 Saltar para o conteúdo
Saltar para o conteúdo 
Mostro especificamente como a otimização da latência, a arquitetura de alojamento e os caminhos de rede reduzem o tempo de resposta das aplicações globais e aumentam as conversões. Com CDN-Posso fornecer conteúdos a qualquer local em milissegundos, utilizando uma vasta gama de estratégias de armazenamento em cache e de encaminhamento.
Pontos centrais
- Distância minimizar: Servir os utilizadores perto dos centros de dados
- CDN implantação: Disponibilização de conteúdos em todo o mundo
- Armazenamento em cache Reforçar: Utilizar a cache do servidor e do browser
- Protocolos modernizar: HTTP/2, TLS 1.3, QUIC
- Monitorização estabelecer: Medir a TTFB e as rotas

O que significa latência no alojamento internacional?
A latência representa o tempo que um pacote de dados demora a viajar do servidor para o utilizador, e eu trato isto Milissegundos como um KPI rígido. Cada rota adicional, cada salto e cada atraso na rota de transporte custa receitas e satisfação mensuráveis. Para os projectos globais, o que conta mais é a proximidade com que levo o poder computacional e os dados ao grupo-alvo e a consistência dos percursos. Meço valores-chave como o tempo até ao primeiro byte (TTFB), o tempo de ida e volta (RTT) e o tempo de resposta do servidor para reconhecer rapidamente os pontos de estrangulamento. Se controlar ativamente estes valores, reduzirá visivelmente os tempos de carregamento e garantirá uma experiência de utilizador fiável com menos cancelamentos.
Como a distância, o encaminhamento e o peering influenciam a latência
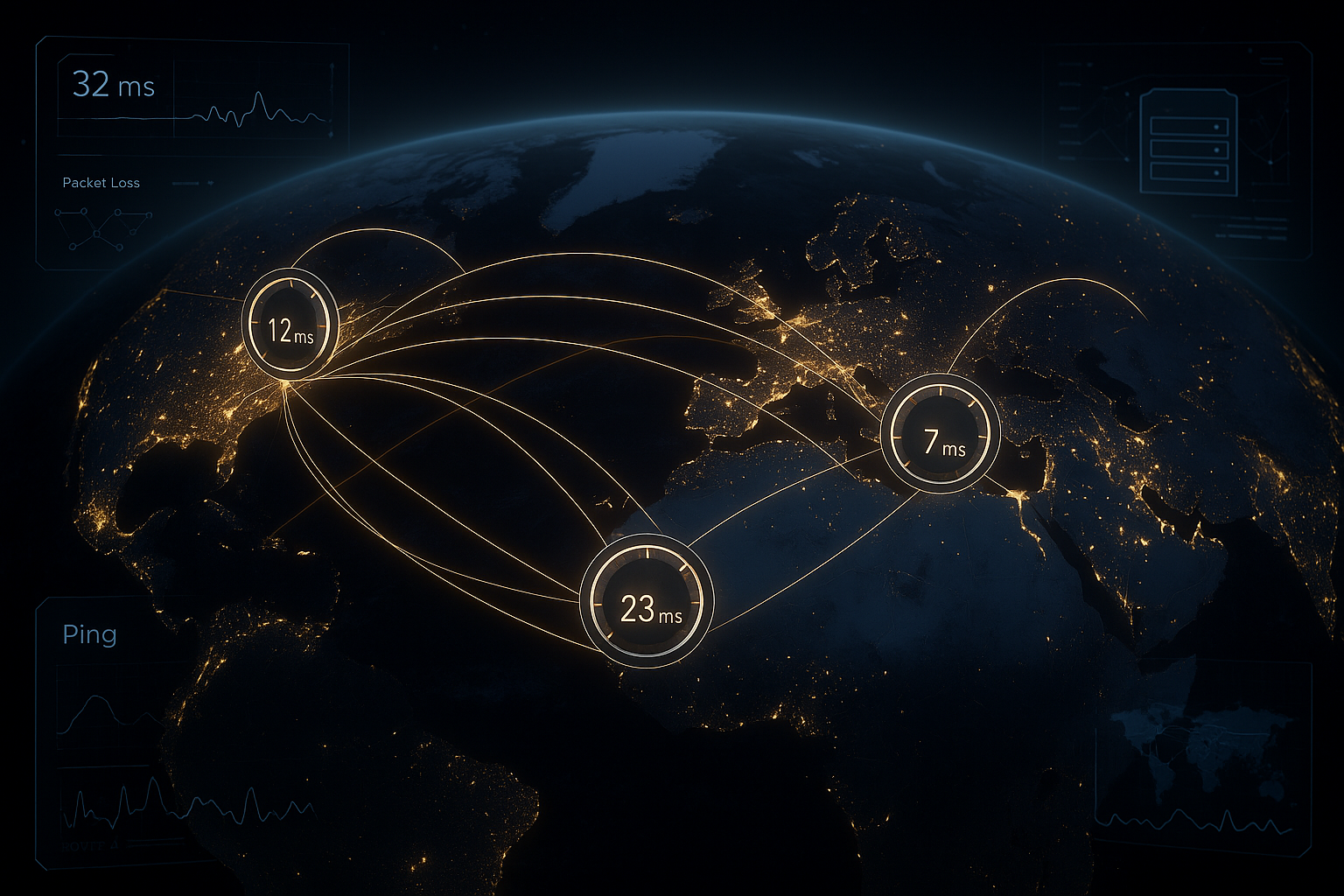
A distância física continua a ser a maior alavanca, uma vez que a velocidade da luz na fibra ótica actua como um Fronteira. Por isso, reduzo os desvios no encaminhamento, certifico-me de que há poucos saltos e favoreço as redes com boas relações de peering. Boas ligações a grandes nós da Internet poupam milissegundos porque os dados requerem menos paragens intermédias. A largura de banda também ajuda, mas não substitui as distâncias curtas e uma topologia sensata. Se quiser minimizar a distância, a qualidade da rota e Peering O novo sistema consegue um tempo de resposta significativamente melhor para os utilizadores de vários continentes.

