Pāriet uz saturu
Pāriet uz saturu 
Es parādīšu, kā Kubernetes hostings webhostingā konteineru darba slodzes tiek uzticami koordinētas, automatizēti mērogotas un eleganti novērstas kļūmes. Tādējādi konteineru hostings, Docker un Kubernetes var apvienot vienā augstas veiktspējas platformā, kas efektīvi nodrošina mikroservisi, CI/CD un hibrīda klasterus.
Centrālie punkti
- Mērogmaiņa sekundēs, pateicoties automātiskajai mērogošanai un HPA
- Automatizācija izvēršanai, atgriešanai un pašatjaunošanai
- Pārnesamība starp lokālo, mākoņpakalpojumu un hibrīda risinājumu
- Efektivitāte izmantojot resursus optimāli
- Drošība izmantojot politiku, izolāciju un DDoS aizsardzību

Konteinera hostings: īss un skaidrs izklāsts
Konteineri apvieno lietotni, darbības laiku un atkarības vienā pārnēsājamā paketē, kas darbojas uz jebkura uzņēmuma ar dzinēju; šie Pārnesamība samazina tipiskos „darbojas tikai manā gadījumā“ efektus. Es sāku konteinerus dažu sekunžu laikā, klonēju tos slodzes maksimuma gadījumā un dzēšu tos, kad slodze samazinās. Tādējādi es izmantoju CPU un RAM daudz efektīvāk nekā ar klasiskajām VM, jo konteineriem ir mazākas papildizmaksas. Web projektiem tas nozīmē ātru ieviešanu, paredzamas versijas un atkārtojamas izlaides. Ja konteinera attēlus strukturējat skaidri, jūs ilgtermiņā gūsit labumu no nemainīgas kvalitāte.
Kāpēc Kubernetes dominē orķestrēšanā
Kubernetes automātiski sadala konteinerus pa mezgliem, novēro to stāvokli un aizstāj bojātos podus bez manuālas iejaukšanās; šie Pašatjaunošanās novērš darbības pārtraukumus. Horizontal Pod Autoscaler mēro replikas, pamatojoties uz tādiem rādītājiem kā CPU vai lietotāja definēti KPI. Rolling Updates pakāpeniski nomaina versijas, kamēr pakalpojumi stabili turpina pārsūtīt datplūsmu. Ar Namespaces, RBAC un NetworkPolicies es skaidri nošķiru komandas un darba slodzi. Praktiska ievada Konteineru orķestrācija palīdz droši un strukturēti izveidot pirmos klasterus un Vadības sistēma saprast.

Kubernetes hosting tīmeklī: tipiski scenāriji
Mikro pakalpojumi sniedz lielas priekšrocības, jo es katru pakalpojumu izvēršu, mērogu un versiju atsevišķi; Atdalīšana samazina risku un paātrina izlaides. E-komercijas veikali neatkarīgi mēro frontendu un izrakstīšanos, kas ietaupa izmaksas un novērš pīķus. API ar satiksmes svārstībām saņem tieši tik daudz jaudas, cik nepieciešams. Hibrīdās konfigurācijās es dinamiski pārnesu darba slodzi starp savu datu centru un publisko mākoni. Komandām ar CI/CD es savienoju cauruļvadus ar klasteri un automātiski piegādāju augstākā līmenī. pakāpes no.
Mērogošana, pašatjaunošanās un atjauninājumi ikdienas darbībā
Es definēju pieprasījumus un limitus katram podam, lai plānotājs un HPA varētu pieņemt pareizos lēmumus; šie Robežvērtības ir uzticamas plānošanas pamats. Gatavības un darbības pārbaudes pārbauda stāvokli un nepieciešamības gadījumā automātiski aizstāj podus. Rolling un Blue‑Green atjauninājumi samazina izvietošanas riskus, bet Canary izlaides pakāpeniski testē jaunas funkcijas. PodDisruptionBudgets aizsargā minimālās jaudas apkopes laikā. Web lietojumprogrammām es apvienoju Ingress ar TLS pārtraukšanu un tīru Maršrutu, lai lietotāji vienmēr redzētu pieejamos galapunktus.

