Agencje i programiści zabezpieczają się za pomocą strategia hostingu wielochmurowego niezależność: rozdzielam obciążenia robocze między kilku dostawców, ograniczam ryzyko i zapewniam elastyczność projektów w każdym momencie. W ten sposób łączę wydajność, zgodność z przepisami i kontrolę kosztów – bez Blokada dostawcy oraz jasnymi procesami dotyczącymi działania i skalowania.
Punkty centralne
Oto główne punkty, na których skupiam się, chcąc zapewnić agencjom i programistom niezależność od hostingu – w sposób zwięzły i łatwy do wdrożenia.
- Blokada Unikaj: przenoś obciążenia między chmurami, swobodnie wybieraj ceny i technologie.
- Zasoby Optymalizacja: korzystaj z usług dostawcy odpowiedniego do danego zastosowania, oszczędzaj budżet.
- Niezawodność zwiększyć: wiele regionów i dostawców, usługi pozostają dostępne online.
- Zgodność zabezpieczyć: wybierać lokalizacje zgodne z RODO, kontrolować dostęp.
- Automatyzacja Korzyści: CI/CD, IaC i kopie zapasowe zmniejszają nakłady pracy i liczbę błędów.

Dlaczego niezależność hostingowa ma znaczenie dla agencji
Projektuję projekty w taki sposób, aby w każdej chwili móc zmienić dostawcę i Niezależność Prawda. Według analiz rynkowych do 2025 r. około 80% przedsiębiorstw będzie korzystać z modeli wielochmurowych [1], co pokazuje, że trend ten jest już ustalony i zapewnia namacalne korzyści. Korzystanie z usług tylko jednego dostawcy wiąże się z ryzykiem wzrostu kosztów, ograniczeń technicznych i dłuższych przestojów – rozproszona infrastruktura znacznie zmniejsza te ryzyka [1][3]. Jednocześnie zbliżam usługi do użytkowników, mądrze wybierając regiony i zauważalnie skracając czasy odpowiedzi [1][3]. Ochrona danych pozostaje pod kontrolą: umieszczam wrażliwe dane w europejskich centrach danych i stawiam na oferty z certyfikatem ISO, aby projekty pozostały zgodne z przepisami [10].
Od analizy do eksploatacji: tak planuję architekturę
Na początku jest analiza wymagań: Jakie opóźnienia, dostępność i zgodność są wymagane dla każdej aplikacji – i jakie są zależności [1][9]? Następnie porównuję dostawców pod względem stosunku ceny do jakości, usług, możliwości integracji i bliskości regionalnej; konfiguracje o wysokiej wydajności z silnym ukierunkowaniem na programistów wdrażam preferencyjnie u dostawców, którzy w widoczny sposób ułatwiają przepływ pracy w agencji [2]. W przypadku migracji jasno rozdzielam obowiązki, definiuję interfejsy API i przygotowuję scenariusze testowe, aby przejście przebiegło bez awarii; lokalne konfiguracje stagingowe, na przykład za pomocą narzędzi takich jak DevKinsta, przyspieszają przejścia i zapewniają bezpieczne wdrażanie aktualizacji [12]. Ustanawiam zasady zarządzania rolami, centrami kosztów i zatwierdzeniami, łącząc je z centralnym monitorowaniem i automatycznymi kontrolami bezpieczeństwa [10]. Na koniec definiuję procedury operacyjne: kopie zapasowe, ćwiczenia z zakresu odzyskiwania danych po awarii, okna aktualizacji i jasne Runbooki – dzięki temu codzienność pozostaje pod kontrolą.