Localizações globais de servidores e estratégia de localização
Planeio as localizações de acordo com a distribuição dos utilizadores, os requisitos legais e os tempos de tráfego previstos, de modo a que os conteúdos estejam sempre curto forma. Para os grupos-alvo internacionais, utilizo vários centros de dados na Europa, América e Ásia, que estão ligados através de backbones rápidos. A combinação com o DNS anycast e a verificação de integridade limpa distribui os pedidos pela melhor instância. Em cenários com cargas variáveis, utilizo Balanceamento de carga geográfica, para ficar perto dos utilizadores. Isto permite que as sessões sejam executadas de forma consistente, mantendo a latência baixa e Falhas elegantemente almofadado.
Redes de distribuição de conteúdos: obrigatórias para um desempenho global
Uma CDN armazena activos estáticos em dezenas de localizações de extremidade, encurta drasticamente os caminhos e reduz visivelmente a carga no servidor de origem para Carga de pico. Activei o desvio inteligente da cache para partilhas personalizadas e regras em cascata para imagens, scripts e APIs. Também utilizo a substituição de push HTTP/2 através de dicas de pré-carregamento e testo TTLs de cache por tipo de ficheiro. Para requisitos elevados, combino POPs de diferentes fornecedores através de Estratégias multi-CDN, para capitalizar os pontos fortes regionais. Isto dá-me uma prestação consistente e assegura Redundância contra falhas de redes individuais.
Configuração do servidor, protocolos e compressão
Ativo o HTTP/2 e o TLS 1.3, utilizo o agrafamento OCSP e optimizo a atribuição de prioridades para que os activos críticos sejam carregados primeiro e Apertos de mão pode ser concluída rapidamente. O QUIC/HTTP/3 ajuda em redes com perda de pacotes, por exemplo, com utilizadores móveis, uma vez que as ligações são restabelecidas mais rapidamente. Os parâmetros keep alive e a reutilização de ligações também reduzem as despesas gerais. Ao nível do servidor, removo os módulos desnecessários, afino os pools de trabalhadores e de threads, utilizo epoll/kqueue e selecciono cifras TLS modernas. Para compressão de dados, inicio o Brotli para ficheiros estáticos e o Gzip para respostas dinâmicas, de modo a que os ficheiros transmitidos Bytes sem prejudicar a qualidade da imagem.