Arhitektūra: no mezgla līdz pakalpojumam
Klasteris ietver kontroles plānu un darba mezglus; izvietojumi rada podus, pakalpojumi eksponē galapunktus, un ieeja apvieno domēnus un maršrutus; šie Līmeņi saglabā skaidru struktūru. Etiķetes un selektori saista resursus saprotamā veidā. Lai panāktu lielāku efektivitāti, es podus ar afinitātes noteikumiem mērķtiecīgi ievieto mezglos ar atbilstošu aparatūru, piemēram, NVMe vai GPU. Vārdu telpas izolē projektus, bet LimitRanges un Quotas novērš ļaunprātīgu izmantošanu. Ja vēlaties padziļināt savas zināšanas par konteinera nativā hostinga iesaistās, plāno jau iepriekš, kā komandas darba slodzi un Rullīši atdalīt.
Viedi plānojiet uzglabāšanu un tīklu
Pastāvīgiem datiem es izmantoju PersistentVolumes un atbilstošas StorageClasses; tajā pašā laikā es ņemu vērā latentumu, IOPS un datu aizsardzību; šie Kritēriji nosaka reālo lietotņu veiktspēju. StatefulSets saglabā identitātes un piešķir stabilus apjomus. Tīklā es izmantoju Ingress kontrolierus, iekšējos pakalpojumus un politiku, kas atver tikai nepieciešamos portus. Pakalpojumu tīkls var nodrošināt mTLS, atkārtotas mēģinājumu un izsekošanu, ja mikropakalpojumi paplašinās. DDoS aizsardzībai un ātruma ierobežošanai es apvienoju Edge filtrus un klasteriem tuvu Noteikumi.

Pārvaldīta vai pašapkalpošanās? Izmaksas un kontrole
Man patīk salīdzināt izdevumus un ietekmi: pārvaldīti piedāvājumi ietaupa darbības laiku, savs uzņēmums man nodrošina pilnīgu Vadība. Daudzām komandām ir izdevīgi izmantot pārvaldītu pakalpojumu, jo tajā jau ir iekļauta 24/7 darbība, labojumi un atjauninājumi. Tie, kam ir īpašas prasības, gūst labumu no pašas darbības, taču tam ir nepieciešams nodrošināt personālu, uzraudzību un drošību. Orientācijai palīdz aptuveni aprēķini eiro valūtā, kas parāda pašreizējās izmaksas. Papildus es lasu informāciju par Pārvaldītais Kubernetes un plānoju Dzīves cikls reāli.
| Modelis | Darbības izdevumi | Kārtējās izmaksas/mēnesī | Vadība | Pieteikuma profils |
|---|---|---|---|---|
| Pārvaldītais Kubernetes | Zems (pakalpojuma sniedzējs pārņem kontroles plānu, atjauninājumus) | No aptuveni 80–250 € par katru klasteri, plus mezgli | Līdzekļi (politikas, mezgli, izvietojumi) | Komandas, kas vēlas ietaupīt laiku un uzticami paplašināties |
| Pašu darbība | Augsts (uzstādīšana, labojumi, 24/7, dublējums) | No aptuveni 40–120 € par katru mezglu + administratora kapacitāte | Augsts (pilnīga piekļuve vadības plānam) | Īpašas prasības, pilnīga pielāgojamība, On‑Prem‑Cluster |
Monitorings un drošība klastera ikdienā
Mērījumi parāda jaudas, tāpēc es izmantoju Prometheus, Grafana un Log‑Pipelines; tas Uzraudzība atklāj šaurās vietas. Brīdinājumi informē par latences pīķiem vai CrashLoops. Drošības nolūkā es piemēroju vismazākās privilēģijas, izmantojot RBAC, Secrets un parakstus attēliem. NetworkPolicies ierobežo austrumu-rietumu satiksmi, bet Ingress pieprasa drošības galvenes un TLS. DDoS aizsargāts Edge un tīrs labojumu process samazina uzbrukumu risku. mazs.