Wzorce architektury zapewniające przenośność i niskie powiązania
Tworzę aplikacje przenośny, aby można je było łatwo przenosić między dostawcami. Obciążenia kontenerowe oddzielają kompilację od czasu wykonywania, podczas gdy ja ściśle rozdzielam stan i obliczenia. Zasady 12-czynnikowe, jasno zdefiniowane interfejsy i wersjonowanie semantyczne zapobiegają przerwom podczas zmian. W przypadku danych ograniczam “grawitację danych”: minimalizuję zapytania przekrojowe między regionami/dostawcami, stosuję replikację w sposób ukierunkowany i przenoszę Zmiany schematu Odporny na migrację (kompatybilny wstecznie i przyszłościowo). Wzorce oparte na zdarzeniach z kolejkami/strumieniami buforują szczyty obciążenia, podczas gdy idempotentni konsumenci ułatwiają cofanie zmian. Tam, gdzie usługi wymagają funkcji specyficznych dla dostawcy, zamykam je za własnymi Interfejsy adapterów – dzięki temu logika biznesowa pozostaje niezależna.
Oprzyrządowanie i koordynacja: mniej wysiłku, większa kontrola
Łączę zasoby wielu chmur za pomocą Orkiestracja, aby wdrożenia, skalowanie i sieć usług działały sprawnie. Przejrzysty zestaw narzędzi sprawia, że nie muszę stosować specjalnych rozwiązań na każdej platformie. W praktyce korzystam z centralnych pulpitów nawigacyjnych, aby mieć podgląd na stan, koszty i wykorzystanie zasobów u różnych dostawców. Jak może wyglądać nowoczesny zestaw narzędzi, pokazuje Orkiestracja w wielu chmurach z integracjami dla popularnych środowisk hostingowych. W ten sposób ograniczam codzienne utrudnienia, oszczędzam czas podczas wdrożeń i utrzymuję Przejrzystość wysoki.
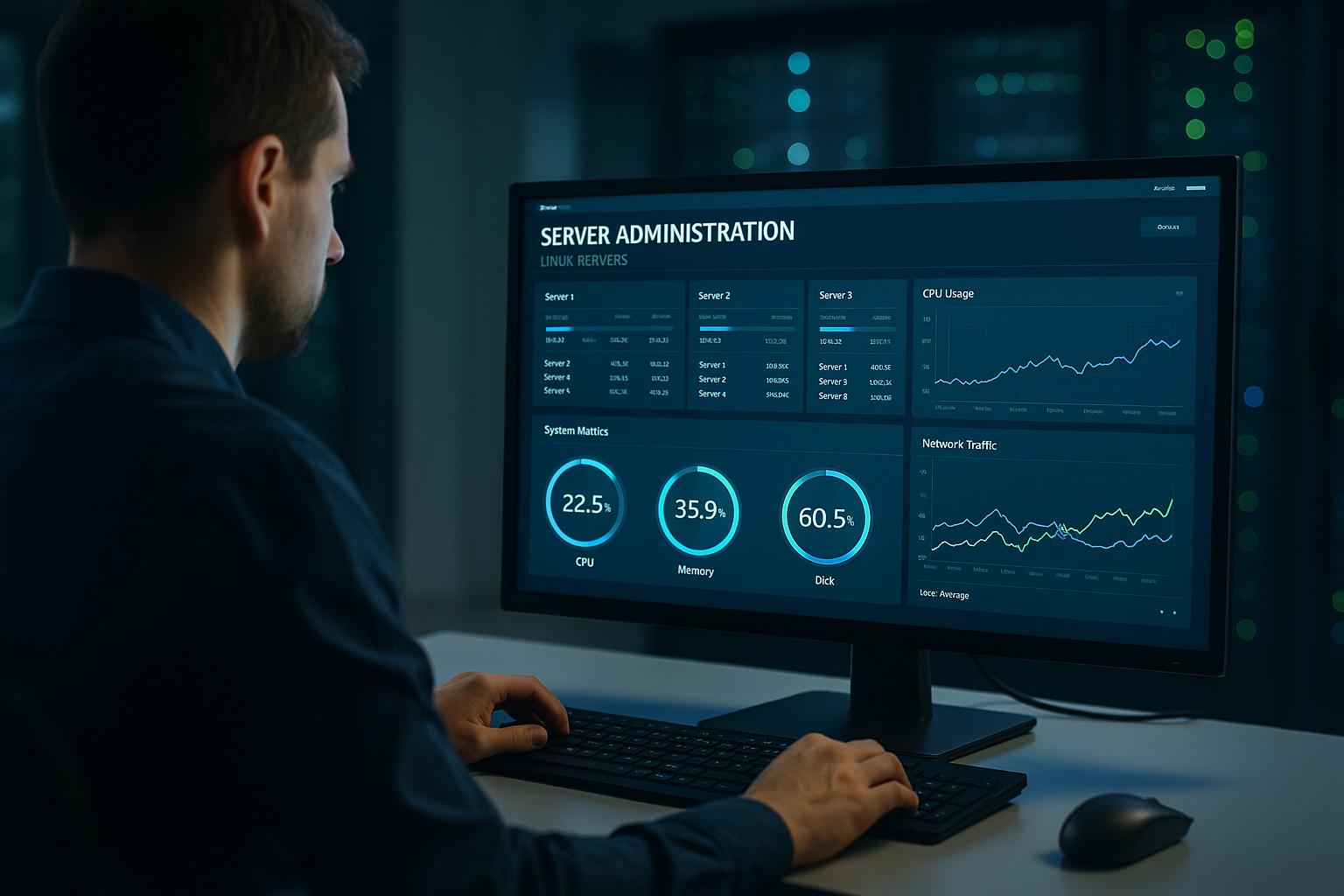
Zarządzanie, bezpieczeństwo i monitorowanie