Estratégias de armazenamento em cache: cache do servidor e do browser
No lado do servidor, acelero o PHP com o OPcache, mantenho os fragmentos HTML na RAM e uso o Varnish como um acelerador HTTP rápido para Acertos. Para as partes dinâmicas, utilizo as inclusões do lado da borda ou uso AJAX para obter o que precisa de ser personalizado. Na cache do browser, trabalho com Cache-Control, ETags, Last-Modified e limpo TTLs para cada classe de ativo. Os cabeçalhos imutáveis e os nomes de ficheiros com um hash de conteúdo evitam bloqueios causados por versões antigas. Isto significa que a primeira visualização permanece rápida e que as chamadas subsequentes são conseguidas Subsegundos-vezes até para muitos activos.

Otimização do DNS e afinação da resolução de nomes
A primeira consulta determina muitas vezes a velocidade, razão pela qual confio em servidores autoritativos rápidos com anycast e Pesquisas. A redução dos domínios externos diminui o número de consultas DNS paralelas. Verifico as cadeias de resolvedores, ativo o DNSSEC sem sobrecargas desnecessárias e coloco as respostas em cache com um TTL sensato. Para aplicações com muitos subdomínios, utilizo estratégias de wildcard para limitar o número de novos nomes de anfitrião. Os tempos de DNS curtos contribuem diretamente para a TTFB e melhoram o desempenho percetível. Velocidade antes do primeiro byte.
Otimização da rede em ambientes de nuvem
Na nuvem, reduzo a sobrecarga do kernel com o Accelerated Networking, que fornece aos pacotes um caminho de dados direto para a NIC. utilizar. O Receive Side Scaling distribui a carga da rede de forma sensata entre os núcleos, o que ajuda notavelmente com altas taxas de PPS. Os grupos de posicionamento de proximidade aproximam as VMs para reduzir a latência entre o aplicativo, o cache e o banco de dados. Também escolho regiões com boas conexões de interconexão e verifico regularmente as latências entre regiões. Isso mantém o caminho de dados curto, enquanto eu Espigões com escalonamento automático.

Computação periférica e estratégias de peering
Desloco a lógica para os limites, como a transformação de imagens, as decisões A/B ou os pré-testes de autenticação, para que as respostas possam ser dadas sem longos caminhos de retorno. surgir. Isto traz benefícios tangíveis para aplicações críticas em termos de tempo, como jogos, IoT ou eventos em direto. Também negoceio peerings diretos ou utilizo trocas na Internet para chegar a grandes redes sem desvios. Isto reduz o jitter e a perda de pacotes, o que beneficia os fluxos e as interações. Se quiser ir mais longe, pode encontrar Alojamento Edge um caminho claro para mais curto Caminhos.
Monitorização, métricas e testes de carga
Meço o TTFB, o Índice de Velocidade, o CLS e o FID separadamente por região e dispositivo para refletir a experiência real do utilizador e Tendências para reconhecer. Os testes sintéticos de muitos países complementam a monitorização do utilizador real e revelam erros de encaminhamento. Os rastreios clarificam a inflação do caminho, enquanto as verificações de perda de pacotes iluminam as redes móveis. Os testes de carga pré-lançamento evitam surpresas, verificando caches, bases de dados e filas de espera na rede. Com alertas baseados em SLO, reajo cedo e mantenho o Disponibilidade elevado.
