 Przejdź do treści
Przejdź do treści 
Pokażę ci, jak utworzyć Analiza czasu odpowiedzi serwera w taki sposób, aby TTFB, TTI, FCP i LCP dostarczały prawdziwych informacji, a nie tylko szumu pomiarowego. Robiąc to, oceniam Wartości progowe realistycznie, prawidłowo skategoryzować przyczyny i opracować środki, które zauważalnie poprawią czas ładowania i interaktywność.
Punkty centralne
Poniższe kluczowe stwierdzenia pomogą ci jasno określić priorytety i wiarygodnie zinterpretować wyniki.
- TTFBSygnał startowy dla wydajności serwera, docelowo zwykle poniżej 600 ms
- TTILiczy się interaktywność, a nie tylko widoczna treść
- PrzyczynyOpóźnienie, obciążenie serwera, baza danych, skrypty, wtyczki
- NarzędziaPSI, Lighthouse, WebPageTest z odczytem kontekstowym
- HostingStos, buforowanie, CDN i decyzja o lokalizacji

Co tak naprawdę mierzy TTFB i jak oceniam tę liczbę
TTFB zaczyna się od żądania i kończy na pierwszym bajcie, który przeglądarka otrzymuje z serwera, a ja czytam to tak Zakres czasu nie izolowane. Liczba ta obejmuje rozpoznawanie DNS, uzgadnianie TCP, TLS, przetwarzanie serwera i wysyłanie pierwszych bajtów, dlatego używam wartości Łańcuch kroków, a nie tylko wartość końcową. Zasadniczo, jeśli TTFB jest stale poniżej około 600 ms, odpowiedź serwera jest zwykle dobrym dopasowaniem. Oceniam pojedyncze wartości odstające inaczej niż serie powolnych odpowiedzi, ponieważ wzorce mówią mi więcej niż pojedynczy wynik. Nie unikam dogłębnych analiz, zamiast tego dzielę ścieżkę od klienta do źródła na sekcje i porównuję je z logami, statystykami CDN i monitorowaniem hostingu. Aby uzyskać informacje na temat konfiguracji pomiarów i pułapek, zapoznaj się z kompaktowym przewodnikiem Prawidłowy pomiar TTFBktóry jasno określa typowe źródła błędów.
TTI wyjaśniło jasno: interaktywność zamiast zwykłego renderowania
TTI opisuje czas, od którego użytkownicy mogą wykonywać dane wejściowe bez opóźnień, i oceniam je Interaktywność ściśle oddzielone od widocznej struktury. Szybki FCP bez użytecznych przycisków jest mało użyteczny, jeśli długie zadania blokują główny wątek i kliknięcia utkną; dlatego mierzę Zachowanie w odpowiedzi na wejściach. Długie zadania JavaScript, zasoby blokujące renderowanie i zbędne skrypty innych firm zauważalnie wydłużają TTI. Dzielę skrypty, ładuję niekrytyczne zadania przez async lub odraczam i przenoszę ciężkie zadania za pierwszą interakcją. Dzięki temu strona jest szybsza w użyciu, nawet jeśli poszczególne zasoby nadal się ładują, co sprawia, że korzystanie z niej jest znacznie przyjemniejsze.