Konsekwentnie prowadzę Najmniejszy przywilej-dostęp, aby zespoły widziały i zmieniały tylko to, co jest naprawdę konieczne. Lokalizacje zgodne z RODO, umowy o przetwarzaniu danych i środowiska ISO27001 są obowiązkowe w projektach klientów [10]. Kompleksowy monitoring rejestruje opóźnienia, wskaźniki błędów, koszty i zdarzenia związane z bezpieczeństwem; alarmy są grupowane, aby umożliwić mi szybkie podejmowanie decyzji. Polityki wymuszają szyfrowanie, bezpieczne protokoły i zasady dotyczące cyklu życia danych – zmniejsza to ryzyko i usprawnia audyty. Do powtarzających się kontroli używam automatycznych skanów bezpieczeństwa, dzięki czemu mogę wcześnie wykrywać odchylenia i słabe punkty szybko zamykam.
Tożsamość, sekrety i zarządzanie kluczami
Centralizuję tożsamości za pomocą SSO (np. OIDC/SAML) i automatycznie synchronizuję grupy/role (SCIM), aby uprawnienia były spójne we wszystkich chmurach. Zarządzam sekretami z dokładnością co do wersji i dostępu, automatycznie je rotuję i stawiam na krótkotrwałe dane logowania zamiast klucza statycznego. Do szyfrowania używam metod opartych na KMS, preferuję opcje BYOK/HSM i oddzielam zarządzanie kluczami od zespołów operacyjnych. Skanowanie tajnych danych w repozytoriach i potokach kompilacji zapobiega wyciekom na wczesnym etapie; w przypadku incydentu centralny Proces odwołania Szybka zmiana skompromitowanych kluczy na wszystkich platformach.
Automatyzacja i DevOps jako czynniki przyspieszające
Automatyzuję kompilacje, testy i wdrożenia za pomocą CI/CD, aby wersje działały niezawodnie i powtarzalnie. Infrastructure as Code opisuje każde środowisko w sposób deklaratywny, dzięki czemu mogę w sposób zrozumiały wersjonować zmiany i szybko je odtwarzać. Planuję kopie zapasowe w oparciu o czas i zdarzenia, regularnie sprawdzam przywracanie danych i dokumentuję cele RTO/RPO. Wdrożenia typu blue-green lub canary zmniejszają ryzyko, ponieważ uruchamiam nowe wersje przy niewielkim ruchu i w razie problemów natychmiast je cofam. Podsumowując, zmniejsza to liczbę błędów, przyspiesza uruchomienia i utrzymuje jakość stały wysoki poziom.

