 Przejdź do treści
Przejdź do treści 
Dobrze uzasadniona analiza TTFB pokazuje, dlaczego znacznik czasu pierwszego bajtu jest często błędnie interpretowany i w jaki sposób łączę pomiary z metrykami użytkownika w znaczący sposób. Wyjaśniam konkretnie, gdzie występują błędne interpretacje, w jaki sposób zbieram spójne dane i jakie optymalizacje stosuję. Percepcja faktycznie zwiększyć prędkość.
Punkty centralne
- TTFB opisuje uruchomienie serwera, a nie ogólną prędkość.
- Kontekst zamiast pojedynczej wartości: Odczytaj LCP, FCP, INP.
- Lokalizacja i sieć charakteryzują zmierzone wartości.
- Buforowanie i CDN zmniejszają opóźnienia.
- Zasoby i konfiguracja mają bezpośredni wpływ.

Krótkie wyjaśnienie TTFB: Zrozumienie łańcucha pomiarowego
TTFB mapuje czas od żądania do pierwszego zwróconego bajtu i składa się z kilku kroków, które nazywam Łańcuch pomiarowy muszą zostać uwzględnione. Obejmuje to rozpoznawanie DNS, uzgadnianie TCP, negocjacje TLS, przetwarzanie serwera i wysyłanie pierwszego bajtu. Każda sekcja może tworzyć wąskie gardła, co znacząco zmienia całkowity czas. Narzędzie pokazuje tutaj pojedynczą wartość, ale przyczyny leżą na kilku poziomach. Dlatego oddzielam opóźnienie transportu, odpowiedź serwera i logikę aplikacji, aby Źródła błędów wyraźnie przypisywalne.
Optymalizacja ścieżki sieciowej: DNS do TLS
Zacznę od nazwy: resolwery DNS, łańcuchy CNAME i TTL wpływają na szybkość rozpoznawania hosta. Zbyt wiele przekierowań lub resolver z dużym opóźnieniem dodają zauważalne milisekundy. Następnie liczy się połączenie: Zmniejszam liczbę podróży w obie strony dzięki strategiom keep-alive, TCP fast-open i szybkiemu udostępnianiu portów. W przypadku TLS sprawdzam łańcuch certyfikatów, zszywanie OCSP i wznawianie sesji. Krótki łańcuch certyfikatów i aktywowane zszywanie oszczędzają uściski dłoni, podczas gdy nowoczesne protokoły, takie jak HTTP/2 i HTTP/3, skutecznie multipleksują wiele żądań w jednym połączeniu.
Zwracam również uwagę na ścieżkę: IPv6 może mieć zalety w dobrze połączonych sieciach, ale słabe trasy peeringowe zwiększają jitter i utratę pakietów. W sieciach mobilnych każda podróż w obie strony odgrywa większą rolę, dlatego faworyzuję mechanizmy 0-RTT, ALPN i szybkie wersje TLS. Ważne jest dla mnie to, że optymalizacja transportu nie tylko przyspiesza TTFB, ale także stabilizuje wariancję. Stabilny zakres pomiarowy sprawia, że moje optymalizacje są bardziej powtarzalne, a decyzje bardziej wiarygodne.
3 najczęstsze błędne interpretacje
1) TTFB oznacza prędkość całkowitą
Niski TTFB niewiele mówi o renderowaniu, dostarczaniu obrazu lub wykonywaniu JavaScript, tj. o tym, co ludzie mogą zrobić bezpośrednio. Zobacz. Strona może wysłać pierwszy bajt na początku, ale później zawieść z powodu największej zawartości (LCP). Często obserwuję szybkie pierwsze bajty z powolną interaktywnością. Postrzegana prędkość pojawia się tylko wtedy, gdy pojawia się odpowiednia treść i reaguje. Właśnie dlatego widok z ustalonym TTFB łączy w sobie Rzeczywistość użytkowania od zmierzonej wartości.
2) Niski TTFB = dobry UX i SEO
Mogę sztucznie forsować TTFB, na przykład używając wczesnych nagłówków, bez dostarczania użytecznej zawartości, która jest tym, co jest prawdziwe. Wartość użytkowa nie wzrasta. Wyszukiwarki i ludzie cenią widoczność i użyteczność bardziej niż pierwszy bajt. Wskaźniki takie jak LCP i INP lepiej odzwierciedlają wrażenia z użytkowania strony. Skupienie się wyłącznie na TTFB ignoruje krytyczne etapy renderowania i interaktywności. Dlatego mierzę dodatkowo, aby decyzje mogły być oparte na Dane z trafnością.