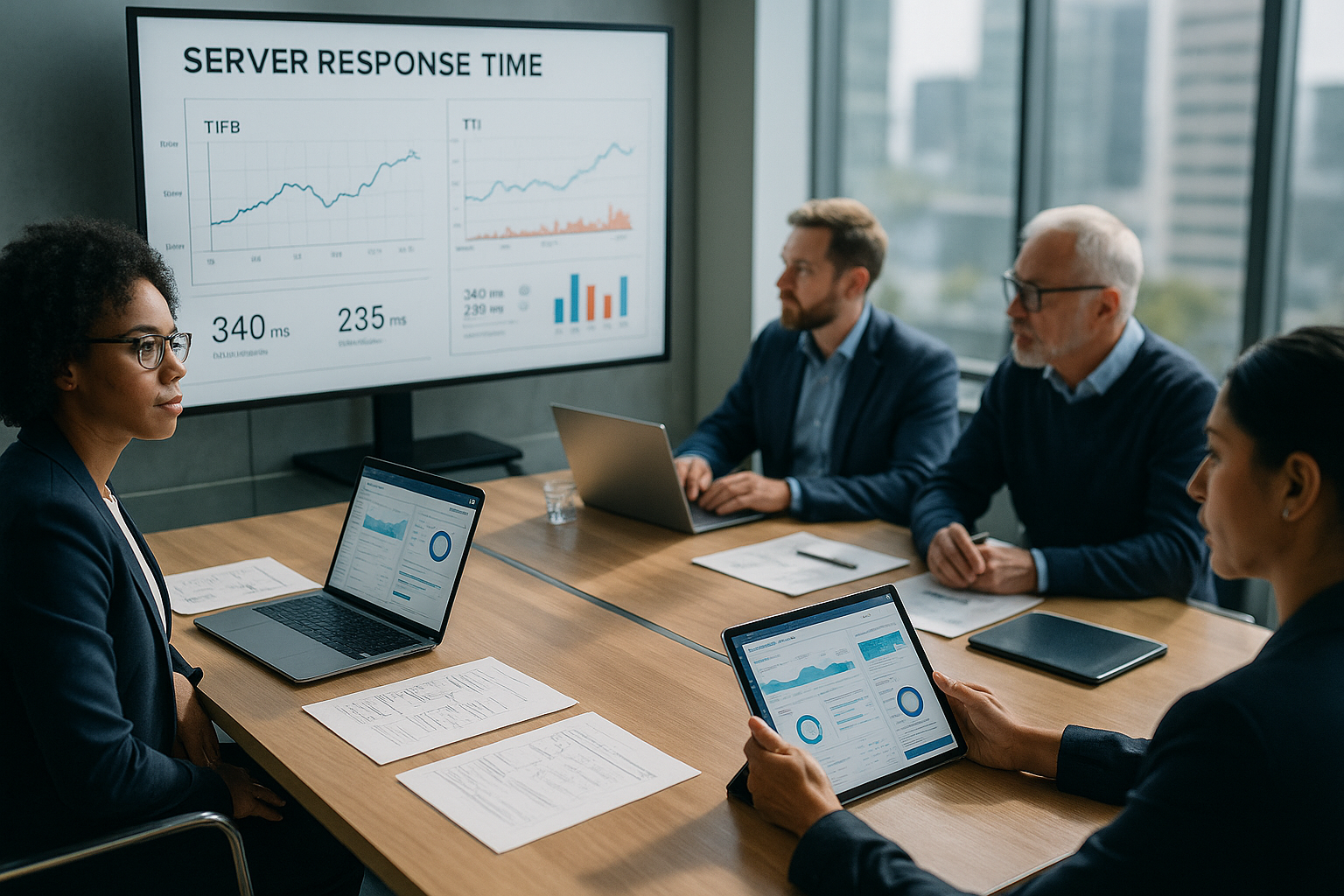
Interakcja TTFB, FCP, LCP i TTI
Wysoki TTFB automatycznie opóźnia FCP i LCP, ponieważ bez pierwszego bajtu nie ma Renderowanie Ogranicza to również TTI, jeśli krytyczne skrypty są gotowe później. Analizuję zatem przyczynowość: jeśli TTFB tymczasowo wzrasta, opóźnienie jest kontynuowane w FCP i LCP, co widzę na wykresach wodospadowych. Jeśli FCP i LCP są solidne, ale TTI pozostaje w tyle, problem zazwyczaj leży w JavaScript i wykorzystanie wątków. W przypadku WordPressa kreatory stron, wiele wtyczek i rozbudowane motywy często prowadzą do ciężkich pakietów, które specjalnie odchudzam. Tylko wtedy, gdy zależności są jasne, podejmuję właściwe środki zamiast leczyć objawy.