Migracja i strategie przechodzenia na nowe rozwiązania w środowiskach wielochmurowych
Dokładnie planuję przełączenia: z wyprzedzeniem obniżam wartości DNS-TTL, aby Cutover-Czas trwania operacji powinien być krótki, a ja testuję rollbacki w realistycznych warunkach. Migruję bazy danych za pomocą replikacji logicznej lub CDC, aż cel i źródło będą zsynchronizowane; następnie następuje krótkie zamrożenie zapisu i ostateczne przełączenie. W fazach podwójnego zapisu zapewniam idempotencję i rozwiązywanie konfliktów, aby nie powstały duplikaty. Usługi stanowe kapsułuję, aby zminimalizować ścieżki zapisu; pamięci podręczne i kolejki opróżniam w sposób kontrolowany. Flagi funkcji pozwalają mi precyzyjnie sterować ruchem w poszczególnych regionach/u dostawców i uruchamiać go krok po kroku. W przypadku systemów o wysokim stopniu krytyczności planuję Praca równoległa przez kilka dni – z wskaźnikami, które natychmiast uwidaczniają odchylenia.
Model kosztów i kontrola budżetu w chmurach wielochmurowych
Rozkładam koszty według Obciążenia, zespoły i środowiska, aby budżety pozostały zrozumiałe. Opłaty transferowe, klasy pamięci, typy obliczeniowe i rezerwacje mają wpływ na rachunek – dostosowuję kombinację do każdej aplikacji. W przypadku przewidywalnych obciążeń wybieram instancje z rabatem, a w przypadku szczytów – instancje na żądanie, dzięki czemu zachowuję równowagę między wydajnością a ceną. Alerty informują mnie o odchyleniach w euro, zanim zaskoczy mnie koniec miesiąca; tagowanie i raporty zapewniają przejrzystość aż do poziomu projektów. Regularne analizy rightsizingu, warstwowanie danych i archiwizacja zmniejszają zużycie i wzmacniają Przejrzystość kosztów.