3) Wszystkie wartości TTFB są porównywalne
Punkt pomiarowy, peering, obciążenie i odległość zniekształcają porównania, których trudno byłoby dokonać bez tych samych warunków ramowych. Stawka może. Serwer testowy w USA mierzy inaczej niż serwer we Frankfurcie. Wahania obciążenia między porankiem a wieczorem również zauważalnie zmieniają wyniki. Dlatego używam kilku przebiegów, co najmniej dwóch lokalizacji i różnych czasów. Tylko taki zakres zapewnia solidne Klasyfikacja wartości.

Syntetyczny vs. RUM: dwie perspektywy na TTFB
Łączę testy syntetyczne z monitorowaniem rzeczywistych użytkowników (RUM), ponieważ oba te podejścia odpowiadają na różne pytania. Syntetyka daje mi kontrolowane benchmarki z jasnymi ramami, idealne do testów regresji i porównań. RUM odzwierciedla rzeczywistość na różnych urządzeniach, w różnych sieciach i regionach oraz pokazuje, jak TTFB zmienia się w terenie. Pracuję z percentylami zamiast ze średnimi, aby rozpoznać wartości odstające i segmentować według urządzenia (mobilne/desktopowe), kraju i jakości sieci. Tylko wtedy, gdy wzorce zostaną znalezione w obu światach, oceniam przyczyny i środki jako solidne.
Co tak naprawdę wpływa na TTFB?
Wybór środowiska hostingowego ma duży wpływ na opóźnienia, IO i czas obliczeniowy, co jest bezpośrednio odzwierciedlone w TTFB pokazuje. Przeciążone systemy reagują wolniej, podczas gdy dyski SSD NVMe, nowoczesne stosy i dobre ścieżki peeringu pozwalają na krótkie czasy odpowiedzi. Konfiguracja serwera również ma znaczenie: nieodpowiednie ustawienia PHP, słaby opcache lub niewielka ilość pamięci RAM prowadzą do opóźnień. W przypadku baz danych zauważam powolne zapytania w każdym żądaniu, zwłaszcza w przypadku nieindeksowanych tabel. CDN zmniejsza odległość i obniża koszty. Opóźnienie dla zawartości statycznej i buforowanej.
PHP-FPM i optymalizacja runtime w praktyce
Sprawdzam menedżera procesów: zbyt mało pracowników PHP generuje kolejki, zbyt wielu wypiera cache z pamięci RAM. Równoważę ustawienia takie jak max_children, pm (dynamic/ondemand) i limity żądań w oparciu o rzeczywiste profile obciążenia. Utrzymuję ciepły i stabilny Opcache, zmniejszam narzut autoloadera (zoptymalizowane classmapy), aktywuję realpath cache i usuwam rozszerzenia debugowania w produkcji. Przenoszę kosztowne inicjalizacje do bootstrapów i cache'uję wyniki w cache'u obiektów. Skraca to czas między akceptacją gniazda a pierwszym bajtem bez konieczności poświęcania funkcjonalności.