Dane terenowe vs laboratoryjne: Porównuję rzeczywiste użytkowanie z testami syntetycznymi
Dokonuję ścisłego rozróżnienia między Dane laboratoryjne (kontrolowane środowisko, powtarzalność) i Dane terenowe (prawdziwi użytkownicy, prawdziwe urządzenia i sieci). W przypadku decyzji liczę wartości P75 z pomiarów terenowych, ponieważ wygładzają one wartości odstające i odpowiadają typowemu doświadczeniu użytkownika. Segmentuję również według typu urządzenia (low-end Android vs. high-end desktop), regionu i jakości sieci, ponieważ ta sama witryna pokazuje dwa zupełnie różne oblicza w zależności od tego, czy jest to 3G z dużym opóźnieniem, czy światłowód. Używam danych laboratoryjnych do Przyczyny i zweryfikować zmiany w krótkim okresie; dane terenowe pokazują, czy optymalizacje są skuteczne we wszystkich obszarach. Porównuję serie czasowe zamiast pojedynczych wartości, sprawdzam pory dnia (szczyty obciążenia), czasy zwolnienia i efekty sezonowe. Ważne jest dla mnie również oddzielenie zimno oraz ciepły Pamięci podręczne: Porównanie A/B bez identycznych stanów pamięci podręcznej prowadzi do fałszywych wniosków, zwłaszcza w przypadku TTFB i LCP.
Diagnoza: Jak znaleźć wąskie gardła w kilka sekund
Każdą analizę rozpoczynam od powtarzalnych pomiarów na komputerach stacjonarnych i urządzeniach mobilnych, zmieniam profile sieciowe i przyglądam się Wodospady zanim wyciągnę jakiekolwiek wnioski. Następnie sprawdzam dzienniki serwera, trafienia w pamięci podręcznej, obciążenie procesora i we/wy, a także potencjalne problemy z blokadami w bazie danych, ponieważ te punkty mają duży wpływ na TTFB. W przypadku diagnostyki front-endu pracuję ze śladami lighthouse i wideo WebPageTest, aby wizualizować blokady zamiast polegać na przeczuciu. Spójny pulpit nawigacyjny pomaga mi zobaczyć trendy zamiast migawek; porównanie pasuje do tego PSI i Lighthousektóra wyraźnie oddziela środowiska pomiarowe i metryki. Ta kombinacja daje mi szybkie wskazanie, czy sieć, serwer lub skrypty są odpowiedzialne za większość czasów oczekiwania i oszczędza mi dużo czasu później.

Czas serwera i ślady: Sprawiam, że niewidoczne sekcje stają się mierzalne
Aby TTFB nie stał się czarną skrzynką, używam Taktowanie serwera-i skorelować je z logami aplikacji. Pozwala mi to zobaczyć udziały routingu, szablonów, braku pamięci podręcznej, zapytań do bazy danych, zewnętrznych interfejsów API i renderowania. Na poziomie sieci oddzielam DNS, TCP, TLS i kolejkowanie żądań; wahania czasu TLS często wskazują na brak wznowienia sesji lub nieoptymalne zszywanie szyfrów/OCSP. Zwracam również uwagę na Ponowne użycie połączenia z HTTP/2/3, ponieważ niepotrzebne uściski dłoni wydłużają łańcuchy opóźnień. W śladach identyfikuję wzorce "piłokształtne" (zmieniające się stany pamięci podręcznej), skoki opóźnień po wdrożeniach (zimne uruchamianie pamięci podręcznych) i zapytania N + 1 w zapleczu. Ta przejrzystość zapobiega optymalizacji na niewłaściwym końcu.
Najczęstsze przyczyny długich czasów reakcji
Przeciążona maszyna ze zbyt małą ilością procesora lub pamięci RAM powoduje wzrost TTFB, a ja rozpoznaję to po wysokim poziomie Wykorzystanie w godzinach szczytu i zmiennych opóźnieniach. Niewydajne zapytania do bazy danych wydłużają przetwarzanie serwera, co dokumentuję za pomocą dzienników zapytań i kontroli indeksów, a następnie rozwiązuję poprzez optymalizację lub buforowanie. Duże lub niekrytyczne skrypty, które są ładowane wcześnie, blokują ścieżki renderowania i tworzą sztuczne opóźnienia, dlatego wykluczam je z krytycznego przetwarzania. Faza remis. Duży ruch bez odpowiedniego buforowania zużywa zasoby, a brak bliskości CDN zauważalnie zwiększa opóźnienia. Wywołania stron trzecich, które odpowiadają bardzo późno, również wyczerpują TTI, co łagodzę za pomocą strategii limitu czasu i leniwego ładowania.