FinOps w praktyce
Wprowadzam kontrolę kosztów do codziennej działalności: ustalam budżety dla poszczególnych produktów/środowisk, Prognozy aktualizuję co tydzień. Ekonomika jednostkowa (np. koszt na 1000 żądań, na zamówienie lub na klienta) pozwala zmierzyć efekty decyzji architektonicznych. Wytyczne dotyczące tagowania wymuszają pełną klasyfikację; zasoby bez tagów są automatycznie zgłaszane. Ustanawiam środki oszczędnościowe w postaci kodu: plany wyłączenia środowisk nieprodukcyjnych, Automatyczne skalowanie z limitami górnymi, zasadami cyklu życia pamięci i kompresją. Kwartalne przeglądy sprawdzają rezerwacje i wykorzystanie – to, co nie jest wykorzystywane, jest konsekwentnie redukowane.
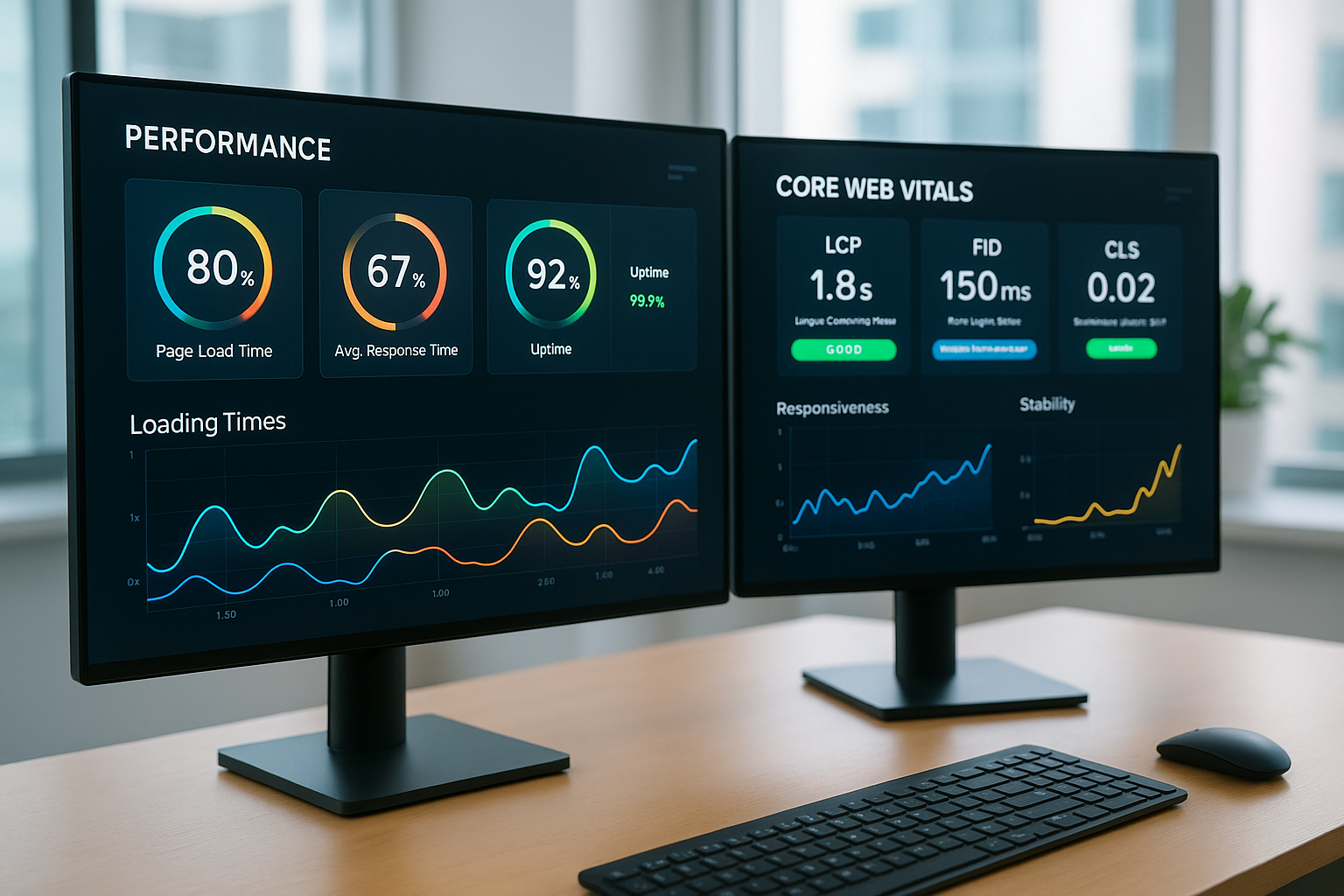
Optymalizacja wydajności i opóźnień
Usługi lokalizuję blisko Użytkownicy, aby czasy ładowania były odpowiednie, a cele konwersji pozostały osiągalne. Konfiguracje wieloregionalne skracają drogi, pamięci podręczne i sieci CDN odciążają zaplecze, a zadania asynchroniczne zapewniają responsywność interfejsów API. W przypadku aplikacji intensywnie przetwarzających dane rozdzielam ścieżki odczytu i zapisu, rozdzielam repliki i wykorzystuję instancje tylko do odczytu w regionach użytkowników. Kontrole stanu i testy syntetyczne nieustannie mierzą, gdzie występują wąskie gardła; na tej podstawie dokonuję ukierunkowanej optymalizacji. Ważne jest, aby uwzględnić lokalne specyficzne czynniki, takie jak święta lub szczyty, aby móc odpowiednio wcześnie skala.