Jak prawidłowo mierzyć TTFB
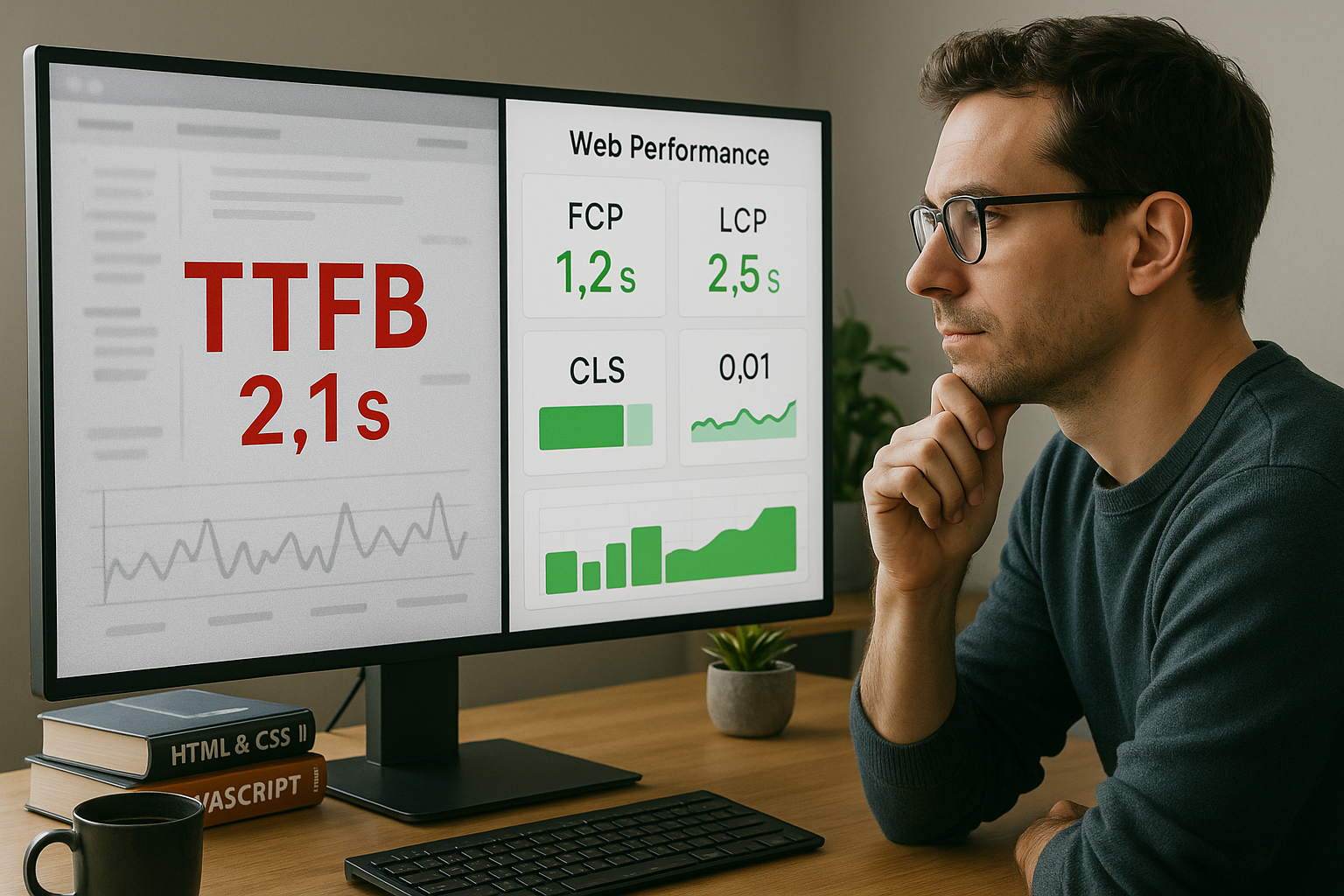
Testuję kilka razy, w różnym czasie, w co najmniej dwóch lokalizacjach i tworzę mediany lub percentyle, aby uzyskać wiarygodne wyniki. Podstawa. Sprawdzam również, czy pamięć podręczna jest ciepła, ponieważ pierwszy dostęp często trwa dłużej niż wszystkie kolejne. Koreluję TTFB z LCP, FCP, INP i CLS, aby wartość miała sens w ogólnym obrazie. Aby to zrobić, używam dedykowanych przebiegów dla HTML, krytycznych zasobów i treści stron trzecich. Dobrym punktem wyjścia jest ocena Core Web Vitalsponieważ są Percepcja użytkowników.