Strategia hostingu: co musi zapewniać szybki stos
Zwracam uwagę na NGINX lub nowoczesne stosy HTTP, aktualne wersje PHP, OPCache, buforowanie obiektów, Brotli, TLS 1.3 i a CDN-connection, ponieważ te komponenty znacząco kształtują TTFB i TTI. WordPress czerpie ogromne korzyści z pamięci podręcznej po stronie serwera oraz rozsądnej konfiguracji bazy danych i Redis, co szybko zauważyłem w testach obciążenia. Ponadto istnieje czysta pamięć masowa z wysokim IOPS, dzięki czemu pliki multimedialne i pliki pamięci podręcznej nie zwlekają; wydajność dysku ma bezpośredni wpływ na Czasy reakcji. W porównaniach, zoptymalizowane stosy WordPress konsekwentnie działają lepiej niż ogólne pakiety współdzielone. Skutkuje to konfiguracją, która zapewnia krótkie czasy odpowiedzi nawet pod obciążeniem, a jednocześnie pozostaje niezawodna.
| Dostawca | Czas odpowiedzi serwera (TTFB) | Wydajność | Optymalizacja WordPress |
|---|---|---|---|
| webhoster.de | 1 (zwycięzca testu) | Bardzo wysoki | Doskonały |
| Inni dostawcy | 2-5 | Zmienna | Średni do dobrego |

Strategie buforowania w szczegółach: Sprawiam, że architektura pamięci podręcznej jest odporna
Świadomie projektuję klucze pamięci podręcznej (w tym język, urządzenie, walutę, status logowania) i unikam niepotrzebnych kluczy pamięci podręcznej. Różne-eksplozje przez pliki cookie i nagłówki. Tam, gdzie to możliwe, ustawiam Kontrola pamięci podręcznej z rozsądnymi wartościami TTL, stale-while-revalidate oraz stale-if-error aby zaabsorbować szczyty obciążenia i przerwy w działaniu mostu. Używam ETagów selektywnie, nie odruchowo - jeśli Origin i tak musi obliczyć, walidacja często nie ma przewagi nad mocnym uderzeniem. W przypadku stron dynamicznych używam Dziurkowanie (ESI/fragment cache), dzięki czemu 95% dokumentu wychodzi z pamięci podręcznej i tylko spersonalizowane bloki są świeżo renderowane. Kontroluję procesy oczyszczania za pomocą kluczy zastępczych, aby konkretnie unieważniać zamiast opróżniać całe strefy. Dla ciepłych pamięci podręcznych planuję Ogrzewanie wstępne-pracy po wdrożeniu, aby pierwszy użytkownik nie ponosił całkowitych kosztów zimnego startu.
Konkretne optymalizacje TTFB, które wchodzą w życie natychmiast
Aktywuję buforowanie pełnych stron z rozsądnymi TTL i dziurkowaniem dla dynamicznych części, ponieważ każda Schowek-Współczynnik trafień zmniejsza obciążenie serwera. CDN z buforowaniem brzegowym zmniejsza odległość i minimalizuje szczyty opóźnień, szczególnie w przypadku międzynarodowych odbiorców. Optymalizuję zapytania do bazy danych za pomocą indeksów, przygotowanych instrukcji i refaktoryzacji zapytań przed skalowaniem sprzętu; dzięki temu łańcuch odpowiedzi jest bardziej przejrzysty szczuplejszy. Zastępuję ciężkie wtyczki lub wyrównuję je, aby zaoszczędzić czas PHP. Sprawdzam również lokalizację i routing, ponieważ liczy się odległość: Tło tego podsumowuję w tym przewodniku po Lokalizacja serwera i opóźnienie zwięzłe podsumowanie.
INP zamiast TTI: Jak oceniam interaktywność w terenie?