Proximidade, replicação e consistência da base de dados
Aproximo geograficamente o acesso de leitura dos utilizadores, sem a Caminhos da escrita As réplicas de leitura em regiões reduzem o RTT para consultas, enquanto um primário de gravação claro mantém a consistência. Para aplicações distribuídas globalmente, confio em Read-Local/Write-Global, verifico Multi-Primary apenas para casos de utilização com Resolução de conflitos (por exemplo, através de CRDTs) e definir orçamentos de latência para caminhos de confirmação. O pooling de conexões evita a sobrecarga de TCP/TLS por consulta; os hotsets são armazenados no cache na memória. Reduzo os padrões de conversação, agrupo as consultas e uso chaves de idempotência para repetições. Isso mantém os dados consistentes, enquanto os caminhos de leitura curto e manter a possibilidade de planeamento.
Conceção da API e optimizações de front-end
Minimizo as viagens de ida e volta utilizando pontos finais consolidar, simplificam as cargas úteis e utilizam ativamente a multiplexagem HTTP/2. A coalescência de conexões reduz os handshakes TCP/TLS adicionais se os certificados contiverem SANs adequados. Rejeito a fragmentação de domínios porque interfere com a definição de prioridades e a reutilização; em vez disso, trabalho com pré-carregamento e prioridades para recursos críticos. Comprimo JSON com Brotli, removo campos sem relevância para a IU e utilizo actualizações delta em vez de respostas completas. O frontend recebe CSS crítico em linha, fontes com Preconnect/Preload e um preguiçoso Hidratação, para que o Above-the-Fold se levante rapidamente.
Redes móveis, QUIC e controlo de congestionamento
A rádio móvel traz maior RTT e Perda de pacotes. Por conseguinte, confio no QUIC/HTTP/3 com recuperação rápida, ativo o TLS 1.3 Session Resumption e testo apenas o 0-RTT, onde os riscos de repetição são excluídos. No lado do servidor, testo o BBR contra o CUBIC e selecciono o melhor controlo de congestionamento em função do perfil de perda de pacotes. As dicas de prioridade, o JS diferido e o lazyloading de imagens ajudam a acelerar a primeira interação. Nos casos em que o TCP Fast Open está bloqueado, baseio-me na reutilização da ligação e em longos períodos de inatividade para evitar handshakes e Jitter amortecimento.

Modelos de invalidação e atualização da cache
Os ganhos em latência aumentam e diminuem com Acertos. Controlo a frescura com stale-while-revalidate e stale-if-error, utilizo chaves substitutas para purgar tematicamente e utilizo soft-purge para manter as caches „quentes“. As caches negativas reduzem os erros repetidos para 404/410, enquanto eu encapsulo áreas personalizadas com hole-punching (ESI). Para APIs, utilizo chaves de cache diferenciadas (por exemplo, idioma, região), cabeçalhos Vary com moderação e ETags/If-None-Match para respostas 304 ligeiras. Desta forma, evito tempestades de cache e mantenho os tempos de resposta mesmo com lançamentos. estável.
Segurança nos limites sem perda de velocidade
Subcontrato o WAF, a proteção DDoS e os limites de taxa à Borda, para travar o tráfego nocivo numa fase inicial e aliviar a carga sobre as origens. Dou prioridade às regras de modo a que as verificações favoráveis (IP/ASN, geo, assinaturas simples) tenham efeito desde o início. As configurações TLS recebem HSTS, cifras modernas e grampeamento OCSP consistente; planeio a rotação de certificados sem interrupções. O gerenciamento de bots é executado com baixa latência usando impressão digital e desafios adaptativos. Resultado: Mais segurança com o mínimo de sobrecarga e um mais calmo Origem mesmo com picos.
Observabilidade, rastreio e orçamentos de erros
Correlaciono os caminhos do Edge, CDN e Origin com cabeçalhos de rastreamento (por exemplo. Traceparent) e defino identificações de correlação normalizadas em toda a cadeia. Combino os dados RUM da navegação e da cronometragem de recursos com os dados sintéticos, meço P50/P95/P99 separadamente por mercado e dispositivo e defino SLOs incluindo orçamentos de erro para latência. Mantenho a amostragem adaptável para captar os pontos críticos com maior resolução. As verificações de blackhole e jitter são executadas continuamente para que os desvios de encaminhamento sejam reconhecidos numa fase inicial. Isto permite-me reconhecer as causas em vez dos sintomas e controlar direcionado para.