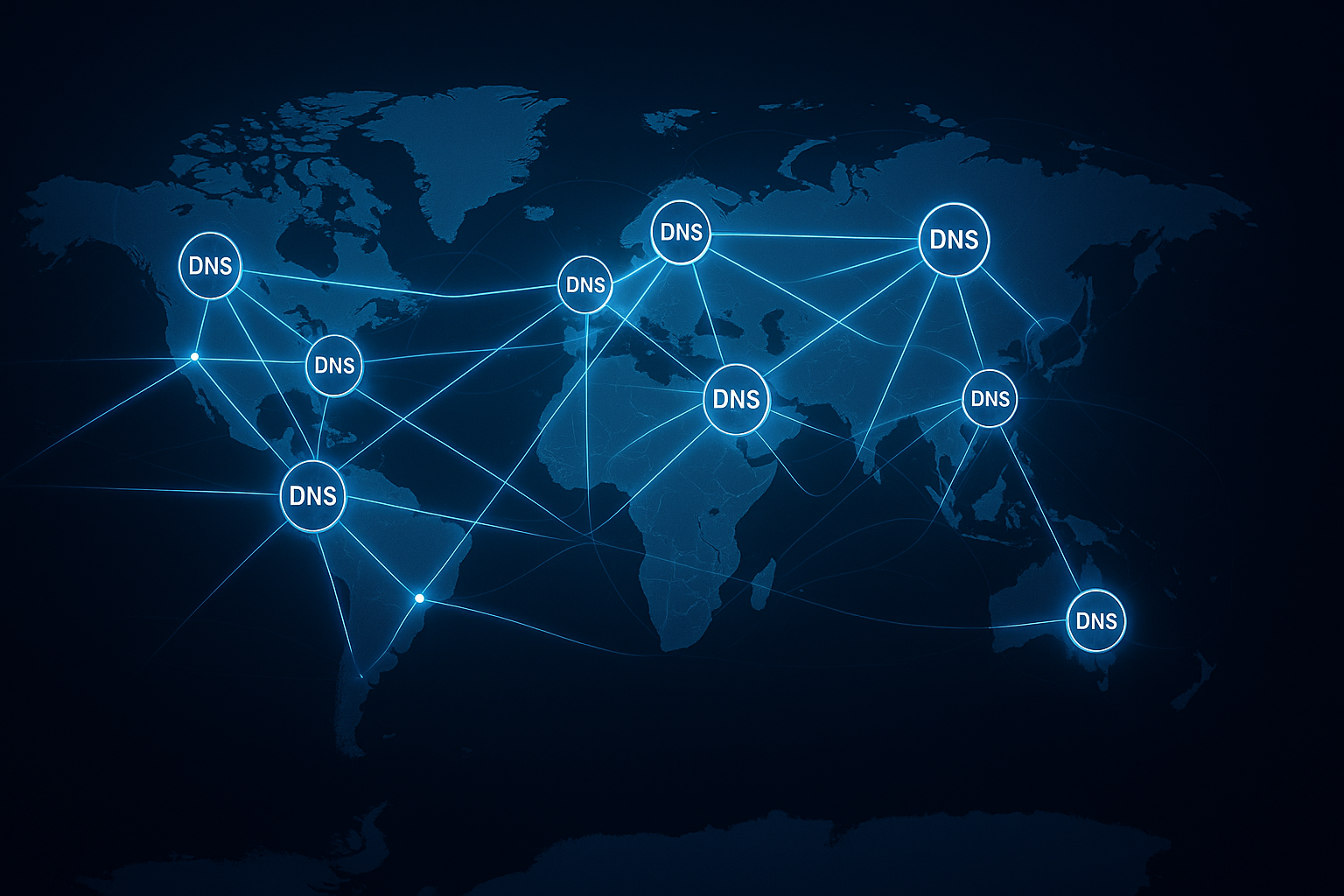
Projekt sieci i ścieżki danych
Planuję sieci z wyraźną segmentacją: Hub-and-Spoke-Topologie, prywatne punkty końcowe i restrykcyjne zasady dotyczące ruchu wychodzącego zapobiegają tworzeniu się cieniowych systemów informatycznych. Połączenia między chmurami realizuję za pomocą peeringu/interkonektu lub VPN/SD-WAN – w zależności od przepustowości, opóźnień i zgodności. Zasady zerowego zaufania, mTLS i ciągłe uwierzytelnianie chronią usługi nawet w przypadku rozproszonej eksploatacji. W przypadku ścieżek o dużym natężeniu danych minimalizuję ruch poprzeczny, stosuję kompresję i transfery wsadowe oraz stale monitoruję koszty wychodzące. Utrzymuję ścieżki obserwowalny (dzienniki przepływu, metryki L7), aby szybko wykrywać anomalie.