Nawet jeśli używam TTI w laboratorium, orientuję się w terenie poprzez INP (Interakcja do następnego malowania). INP mierzy najdłuższą istotną interakcję wizyty i przedstawia zauważalne zawieszenia wyraźniej niż TTI. W praktyce moja wartość docelowa wynosi poniżej 200 ms (P75). Aby to osiągnąć, skracam procedury obsługi zdarzeń, unikam synchronicznych awarii układu, dzielę kosztowne obliczenia i odkładam pracę na później. Web Workerjeśli to możliwe. Oddzielam renderowanie od zapytań o dane, pokazuję optymistyczny interfejs użytkownika i nigdy nie blokuję pętli głównego wątku długotrwałymi zadaniami. Oswajam frameworki z podziałem kodu i wyspa-Dzięki temu cała strona nie musi być nawilżana jednocześnie. Rezultat: Przyciski reagują bezpośrednio, dane wejściowe nie są "połykane", a postrzegana prędkość wzrasta.
Redukcja TTI: Eliminacja blokowania renderowania i długich zadań
Zmniejszam krytyczny CSS do minimum, ładuję resztę za pomocą leniwego lub atrybutu mediów i przenoszę JS z odroczeniem/asynchronizacją ze ścieżki, dzięki czemu główny wątek pozostaje wolny. Dzielę długie zadania tak, aby żaden blok nie trwał dłużej niż 50 ms, co sprawia, że wejścia są zauważalnie responsywne. Skrypty innych firm ładuję tylko po interakcji lub za pomocą budżetów wydajności, aby niepotrzebnie nie rozciągały TTI. Zmniejszam rozmiar obrazów po stronie serwera i dostarczam nowoczesne formaty, aby zmniejszyć obciążenie procesora w kliencie i skrócić transfery sieciowe. Buforuję krytyczne wywołania API, aby interfejs użytkownika nie czekał na zewnętrzne usługi, które czasami się opóźniają.

Priorytetyzacja front-endu: kontroluję, co dzieje się najpierw
Ustawiłem Obciążenie wstępne specjalnie dla zasobu LCP, użyj priorytet pobierania i podpowiadanie priorytetów zamiast ślepego wstępnego ładowania i definiowania realistycznych budżety zasobów. Czcionki krytyczne ładuję wąsko i z font-display: swapaby tekst był natychmiast widoczny. preconnect Używam go oszczędnie dla nieuniknionych dostawców zewnętrznych, aby pobrać uściski dłoni z wyprzedzeniem bez zatykania potoku. W przypadku obrazów pracuję z czystymi rozmiary-atrybuty, kompaktowy srcset-łańcuchy i decoding="async"dzięki czemu główny wątek pozostaje wolny. Pozwala mi to skierować przepustowość i procesor na to, co użytkownicy chcą zobaczyć i wykorzystać w pierwszej kolejności.
Unikanie błędów pomiarowych: Jak prawidłowo interpretować dane
Oddzielam czas odpowiedzi serwera od opóźnienia sieciowego, ponieważ mierzone są trafienia CDN, pamięci podręczne DNS i pamięci podręczne przeglądarek. fałszować może. Oceniam zimne starty, puste pamięci podręczne i pierwsze żądania po wdrożeniu oddzielnie od ciepłych faz. Dla mnie testy pojedynczego uruchomienia są przydatne tylko jako przybliżone wskazanie; w celu podjęcia decyzji zbieram wartości serii z tym samym Konfiguracja. Regiony, serwery proxy i ścieżki peeringu odgrywają rolę, dlatego też ustawiam punkty pomiarowe blisko użytkowników, zamiast testować lokalnie. Tylko wtedy, gdy środowisko pomiarowe, metryki i cel są jasno określone, mogę porównywać dane w czasie i ustalać wiarygodne benchmarki.
Głęboka optymalizacja specyficzna dla WordPressa: najpierw usuwam największe hamulce
Zaczynam od Audyt wtyczek/tematów i usuwać duplikaty. Opcje automatycznego ładowania w wp_options Utrzymuję go na niskim poziomie, aby każde żądanie nie ładowało niepotrzebnej ilości balastu. Migruję stany przejściowe do trwałej pamięci podręcznej obiektów (np. Redis), aby nie były obliczane podczas wywoływania strony. Na poziomie bazy danych sprawdzam indeksy pod kątem postmeta oraz opcje, usunąć N+1 zapytań i ustawić pamięć podręczną dla menu, zapytań i wyników fragmentów. The WP-Cron Planuję to po stronie serwera, aby zadania nie uruchamiały się losowo po uruchomieniu przez użytkownika. Optymalizuję konstruktory stron poprzez renderowanie po stronie serwera, dzieląc je na Częściowy-szablony i spójne odroczenie galerii multimediów. Rezultat: krótszy czas działania PHP, mniej zapytań, bardziej stabilne TTFB.