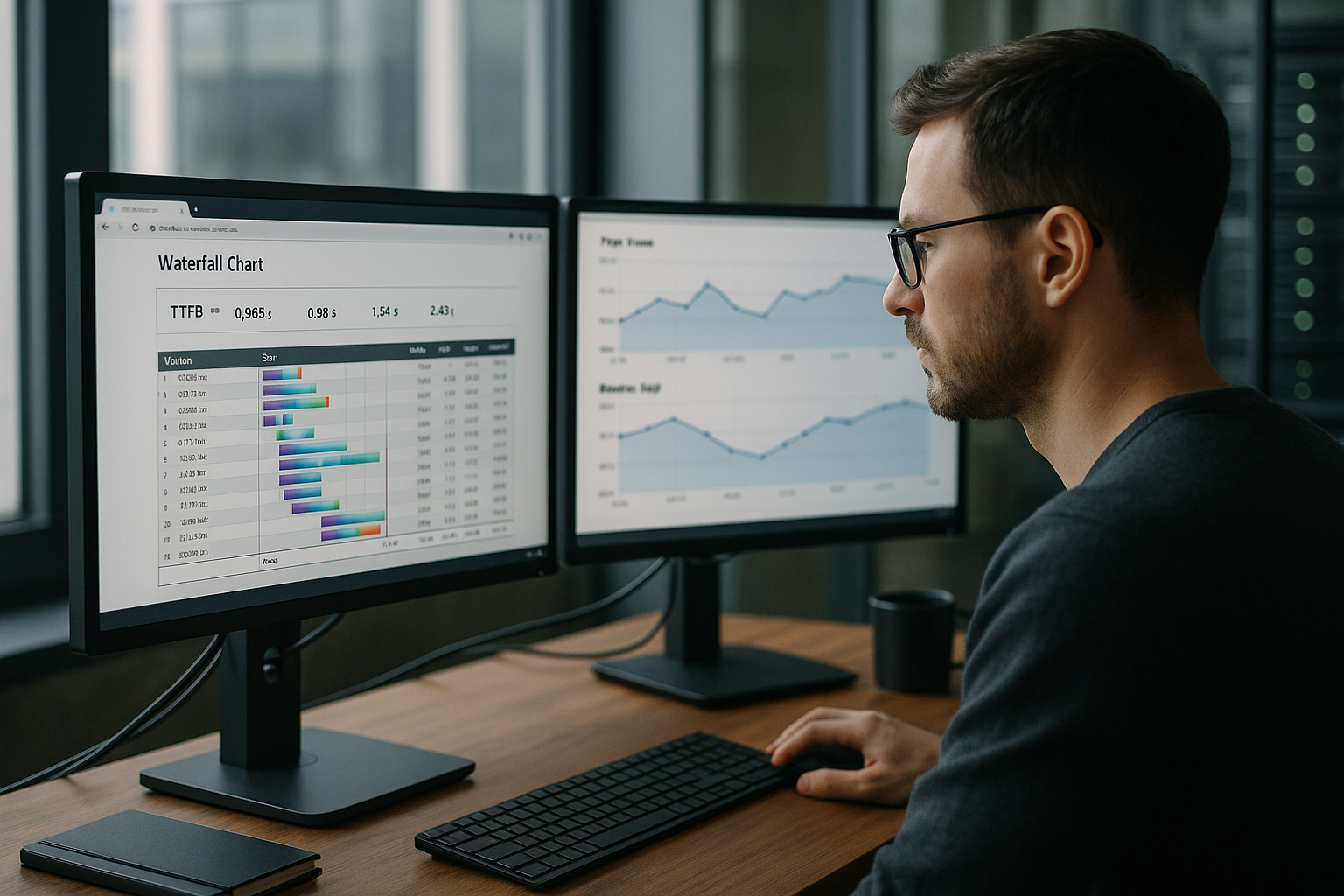
Czas serwera i identyfikowalność
Wysyłam również nagłówki czasu serwera, aby udziały czasowe były przejrzyste: np. dns, connect, tls, app, db, cache. Dodaję te same znaczniki do dzienników i dodaję identyfikatory śledzenia do żądań, dzięki czemu mogę śledzić poszczególne uruchomienia za pośrednictwem CDN, Edge i Origin. Taka szczegółowość zapobiega zgadywaniu: Zamiast stwierdzenia "TTFB jest wysokie" mogę sprawdzić, czy baza danych potrzebuje 180 ms, czy też Origin utknął w kolejce na 120 ms. Dzięki percentylom na trasę (np. szczegóły produktu vs. wyszukiwanie) definiuję jasne budżety i mogę zatrzymać regresje w CI na wczesnym etapie.
Najlepsze praktyki: Szybszy pierwszy bajt
Używam buforowania po stronie serwera dla HTML, dzięki czemu serwer może dostarczać gotowe odpowiedzi i CPU nie musi ponownie obliczać każdego żądania. Globalny CDN przybliża zawartość do użytkowników i zmniejsza odległość, czas DNS i routing. Aktualizuję PHP, bazę danych i serwer WWW, aktywuję Opcache i używam HTTP/2 lub HTTP/3 dla lepszego wykorzystania połączenia. Przenoszę drogie zewnętrzne wywołania API asynchronicznie lub buforuję je, aby pierwszy bajt nie czekał bezczynnie. Regularne profilowanie obejmuje powolne zapytania i Wtyczki które rozbrajam lub wymieniam.