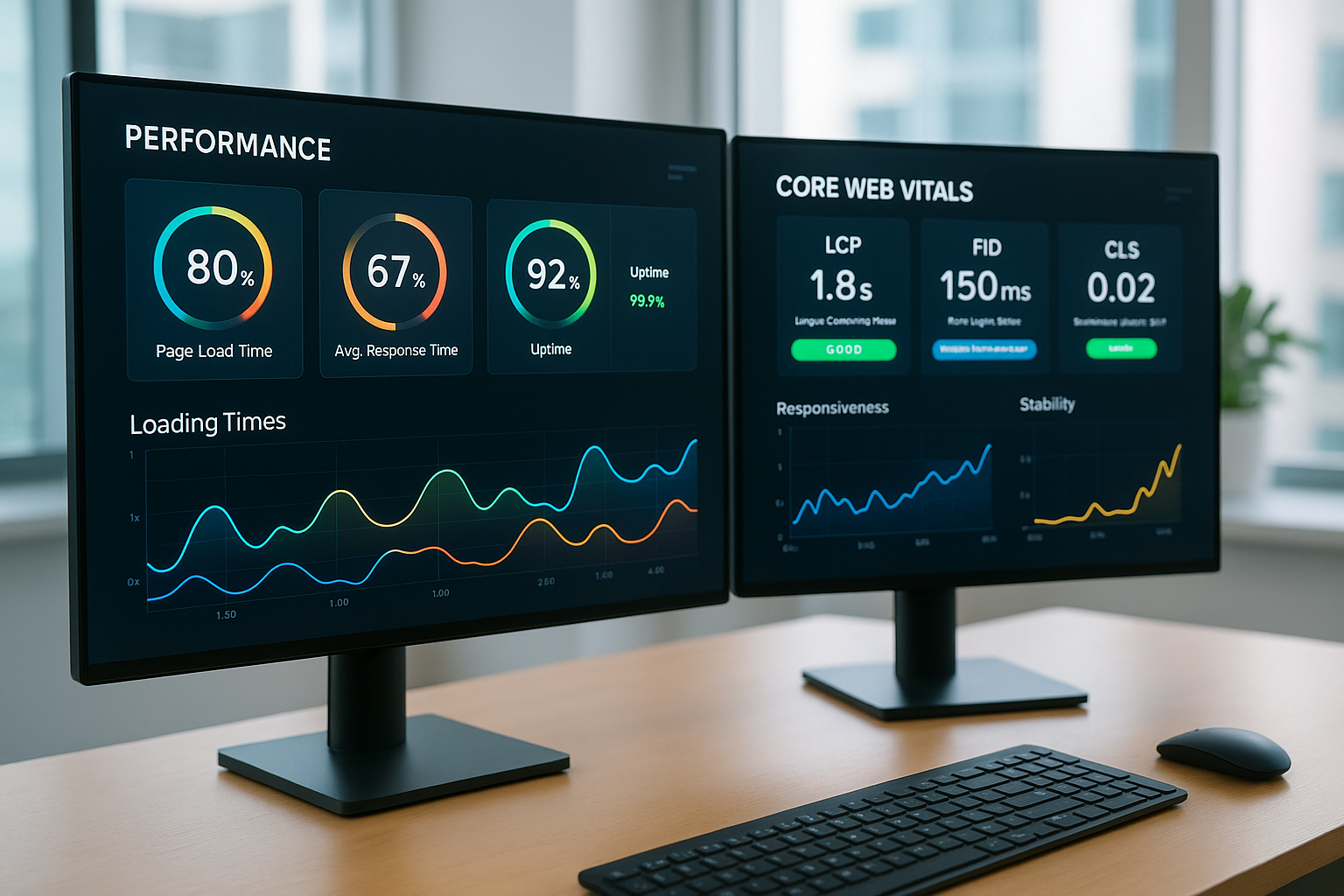
Veiktspējas uzlabošana tīmekļa skriptiem
Es sāku ar pieprasījumiem/ierobežojumiem katram podam un mēru reālo slodzi; šie Pamatlīnija novērš pārlieku resursu piešķiršanu. HPA reaģē uz CPU, RAM vai lietotāja definētiem rādītājiem, piemēram, pieprasījumiem sekundē. Caching pirms lietotnes un datu bāzes samazina latences, bet Pod Topology Spread nodrošina sadali pa zonām. Node‑Sizing un atbilstoši konteineru attēli samazina aukstos startus. Ar PGO PostgreSQL vai JVM‑Flags pakalpojumi izmanto vairāk Power no.