Przepływy pracy w agencji: od przygotowania do odzyskiwania danych po awarii
Oddzielam się Inscenizacja, testowanie i produkcja są przejrzyste, dzięki czemu wydania pozostają przewidywalne. Lokalne środowiska programistyczne – na przykład z DevKinsta – dobrze odzwierciedlają ustawienia produkcyjne, przyspieszają pracę zespołu i zmniejszają liczbę błędów przed uruchomieniem [12]. W przypadku kopii zapasowych stawiam na kilka lokalizacji i wersjonowanie; regularnie testuję przywracanie danych, aby zachować RTO/RPO. Podręczniki DR zawierają jasne kroki, role i ścieżki komunikacyjne, aby w razie awarii nie doszło do chaosu. W ten sposób niezawodność przestaje być wyjątkiem, a staje się rutyną i pozostaje stabilna dla wielu dostawców [1][3].
Typowe scenariusze z praktyki
Agencje z wieloma klientami rozdzielają Klienci Ścisłe: projekty krytyczne dla bezpieczeństwa są realizowane w regionach DE, kampanie o dużym natężeniu ruchu w lokalizacjach o niskiej latencji. Projekty WordPress wykorzystują oddzielne środowiska stagingowe i produkcyjne, automatyczne testy i rollbacki w celu szybkiego publikowania. Międzynarodowe zespoły pracują z zasobami specyficznymi dla danego regionu i przestrzegają wytycznych dotyczących danych obowiązujących na danym rynku. Architektury hybrydowe łączą dedykowany hosting baz danych z elastycznymi usługami w chmurze dla szczytowego obciążenia. Na fazy uruchamiania planuję tymczasowe moce przerobowe i po zakończeniu kampanii skaluję je z powrotem – w ten sposób oszczędzam koszty i utrzymuję Wydajność stabilny.

Przegląd dostawców usług hostingowych obsługujących wiele chmur
Porównuję dostawców na podstawie Integracja, narzędzia programistyczne, zarządzanie klientami, wydajność i funkcje zgodności. W wyborze operacyjnym pomagają mi testy porównawcze i praktyczne, w połączeniu z jasnym spojrzeniem na usługi i koszty. Szeroki przegląd oprogramowania sterującego zapewnia mi Porównanie narzędzi 2025, aby sprawdzić kluczowe funkcje i integracje. Poniższa tabela podsumowuje typowe mocne strony i pokazuje, w jaki sposób ustalam priorytety dla konfiguracji agencji. Ważne: należy regularnie weryfikować wyniki, ponieważ oferty, ceny i Cechy zmieniać się.
| Dostawca | Integracja wielu chmur | Wydajność | Zarządzanie klientami | Narzędzia deweloperskie | RODO/ISO | Zalecenie |
|---|---|---|---|---|---|---|
| webhoster.de | Tak (zwycięzca testu) | Top | Rozległy | Silny | Tak (DE, ISO) | 1 |
| Kinsta | Częściowo | Wysoki | Bardzo dobry | Bardzo dobry | Częściowo | 2 |
| Mittwald | Możliwe | Dobry | Dobry | Dobry | Tak (DE, ISO) | 3 |
| Hostinger | Częściowo | Dobry | Dobry | Dobry | Częściowo | 4 |
Systematyczne podejście do niezawodności
Aktywnie planuję dostępność, zamiast pozostawiać ją przypadkowi – dzięki Redundancja o dostawcach, strefach i regionach. Kontrole stanu, automatyczne przełączanie i replikowane strumienie danych zapewniają ciągłość działania usług, nawet jeśli część z nich ulegnie awarii [3]. Runbooki definiują ścieżki eskalacji, kanały komunikacji i granice decyzyjne na krytyczne minuty. Podczas ćwiczeń trenuję realistyczne scenariusze, mierzę RTO/RPO i stopniowo ulepszam procesy. Pomocne wytyczne i dalsze przemyślenia dostarcza mi artykuł na temat Niezawodność w przedsiębiorstwach, który wykorzystuję do planowania.