Custos, orçamentos e compromissos de arquitetura
O desempenho tem de compensar. Optimizo a taxa de acerto da cache porque cada Menina custos de saída e RTT, e planear a faturação de 95º percentil no orçamento. A multirregião reduz a latência, mas aumenta os custos de armazenamento e replicação de dados; é por isso que estabeleço regras claras: O que é que pertence à periferia (estático, transformável), o que é que permanece centralizado (escritas críticas)? Mantenho as implementações de baixo risco com configuração como código, lançamentos canários e reversões automatizadas. O pré-aquecimento garante que as novas versões sejam lançadas sem caches frios início.
Conformidade, residência de dados e zonas
A regulamentação influencia os caminhos: Mantenho os dados pessoais no respetivo Região, Se possível, processo-os de forma pseudónima na periferia e integro as gravações sensíveis de forma centralizada. Encaminho o tráfego de zonas restritivas através de POPs locais, se exigido por lei, e separo a telemetria técnica dos dados do utilizador. Isto mantém a latência, a proteção de dados e a disponibilidade em Equilíbrio - também para auditorias.
Otimização do encaminhamento com anycast e BGP
Eu controlo as rotas anycast com comunidades e o preenchedor de caminho AS direcionado para corrigir alocações incorretas e Pontos de acesso para aliviar a carga. RPKI protege contra hijacks, enquanto traceroutes regulares tornam a inflação do caminho visível. Para casos especiais, eu uso o region pinning quando a estabilidade da sessão é mais importante do que o caminho mais curto absoluto. O objetivo é sempre um caminho resiliente e reproduzível com pouco Jitter.
Comparação entre fornecedores: gestão da latência no controlo
Para os projectos internacionais, presto atenção à presença global, ao hardware de alta qualidade e às opções de CDN integradas para que o Prazo de entrega continua a ser curto. Também verifico os perfis de peering, as políticas de encaminhamento e as funções de monitorização. Os fornecedores com armazenamento SSD, CPUs potentes e bom suporte para HTTP/2/3 ganham pontos. Um critério adicional é a integração simples de balanceadores de carga e verificações de saúde. A seguinte visão geral mostra uma comparação prática com vista a Latência e equipamento.
| Local | Fornecedor | Localizações | Integração CDN | Hardware | Otimização da latência |
|---|---|---|---|---|---|
| 1 | webhoster.de | Europa, EUA, Ásia | Sim | Topo de gama | Excelente |
| 2 | HostEurope | Europa | Opcional | Bom | Bom |
| 3 | Mittwald | Europa | Opcional | Bom | Médio |
| 4 | IONOS | Europa, EUA | Opcional | Bom | Médio |
| 5 | Strato | Europa | Opcional | Bom | Médio |
Para além da tecnologia, também avalio a flexibilidade dos contratos, o suporte IPv6, o acesso à API e as vias de migração, uma vez que permitem alterações posteriores. Simplificar. Se pretende crescer globalmente, precisa de ciclos de teste curtos, ajuste de capacidade em qualquer altura e encaminhamento transparente. Os fornecedores com uma configuração multi-região opcional e páginas de estado claras ganham pontos no dia a dia. Isto significa menos surpresas em caso de picos de tráfego ou interrupções regionais. Aqueles que têm em conta estes factores reduzem os riscos e mantêm a Desempenho previsível.
Resumo e próximas etapas
Para projectos rápidos com utilizadores globais, combino a proximidade com o utilizador, protocolos modernos, caching forte e consistente Monitorização. Numa primeira fase, configuro o DNS anycast, ativo o HTTP/2 e o TLS 1.3, defino os TTL da cache e meço o TTFB nos mercados-alvo mais importantes. Segue-se a afinação da CDN, Brotli para activos estáticos e testes QUIC em rotas móveis. Com traceroutes e testes de carga regulares, mantenho os caminhos curtos e reconheço precocemente os valores anómalos. O resultado é uma configuração resiliente que reduz a latência, mantém os custos sob controlo e oferece aos utilizadores de todo o mundo o melhor serviço possível. Satisfeito ...faz.