Piegādātāja izvēle: kam es pievēršu uzmanību
Es pārbaudu pieejamību, I/O veiktspēju, tīkla kvalitāti un atbalsta laikus; šie Kritēriji galu galā nosaka lietotāja pieredzi. Pārskats par DDoS aizsardzību, privāto tīklu un dublējuma iespējām novērš vēlākas pārsteigums. Labi pakalpojumu sniedzēji piedāvā skaidru cenu struktūru bez slēptām maksām. Web projektiem ar slodzes pīķiem mani pārliecina piedāvājums ar 99,99%+ darbības laiku, automātisku mērogošanu un reālu 24/7 atbalstu. Salīdzinājumos webhoster.de izceļas ar spēcīgu veiktspēju un uzticamību. Pieejamība tālu priekšā.
CI/CD un GitOps tīra saskaņošana
Lai nodrošinātu nemainīgi augstu kvalitāti, es apvienoju izstrādes, testēšanas un ieviešanas posmus kā atkārtojamus Cauruļvadi. Attēli tiek deterministiski radīti no tagiem vai komitiem, tiek parakstīti un nonāk privātā reģistrā. Klasteris izmanto tikai apstiprinātus artefaktus. Ar GitOps es deklaratīvi aprakstu vēlamo stāvokli; operators sinhronizē izmaiņas no Git uz klasteri un veic katru pielāgojumu. saprotams. Nozares stratēģijas un vides (dev, staging, prod) nodrošina tīras veicināšanas takas. Funkciju karodziņi ļauj atdalīt izlaides no funkciju aktivizēšanas – ideāli piemērots Canary izlaišanai ar kontrolētu Risks‑līkne.
Infrastruktūra kā kods: konsekventa no klastera līdz pakalpojumam
Es fiksēju infrastruktūru, klasteru papildinājumus un lietotņu manifestus kā kodu. Tādējādi rodas reproducējami Apkārtne jaunām komandām vai reģioniem. Pamata komponentiem es izmantoju deklaratīvus rīkus, bet Helm vai Kustomize strukturē lietojumprogrammu līmeni. Parametrus, piemēram, domēnus, resursus vai slepenos datus, es kapsulēju katrai videi atsevišķi. Šī nošķiršana novērš „sniegpārslu“ konfigurācijas un paātrina atjaunošana pēc izmaiņām vai katastrofām.
2. dienas darbība: uzlabojumi, apkope un pieejamība
Es plānoju atjauninājumus, ņemot vērā versiju nobīdes un API atcelšanas. Es testēju jaunās versijas izmēģinājuma vidē, aktivizēju Pārspriegums-Rollouts un izmantojiet apkopes logus ar PDB, lai aizsargātu jaudu. Cluster Autoscaler pielāgo mezglu kopas, kamēr Drain un Pod‑Eviction darbojas nevainojami. Regulāras etcd datu un kritisko PersistentVolumes dublējumu veikšana ir jāiekļauj kalendārā; atjaunošanas paraugi apstiprina, ka atjaunošanas plāni ir praktiski funkcija. Lai nodrošinātu nulles pārtraukuma laiku apkopē, es sadalu darba slodzi pa zonām un nodrošinu kritisko pakalpojumu ģeogrāfisko redundanci.
Paplašināta drošība: piegādes ķēde, politikas un darbības laiks
Drošība sākas ar izveidi: es skenēju bāzes attēlus, izveidoju SBOM un parakstu artefaktus; klasteris pieņem tikai uzticams Attēli. Pod drošības standarti, ierobežojoši pod drošības konteksti (runAsNonRoot, readOnlyRootFilesystem, seccomp) un minimālistiski ServiceAccounts ierobežo tiesības. Tīkla politikas un izplūdes kontrole novērš datu noplūdi. Uzņemšanas politikas ievieš konvencijas (etiķetes, ierobežojumi, nemainīgas birkas). Darbības laikā eBPF sensori uzrauga sistēmas izsaukumus un tīkla ceļus, lai atklātu anomālijas. Es šifrēju slepeno informāciju at-rest kontrolplānā un rotēju to saskaņā ar Specifikācijas.
