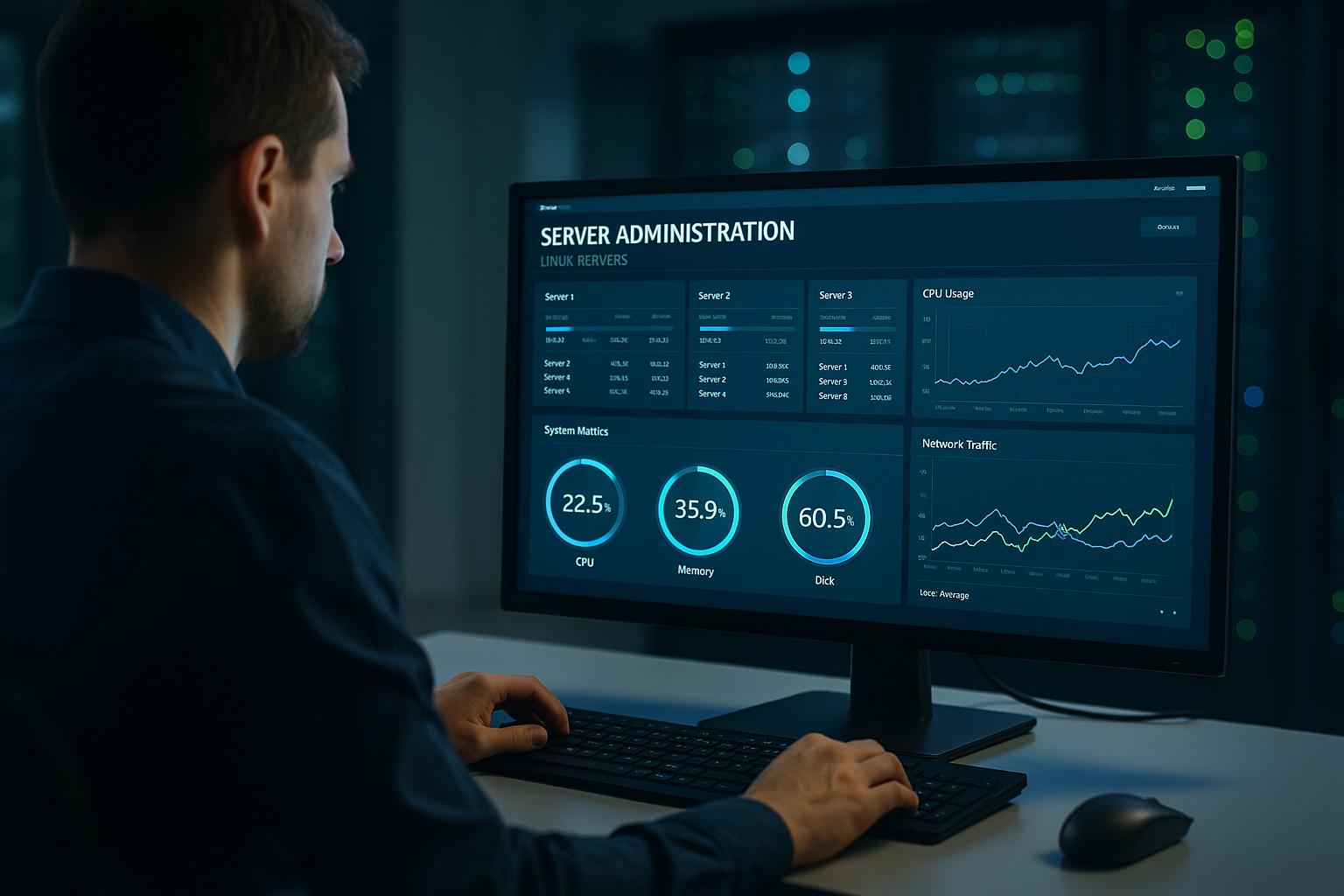
Uzraudzība, novērojamība un SRE prakse: izpildes laika uzraudzība
Uzraugu GPU izmantošanu, VRAM, I/O un Aizkavēšanās reālajā laikā, jo darbības krīzes reti kad sākas skaļi. Agrīnā brīdinājuma sliekšņi dod man laiku veikt pretpasākumus. Siltuma kartes parāda telemetriju pa pakalpojumiem, reģioniem un modeļa versijām. Es izmantoju kļūdu budžetus, lai kontrolētu izlaišanas ātrumu un stabilitāti. Informācijas paneļi operāciju komandā ļauj izvairīties no aklajām zonām 24 stundas diennaktī, 7 dienas nedēļā, 7 dienas nedēļā, 7 dienas nedēļā, 7 dienas nedēļā.
Es automatizēju incidentu spēļu grāmatas un pastāvīgi atjauninu izpildes žurnālus. Sintētiskie testi nepārtraukti pārbauda gala punktus un izlases veidā validē LLM atbildes. Lai kontrolētu izmaksas, ierosinu budžeta brīdinājumus, kas tiek palaisti tieši ChatOps. Tādējādi tiek ģenerētas ātras atbildes bez e-pasta cilpām. Tādējādi tiek saglabāta platforma un Komandas spēt rīkoties, kad palielinās slodze vai izmaksas.