Strategie buforowania w szczegółach: TTL, Vary i Microcaching
Dokonuję ścisłego rozróżnienia między dynamiką a cache'owaniem. HTML otrzymuje krótkie TTL i mikro-buforowanie (np. 5-30 s) dla szczytów obciążenia, podczas gdy odpowiedzi API z wyraźnymi nagłówkami kontroli pamięci podręcznej i ETagami mogą żyć dłużej. Używam Vary selektywnie: Tylko tam, gdzie język, pliki cookie lub agent użytkownika naprawdę generują różne treści. Zbyt szerokie klucze Vary niszczą współczynnik trafień. Z stale-while-revalidate dostarczam natychmiast i odświeżam w tle; stale-if-error utrzymuje stronę dostępną, jeśli backend się zawiesi. Ważne: Unikaj plików cookie w domenie głównej, jeśli nieumyślnie uniemożliwiają buforowanie.
W przypadku zmian planuję czyste usuwanie pamięci podręcznej za pomocą parametrów wersji lub skrótów treści. Ograniczam unieważnienia HTML do dotkniętych tras, zamiast uruchamiać globalne czyszczenie. W przypadku sieci CDN używam regionalnych rozgrzewek i osłony pochodzenia w celu ochrony serwera pochodzenia. Utrzymuje to stabilność TTFB nawet podczas szczytów ruchu bez konieczności nadmiernego zwiększania pojemności.
TTFB vs. doświadczenie użytkownika: ważne wskaźniki
Oceniam LCP dla największej widocznej zawartości, FCP dla pierwszej zawartości i INP dla odpowiedzi wejściowej, ponieważ te wskaźniki są doświadczeniem zauważalny make. Strona może mieć umiarkowane TTFB i nadal wyświetlać się szybko, jeśli ważne renderowanie odbywa się wcześnie. I odwrotnie, małe TTFB jest mało przydatne, jeśli skrypty blokujące opóźniają wyświetlanie. Używam Analiza latarni morskiejaby sprawdzić sekwencję zasobów, ścieżkę renderowania i priorytety. To pozwala mi zobaczyć, która optymalizacja naprawdę Pomaga.

Prawidłowe ustawienie priorytetów renderowania
Upewniam się, że krytyczne zasoby są przed wszystkim innym: Krytyczne CSS inline, fonty z font-display i rozsądnym preload/priorytetyzacją, obrazki w above-the-fold z odpowiednim fetchpriority. Ładuję JavaScript tak późno lub asynchronicznie, jak to możliwe i usuwam obciążenie głównego wątku, aby przeglądarka mogła szybko malować. Używam wczesnych podpowiedzi do wyzwalania wstępnego ładowania przed ostateczną odpowiedzią. Rezultat: Nawet jeśli TTFB nie jest idealne, strona działa znacznie szybciej dzięki wczesnej widoczności i szybkiej reakcji.
Unikanie błędów pomiarowych: typowe przeszkody
Ciepła pamięć podręczna zniekształca porównania, dlatego rozróżniam zimne i ciepłe żądania. oddzielny. CDN może również mieć nieaktualne lub niereplikowane krawędzie, co wydłuża pierwsze pobieranie. Sprawdzam wykorzystanie serwera równolegle, aby kopie zapasowe lub zadania cron nie miały wpływu na pomiar. Po stronie klienta zwracam uwagę na pamięć podręczną przeglądarki i jakość połączenia, aby zminimalizować efekty lokalne. Nawet resolwery DNS zmieniają opóźnienie, więc utrzymuję środowisko testowe jako stały.
Rozważ CDN, WAF i warstwy zabezpieczeń
Systemy pośredniczące, takie jak WAF, filtry botów i ochrona DDoS, mogą zwiększyć TTFB bez winy źródła. Sprawdzam, czy zakończenie TLS odbywa się na krawędzi, czy osłona jest aktywna i w jaki sposób reguły uruchamiają złożone kontrole. Limity szybkości, geofencing lub wyzwania JavaScript są często przydatne, ale nie powinny niezauważalnie przesuwać wartości mediany. Dlatego też oddzielnie mierzę zarówno trafienia krawędziowe, jak i chybienia pochodzenia, a także mam gotowe reguły wyjątków dla testów syntetycznych, aby odróżnić rzeczywiste problemy od mechanizmów ochrony.