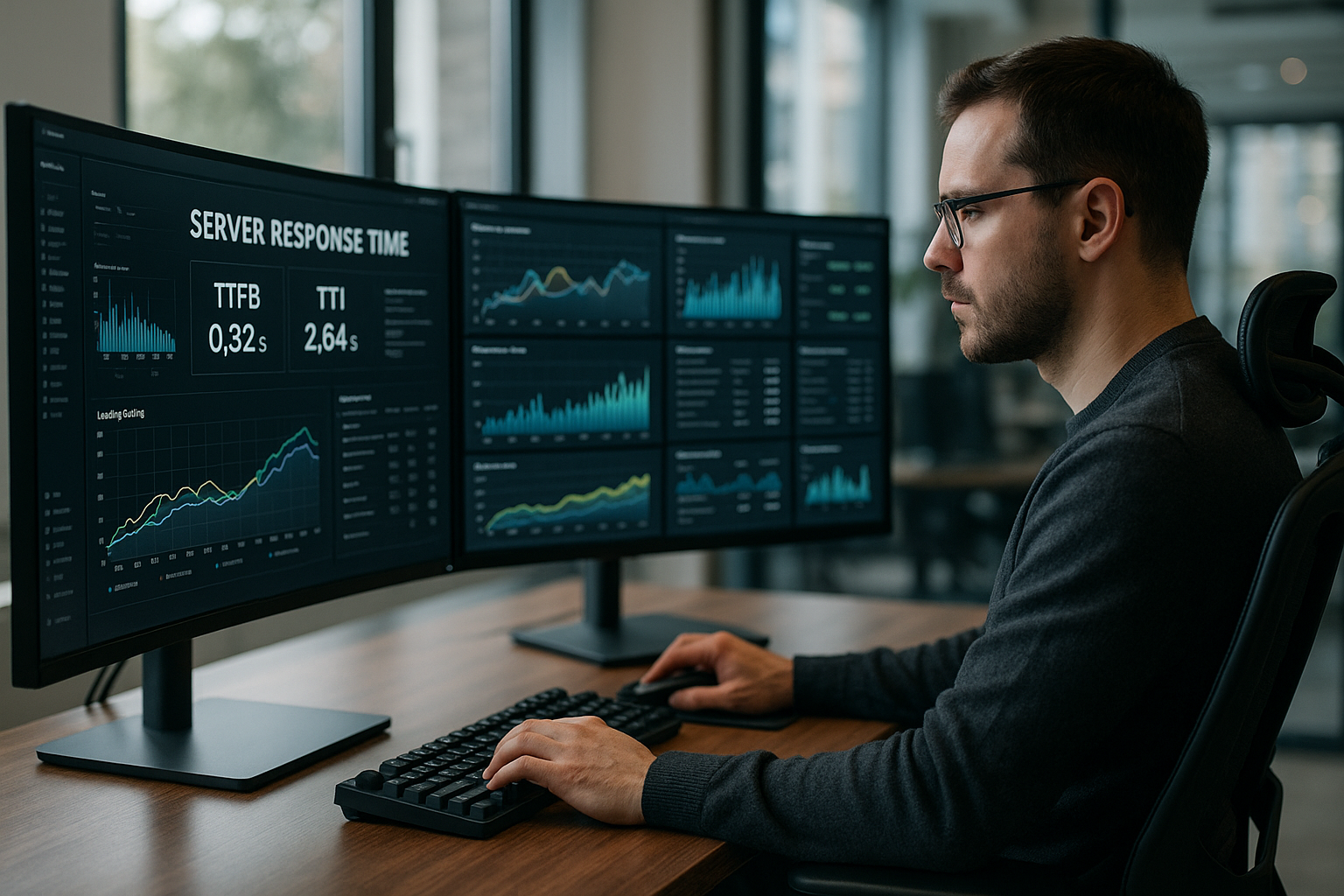
Backend i protokoły: wykorzystuję nowoczesne szlaki transportowe
Aktywuję HTTP/3 (QUIC) dla bardziej stabilnej wydajności przy utracie pakietów i sieci komórkowej, sprawdzam wznawianie sesji TLS i ustawiam Wczesne wskazówki (103)aby wcześniej uruchomić zasób LCP. Po stronie serwera wysyłam HTML streaming i wcześnie opróżniam krytyczne struktury, zamiast wyprowadzać wszystko po zakończeniu przetwarzania. Poziomy buforowania i kompresji danych wyjściowych dobieram tak, by zrównoważyć opóźnienia i przepustowość. W backendzie utrzymuję ciepły opcache, używam określonych ustawień JIT dla PHP i ustawiam limity dla współbieżnych pracowników, aby maszyna nie wpadła w swapping. Oddzielam usługi zewnętrzne od kolejek i pamięci podręcznych, aby żadne żądanie nie czekało na opóźniające się API innych firm.