Praktiskais ceļvedis: No vajadzību analīzes līdz darbības uzsākšanai
Katru projektu es sāku ar skaidru Vajadzību analīzeModeļa lielums, datu kopas apjoms, mērķa latence un pieejamība. No tā es atvasinu GPU klases, VRAM un atmiņas paplašināšanu. Pēc tam es plānoju minimālo dzīvotspējīgo cauruļvadu ar datu iegūšanu, apmācību, reģistrāciju un secinājumiem. Es mērogoju horizontāli un pilnveidoju automātisko mērogošanu tikai tad, kad metrikas ir stabilas. Šādā veidā es izvairos no dārgām konversijām vēlākajās fāzēs.
Katrā iterācijā es dokumentēju vājās vietas un novēršu tās vienu pēc otras. Bieži vien es atklāju ierobežojumus nevis GPU, bet gan I/O, tīklā vai atmiņā. Mērķtiecīga profilēšana ietaupa vairāk naudas nekā akli uzlabojumi. Operatīvi svarīgām lietojumprogrammām pirms palaišanas es veicu slodzes testus. Pēc tam es ieviestu konservatīvi un nodrošinu, ka Atgriešanās-iespēja ar zili zaļu vai kanārijputniņu stratēģijām.

Veiktspējas regulēšana GPU līmenī: precizitāte, VRAM un paralēlisms
Es optimizēju Apmācība un Secinājumi Vispirms par aprēķinu režīmu: jauktā precizitāte (piemēram, FP16, BF16 vai FP8 jaunākās kartēs) ievērojami paātrina caurlaides spēju, ja vien skaitļi un stabilitāte ir pareizi. Lieliem modeļiem es izmantoju gradientu kontrolpunktu un aktivizācijas atmiņas sadali, lai ietaupītu VRAM. Es arī izmantoju efektīvus partijas lielumus: Es testēju pa posmiem, līdz caurlaides spēja un stabilitāte ir optimāla. Secinājumu izdarīšanā es līdzsvaroju Dozēšana pret latentuma budžetiem; mazas, dinamiskas partijas uztur p95 latentumu robežās, bet maksimums tiek absorbēts, izmantojot automātisko mērogošanu.
Atmiņas pusē es paļaujos uz lapu bloķētu resursatmiņu (piespraustā atmiņa), lai nodrošinātu ātrāku pārsūtīšanu, un pievēršu uzmanību konsekventai CUDA- un draiveru versijas. Es arī pārbaudu, vai ietvars efektīvi izmanto kodola kodola saplūšanu, zibatmiņas uzmanību vai tenzoru kodolus. Šīs detaļas bieži vien ir noteicošākas reālai paātrināšanai nekā GPU nosaukums vien.
Multi-GPU un izkliedēta apmācība: izpratne par topoloģijām
Es plānoju Izplatītas mācības atkarībā no topoloģijas: saimnieka iekšienē ir svarīgi NVLink savienojumi un PCIe joslas; starp saimniekiem ir svarīgs joslas platums un aizture (InfiniBand/Ethernet). Es izvēlos AllReduce algoritmus, lai tie atbilstu modelim un partijas lielumam, un uzraugu, kā tiek izmantoti NCCL-kolektīvi. Ja datu sadalījuma lieluma atšķirības ir lielas, es izmantoju gradientu uzkrāšanu, lai palielinātu faktisko partijas lielumu, nepārsniedzot VRAM. Ja klasteri spēj izmantot vairākus klientus, GPU slīpēšana (piem. MIG) un MPS, lai vairāki darbalaiki varētu pastāvēt vienlaikus un netiktu viens otru slāpēti.
Secinājumu optimizācija ražošanā: apkalpošana un SLA
Es atdalīju Apkalpo stingri no mācību un dimensiju replikām saskaņā ar mērķa SLA. Modeļu serveri ar dinamisku pakešu veidošanu, tenzoru apvienošanu un kodola atkārtotu izmantošanu nodrošina zemu latentuma līmeni. Es paralēli pārvaldu vairākas modeļa versijas un aktivizēju jaunus variantus, izmantojot svērto maršrutēšanu (Canary), lai samazinātu riskus. Uz žetoniem balstītiem LLM es mēra žetonus/s katrai replikai, silto sākuma laiku un p99 latentumu atsevišķi sagatavošanas un pabeigšanas fāzēm. Ievietojumu, tokenizatoru un biežu pamudinājumu kešatmiņas samazina auksto startu un ietaupa GPU sekundes.