Decyzje dotyczące hostingu, które się opłacają
Szybkie dyski SSD NVMe, wystarczająca ilość pamięci RAM i nowoczesne procesory zapewniają backendowi wystarczającą moc. Wydajnośćdzięki czemu odpowiedzi zaczynają się szybko. Skaluję pracowników PHP, aby dopasować ruch, aby żądania nie były kolejkowane. Wpływ tego wąskiego gardła często staje się widoczny dopiero pod obciążeniem, dlatego realistycznie planuję przepustowość. W celu praktycznego planowania, przewodnik po Prawidłowe planowanie pracowników PHP. Bliskość rynku docelowego i dobra sieć peeringowa również sprawiają, że Opóźnienie niski.

Procesy wdrażania i jakości
Traktuję wydajność jako cechę jakości w dostarczaniu: definiuję budżety dla TTFB, LCP i INP w potoku CI/CD i blokuję wydania z wyraźnymi regresjami. Wydania kanaryjskie i flagi funkcji pomagają mi dozować ryzyko i mierzyć je krok po kroku. Przed wprowadzeniem większych zmian przeprowadzam testy obciążeniowe, aby zidentyfikować limity pracowników, limity połączeń i blokady baz danych. Dzięki powtarzającym się testom dymu na reprezentatywnych trasach, natychmiast rozpoznaję pogorszenie - nie tylko wtedy, gdy nadejdzie szczyt. Pozwala mi to utrzymać zmierzoną poprawę w dłuższej perspektywie.
Tabela praktyczna: Scenariusze i środki pomiaru
Poniższy przegląd kategoryzuje typowe sytuacje i łączy zaobserwowane TTFB z innymi kluczowymi danymi liczbowymi i namacalnymi. Kroki. Używam ich do szybszego zawężania przyczyn i jasnego określania miar. Nadal ważne jest, aby sprawdzać wartości kilka razy i czytać wskaźniki kontekstowe. Zapobiega to podejmowaniu decyzji, które działają tylko na objawy i nie poprawiają percepcji. Tabela pomaga mi planować i analizować testy. Priorytety do ustawienia.
| Scenariusz | Obserwacja (TTFB) | Wskaźniki towarzyszące | Możliwa przyczyna | Konkretny środek |
|---|---|---|---|---|
| Pierwszy telefon rano | Wysoki | LCP ok, FCP ok | Zimna pamięć podręczna, budzenie DB | Rozgrzewanie pamięci podręcznej serwera, utrzymywanie połączeń DB |
| Szczyt ruchu | Zwiększa się skokowo | INP pogorszył się | Zbyt mało pracowników PHP | Zwiększenie liczby pracowników, outsourcing długich zadań |
| Globalny dostęp USA | Znacznie wyższy | LCP waha się | Odległość, podgląd | Aktywuj CDN, użyj pamięci podręcznej krawędzi |
| Wiele stron produktów | Niestabilny | FCP dobrze, LCP źle | Duże obrazy, brak wczesnych wskazówek | Optymalizacja obrazów, priorytetowe ładowanie wstępne |
| Interfejsy API innych firm | Zmienny | INP ok | Czas oczekiwania na API | Pamięć podręczna odpowiedzi, przetwarzanie asynchroniczne |
| Aktualizacja zaplecza CMS | Wyższy niż wcześniej | CLS bez zmian | Nowa wtyczka włącza hamulce | Profilowanie, zastępowanie lub łatanie wtyczek |
Podsumowanie: Kategoryzuj TTFB poprawnie w kontekście
Pojedyncza wartość TTFB rzadko wyjaśnia, jak strona się czuje, więc łączę ją z LCP, FCP, INP i rzeczywistością Użytkownicy. Dokonuję kilku pomiarów, synchronizuję lokalizacje i sprawdzam obciążenie, aby uzyskać spójne wyniki. Do szybkiego uruchamiania używam buforowania, CDN, aktualnego oprogramowania i szczupłych zapytań. Jednocześnie nadaję priorytet renderowaniu widocznych treści, ponieważ wczesna widoczność wyraźnie poprawia percepcję. W ten sposób moja analiza TTFB prowadzi do decyzji, które optymalizują Doświadczenie odwiedzających.


