Sari la conținut
Sari la conținut 
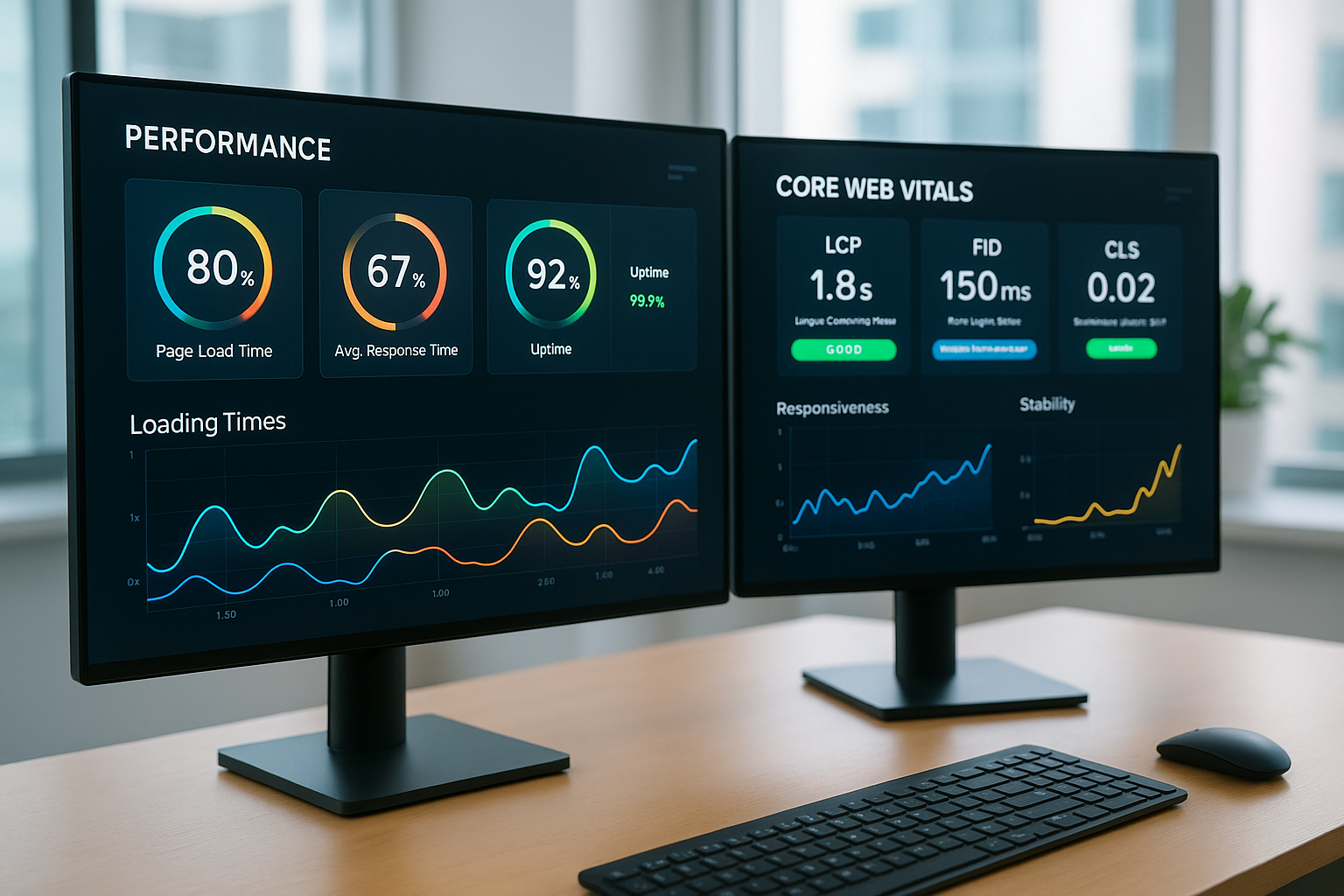
Bazele de date fără server mută administrarea și scalarea la backend-ul furnizorului și îmi oferă performanțe dinamice pe care le pot apela după cum este necesar în găzduirea web. Astfel, combin automat Scalare, costuri bazate pe utilizare și mai puține cheltuieli generale operaționale pentru site-uri web moderne, API-uri și platforme globale.
Puncte centrale
Mă concentrez pe esență, astfel încât să puteți acționa rapid. Serverless înseamnă scalare în timp real fără întreținere constantă a serverului. Plata în funcție de utilizare face ca fluctuațiile de sarcină să fie previzibile. Decuplarea calculului și a stocării crește eficiența și disponibilitatea. Reduceți strategiile de margine Latență pentru utilizatorii din întreaga lume.
- Scalare la cerere, fără instanțe fixe
- Plata pentru utilizare în loc de costuri opace
- Mai puțin Întreținere, mai multă concentrare pe logică
- Decuplarea de calcul și stocare
- Marginea-arhitectură închisă pentru distanțe scurte