Pārvaldība, reproducējamība un datu dzīves cikls
Es nodrošinu Reproducējamība ar fiksētām sēklām, deterministiskiem operatoriem (ja iespējams) un precīziem versiju statusiem ietvariem, draiveriem un konteineriem. Datu versiju veidošana ar skaidriem saglabāšanas noteikumiem novērš neskaidrības un atvieglo auditu veikšanu. Funkciju krātuve samazina sagatavošanas dublēšanos un nodrošina konsekventus apmācības un secinājumu ceļus. Atbilstības nodrošināšanai dokumentēju datu ierakstu izcelsmi, mērķa ierobežojumu un dzēšanas periodus - tas paātrina apstiprināšanu un aizsargā pret ēnu slodzēm.
Enerģija, ilgtspēja un izmaksas uz rezultātu
Es uzraugu Jauda uz vatu un izmantot jaudas ierobežotājus, ja darba slodze ir jutīga pret termiskajām vai akustiskajām īpašībām. Liela noslodze īsos logos parasti ir efektīvāka nekā pastāvīga daļēja slodze. Es mēra ne tikai izmaksas stundā, bet arī izmaksas uz vienu pabeigtu epohas darbību vai uz 1000 secinājumu pieprasījumiem. Šie Ar uzņēmējdarbību saistīts Galvenais skaitlis atklāj optimizācijas: Dažreiz nelielas arhitektūras izmaiņas vai INT8 kvantifikācija ļauj ietaupīt vairāk nekā piegādātāja maiņa.
Problēmu novēršana un tipiski klupšanas akmeņi
- OOM kļūdaIzvēlieties mazāku partiju, aktivizējiet kontrolpunktu izveidi, samaziniet atmiņas fragmentāciju, regulāri to atbrīvojot.
- Draiveris/CUDA neatbilstībaStingri ievērojiet savietojamības matricu, piespraudiet konteineru bāzes attēlus, testējiet atjauninājumus kā atsevišķus cauruļvadus.
- Nepilnīga izmantošanaDatu sagatavošana vai tīkls bieži vien ir vājā vieta - palīdz iepriekšēja atlase, asinhronā I/O un NVMe kešatmiņa.
- P2P veiktspējaPārbaudiet NVLink/PCIe topoloģiju, optimizējiet NUMA radniecību un procesu sasaisti.
- MIG fragmentācijaLai izvairītos no tukšām atstarpēm, plānojiet šķēles atbilstoši VRAM prasībām.
Minimizēt pārnesamību un bloķēšanu
Es turu Pārnesamība augsta, lai pāreja no viena pakalpojumu sniedzēja pie otra būtu veiksmīga: infrastruktūra kā kods identiskai nodrošināšanai un modeļu formāti, ko var plaši izmantot. Secinājumiem es izmantoju optimizācijas ceļus (piemēram, grafiku optimizāciju, kodola saplūšanu), pārāk cieši nesaistot sevi ar patentētām atsevišķām sastāvdaļām. Ja tas ir lietderīgi, es plānoju profilus dažādām GPU paaudzēm, lai elastīgi kontrolētu veiktspēju un izmaksas.
Drošības inženierijas padziļināšana ML kontekstā
Es paplašinu drošību, izmantojot Veidot integritāti un piegādes ķēdes aizsardzība: parakstīti attēli, SBOM un regulāra skenēšana līdz minimumam samazina uzbrukuma iespējas. Es pārvaldu noslēpumus centralizēti un automātiski tos rotēju. Sensitīvās vidēs es nodalu mācību un ražošanas tīklus un konsekventi īstenoju tīkla politiku un izolācijas mehānismus. Datu maskēšana sākotnējos posmos novērš to, ka neapstrādātus datus redz nevajadzīgi liels skaits sistēmu. Tādējādi tiek saglabāts līdzsvars starp ātrumu un atbilstību.
Jaudas plānošana un KPI, kas patiešām ir svarīgi
Es plānoju jaudu, pamatojoties uz Skaidri skaitļi sajūtu vietā: attēli/s vai žetoni/s apmācībā, p95/p99 latences secināšanā, caurlaidspēja uz vienu eiro un GPU un uzdevuma izmantošana. Es šos rādītājus sasaistīju ar SLO. Regulārām pārmācībām es aprēķinu fiksētus laika logus un izveidoju rezervācijas - visu, kas atkārtojas, var plānot un ir lētāk. Spontānai maksimālai noslodzei es turu brīvas kvotas, lai bez gaidīšanas varētu palaist papildu replikas.
Perspektīvas un īss kopsavilkums
Es redzu GPU hostings kā virzītājspēks ML apmācībai, secinājumiem un uz datiem balstītām tīmekļa lietojumprogrammām. Jaudīgu GPU, NVMe atmiņas un ātra tīkla kombinācija ievērojami palielina caurlaides spēju. Pateicoties automātiskai mērogošanai un skaidriem SLA, platforma ir elastīga un paredzama. GDPR prasībām atbilstoši datu centri un 24/7 atbalsts stiprina uzticēšanos sensitīviem projektiem. Ja definējat skaidrus mērķus, precīzi tos mērojat un iteratīvi optimizējat, varat droši gūt maksimālu labumu no mākslīgā intelekta slodzēm. Pievienotā vērtība ārā.