Izmaksu optimizācija un FinOps klasterī
Es samazinu izmaksas, izmantojot trīs līdzekļus: pareizos izmērus, augstu noslogojumu un mērķtiecīgas cenu modeļus. Es izvēlos pieprasījumus tā, lai HPA varētu tīri skalēties, neizraisot CPU droseles ierobežojumus; ierobežojumus es nosaku tikai tur, kur tas ir nepieciešams. nepieciešams Vertical Pod Autoscaler palīdz veikt regulēšanu, bet Cluster Autoscaler noņem neizmantotos mezglus. Ar Taints/Tolerations es atdalīju kritiskās slodzes no oportunistiskajām slodzēm; pēdējās darbojas uz lētām, īslaicīgām jaudām. Topology Spread un Bin‑Packing stratēģijas palielina Efektivitāte. Izmaksu marķējumi (komanda, pakalpojums, Env) padara patēriņu pārredzamu; tādējādi es optimizāciju prioritizēju, balstoties uz datiem, nevis taupot „pēc sajūtas“.

Datu bāzes un stāvoklis: pragmatisks lēmums
Ne katrs stāvoklis pieder pie klastera. Ļoti kritisku datu gadījumā es bieži izmantoju pārvaldītos Datu bāzes ar SLA, automātiskām dublējumkopijām un replikāciju; lietotņu darba slodzes paliek elastīgas Kubernetes. Ja izmantoju StatefulSets, es skaidri plānoju uzglabāšanas profilus, momentuzņēmumu stratēģijas un atjaunošanu. Anti-Affinity un Topoloģija Izplatīšana samazina zonu darbības traucējumu risku. Svarīgi ir skaidri noteikt atbildības jomas: kurš veic dublējumus, kurš testē atjaunošanu, kurš uzrauga latences un IOPS? Tikai tad, kad būs atbildes uz šiem jautājumiem, stāvoklis klasterī kļūs patiesi stabils.
Novērojamība un SLO: no mērīšanas līdz vadībai
Mērāmība ietver metrikas, žurnālus un Izsekojumi. Es papildinu metrikas ar pieprasījumu un DB latences, lai redzētu reālo lietotāju pieredzi. Pamatojoties uz definētiem SLO (piemēram, 99,9 % % veiksmīguma rādītājs, P95 latence), es definēju brīdinājumus, kas ietekmē kļūdu budžetu. Šie budžeti kontrolē tempu un Risks manu izlaidumu gadījumā: ja tie ir izsmelti, es dodu priekšroku stabilitātei, nevis jaunu funkciju ieviešanai. Tādējādi tiek saglabāts līdzsvars starp mērogu un inovācijām.
Praktisks kontrolsaraksts uzsākšanai
- Saglabāt konteineru attēlus nelielus, uzturēt bāzes attēlus, automatizēt Skenēšana Aktivizēt
- Nosaukt telpas, kvotas un RBAC katrai komandai/pakalpojumam, piemērot politiku no paša sākuma
- Pieprasījumi/limiti kā Pamatlīnija iestatīt, ieviest HPA, PDB kritiskajiem pakalpojumiem
- Ingress aprīkot ar TLS, drošības galvenajiem un ātruma ierobežojumiem; DDoS aizsardzība malā
- Testēt etcd un pastāvīguma dublējumus; iekļaut atjaunošanas paraugus apkopes plānā
- Ieviest GitOps deklaratīvai izvietošanai; skaidri dokumentēt paaugstināšanas ceļus
- Uzstādīt monitoringu ar metrikām, žurnāliem un izsekojumiem; izvest SLO un brīdinājumus
- Izmantot izmaksu marķējumus, regulāri izmantot jaudu pārskatīt, Nodepools optimizēšana
Kompakts kopsavilkums
Kubernetes Hosting piedāvā Mērogmaiņa, automatizāciju un augstu pieejamību savā tīmekļa hostingu un padara konteineru darba slodzi pārnesamu. Izmantojot Docker kā iepakojumu un Kubernetes kā orķestrēšanu, jūs varat izveidot ātrus izlaidumus, elastīgas ieviešanas un efektīvu resursu izmantošanu. Ja izmantojat mikropakalpojumus, API vai e-komerciju, iegūsit elastīgumu, īsākus izlaides ciklus un pārredzamās izmaksas. Izvēlieties starp pārvaldītu un pašapkalpošanu, ņemot vērā izmaksas, kontroli un budžetu eiro. Ar gudru arhitektūru, precīzu uzraudzību un stingru drošību paliek Veiktspēja pastāvīgi augsts – šodien un rīt.