Ciągłe pomiary, raportowanie i efekty SEO
Ustawiam budżety wydajności, sprawdzam alerty pod kątem wahań i rejestruję metryki w pulpitach nawigacyjnych, aby zespoły mogły szybko reagować. Regularne kontrole pokazują mi, czy aktualizacje, nowe wtyczki lub skrypty reklamowe przesuwają TTFB, FCP, LCP lub TTI. Google ocenia czas ładowania jako sygnał rankingowy, a zbyt długi czas odpowiedzi zauważalnie zmniejsza widoczność i konwersję, co wyraźnie widać w dziennikach i analizach. W przypadku TTFB używam progów poniżej 600 ms jako praktycznego celu, ale dostosowuję je w zależności od urządzenia, regionu i rodzaju treści, aby stwierdzenia pozostały aktualne. Przejrzyste raporty z jasnymi miarami zapewniają mi podstawę do ustalania priorytetów zaległości w rozsądny sposób.
SLI, SLO i przepływy pracy: Sprawiam, że wydajność jest zadaniem zespołowym
Definiuję wskaźniki poziomu usług (np. P75-LCP, P95-TTFB, poziom błędów) i uzgadniam je SLO na typ strony. Wprowadzam zmiany krok po kroku i oznaczam wdrożenia w pulpitach nawigacyjnych, aby korelacje stały się widoczne. Nie uruchamiam alertów dla poszczególnych wartości, ale dla trendów i naruszeń budżetu. Dokumentuję podręczniki odtwarzania dla typowych wzorców błędów (np. awarie pamięci podręcznej, rosnące blokady DB, przekroczenia limitu czasu stron trzecich), aby zespół mógł szybko działać w przypadku incydentu. Ta dyscyplina zapobiega ponownemu "spadkowi" wydajności po dobrych fazach i sprawia, że optymalizacje są zrównoważone - zarówno pod względem zawodowym, jak i organizacyjnym.
Podsumowanie: Jak analizować czas odpowiedzi serwera?
Zaczynam od TTFBSprawdzam cały łańcuch od DNS do pierwszego bajtu i porównuję zmierzone wartości z logami i profilami obciążenia. Następnie zabezpieczam TTI poprzez usunięcie blokady renderowania, rozbicie długich zadań i okiełznanie kodu stron trzecich. Łączę hosting, buforowanie i CDN w ukierunkowany sposób, tak aby odległość, I/O i przetwarzanie harmonizowały, a szczyty obciążenia były płynnie absorbowane. Narzędzia dostarczają mi wskazówek, ale decyzje podejmuję wyłącznie na podstawie powtarzalnych serii i przejrzystego środowiska pomiarowego, ponieważ ostatecznie liczy się spójność. W ten sposób doprowadzam czas reakcji serwera, interaktywność i widoczność do stabilnego poziomu, który robi wrażenie zarówno na użytkownikach, jak i wyszukiwarkach.