Inżynieria niezawodności w praktyce
Definiuję SLI i SLO dla ścieżek podstawowych (np. opóźnienie p95, wskaźnik błędów, dostępność) oraz świadomie zarządzam budżetami błędów. Wersje, które wyczerpują budżety, są hamowane, priorytetem jest stabilność. Prowadzę Game Days i eksperymenty z chaosem w środowisku stagingowym/produkcyjnym o kontrolowanym zakresie: awarie stref, blokowanie zależności zewnętrznych, wprowadzanie opóźnień. Analizy post mortem są bezstronne i kończą się weryfikowalnymi działaniami. W ten sposób odporność staje się mierzalna i jest stale ulepszana – we wszystkich dostawcach.
Zespół, procesy i dokumentacja
Organizuję konta/strefy docelowe według Mandaty i środowiskach, stwórz katalog usług z zatwierdzonymi modułami (plany baz danych, stosy obserwowalności, wzorce sieciowe). Golden Paths opisują zalecane ścieżki od repozytorium do eksploatacji, aby zespoły mogły szybko rozpocząć pracę i przestrzegać standardów. Zasady dyżurów, dyżury telefoniczne i jasne przekazywanie zadań między agencją a klientem pozwalają uniknąć luk. Dokumentacja jest wersjonowana obok kodu (runbooki, architektury, Protokoły decyzji) i jest aktualizowana w recenzjach – dzięki temu konfiguracje pozostają zrozumiałe i możliwe do kontroli.
Unikanie antywzorców
- nadmierna różnorodność: Zbyt wielu dostawców/usług zwiększa złożoność – standaryzuję podstawowe elementy.
- Ukryte uzależnienie: Zastrzeżone funkcje zarządzane bez abstrakcji utrudniają zmianę – izoluję zależności od dostawców.
- Nieprawidłowe IAM: Niespójne role prowadzą do luk w bezpieczeństwie – harmonizuję modele ról.
- niekontrolowany wzrost ilości danych: Kopie bez cyklu życia generują koszty – wprowadzam zasady dotyczące przechowywania i archiwizacji.
- Brak testów: Plany DR bez ćwiczeń są bezużyteczne – regularnie ćwiczę przełączanie awaryjne i dokumentuję to.
Plan na 30/60/90 dni na początek
W ciągu 30 dni definiuję cele, SLO, ramy budżetowe i wybieram aplikację pilotażową. Konfiguruję podstawowe IaC, CI/CD i tagowanie. W ciągu 60 dni buduję dwóch dostawców Wdrażam obserwowalność, zarządzanie tajemnicami i pierwsze ćwiczenia DR w warunkach zbliżonych do produkcyjnych; testy migracji przebiegają równolegle. Po 90 dniach następuje produktywne przełączenie pilotażowego projektu, regularnie rozpoczynają się przeglądy FinOps, a Golden Paths są wdrażane w kolejnych zespołach. Następnie skaluję wzorce, automatyzuję więcej i ograniczam specjalne rozwiązania – z jasnymi wskaźnikami jakości, szybkości i kosztów.

Moje podsumowanie dla agencji i programistów
Silny Strategia Rozdzielam odpowiedzialność, koszty i technologie między wiele podmiotów – zmniejsza to ryzyko i pozostawia otwarte możliwości. Rozpoczynam w sposób ustrukturyzowany: wyjaśniam wymagania, sprawdzam dostawców, testuję migrację, ustalam zasady zarządzania i wdrażam automatyzację. Wydajność, niezawodność i zgodność z przepisami zyskują jednocześnie, gdy świadomie łączę regiony, usługi i ścieżki danych [1][3][10]. Dzięki centralnemu monitorowaniu, jasnym budżetom i powtarzającym się ćwiczeniom DR działalność pozostaje pod kontrolą. Kto teraz inwestuje w wiedzę, narzędzia i jasne procesy, zabezpiecza dziś Niezależność jutra.