Ce înseamnă serverless în găzduirea web?
Serverless înseamnă: închiriez putere de calcul și baze de date care pornesc, se măresc și se opresc automat atunci când solicitările sosesc sau sunt anulate. Platforma se ocupă de patch-uri, backup-uri și securitate, astfel încât eu să mă pot concentra pe modele de date și interogări. Declanșatoarele și evenimentele controlează execuția și ciclul de viață al volumelor mele de lucru în În timp real. Acest lucru decuplează cheltuielile de tiparele de trafic și de vârfurile sezoniere. Ofer o introducere practică a beneficiilor și a domeniilor de aplicare la Avantaje și domenii de aplicare.
Arhitectura și funcționalitatea bazelor de date fără server
Aceste sisteme separă în mod consecvent calculul și stocarea, ceea ce favorizează interogările paralele, în funcție de cerere. Conexiunile sunt create rapid prin pooling sau interfețe HTTP, ceea ce reduce utilizarea și costurile. Datele persistente sunt stocate geo-redundant, ceea ce înseamnă că eșecurile au un impact mai mic și Disponibilitate crește. Infrastructura reală rămâne abstractizată, eu lucrez prin API-uri, drivere și dialecte SQL/NoSQL. Servicii precum Aurora Serverless, PlanetScale sau CockroachDB oferă aceste caracteristici în configurații productive.

Efecte asupra găzduirii web
Înainte trebuia să planific resursele în avans și să le cresc manual, dar acum sistemul se ocupă automat de capacitate. Acest lucru economisește bugetul în fazele liniștite și acoperă vârfurile fără a fi nevoie de reorganizare. Cu plata în funcție de utilizare, plătesc pentru accesul, stocarea și traficul real, nu pentru timpul de inactivitate. Întreținerea, patch-urile și backup-urile rămân la furnizor, permițând echipelor să livreze mai rapid. Acesta este modul în care eu mut Logica aplicației la centru, în loc să întrețină servere.
Securitate, conformitate și protecția datelor
Securitatea nu este retroadaptată în serverless, ci face parte din design. Mă bazez pe gestionarea identității și a accesului cu drepturi minime (cel mai mic privilegiu) și roluri separate pentru sarcinile de citire, scriere și administrare. În mod implicit, criptez datele în repaus, gestionez cheile la nivel central și le rotesc periodic. Pentru datele în mișcare, folosesc TLS, verific automat certificatele și blochez suitele de cifrare nesigure.
Capacitatea multi-client necesită o izolare curată: din punct de vedere logic, prin ID-uri ale chiriașilor și securitate la nivel de rând sau fizic, prin scheme/instanțe separate. Jurnalele de audit, jurnalele de tip write-ahead neschimbabile și istoricul de migrare trasabil facilitează furnizarea de dovezi. Pentru GDPR, acord atenție rezidenței datelor, procesării comenzilor și conceptelor de ștergere, inclusiv backup-urilor. Pseudonimizez sau anonimizez câmpurile sensibile și ader la perioadele de păstrare. Acest lucru asigură conformitatea și Performanță în echilibru.
SQL vs. NoSQL în Serverless
Dacă este relațional sau orientat pe documente: Eu decid în funcție de structura datelor, cerințele de coerență și profilul interogării. SQL este potrivit pentru volumele de lucru tranzacționale și îmbinările curate, NoSQL pentru schemele flexibile și ratele masive de citire/scriere. Ambele variante sunt serverless cu scalare automată și motoare de stocare distribuite. Modelele de consecvență variază de la puternic la eventual, în funcție de obiectivele de latență și debit. Puteți găsi o comparație compactă în Comparație SQL vs NoSQL, ceea ce simplifică alegerea și Riscuri reduce.

Scenarii tipice de aplicare
Comerțul electronic și emiterea de bilete beneficiază de faptul că vârfurile de sarcină apar fără un plan și funcționează stabil. Produsele SaaS beneficiază de capacitate multi-client și de acoperire globală fără întreținere constantă a clusterului. Platformele de conținut cu sarcini intensive de citire și scriere pot face față vârfurilor cu timpi de răspuns scurți. Fluxurile IoT și procesarea evenimentelor scriu multe evenimente în paralel și rămân receptive datorită decuplării. Back-end-urile mobile și microserviciile se eliberează mai rapid, deoarece provizionarea și Scalare să nu încetinească.
Modelarea datelor, evoluția și migrarea schemelor
Proiectez schemele astfel încât modificările să fie compatibile înainte și înapoi. Adaug coloane noi în mod opțional, dezactivez câmpurile vechi utilizând un indicator de caracteristică și le curăț numai după o perioadă de observație. Efectuez migrări grele în mod incremental (backfill în loturi), astfel încât nucleul bazei de date să nu se prăbușească sub sarcină. Pentru tabelele mari, planific partiționarea în funcție de timp sau de chiriaș pentru a menține reindexările și vidarea mai rapide.
Evit conflictele prin încorporarea idempotenței: Upserts în loc de inserții duplicate, chei de afaceri unice și procesarea organizată a evenimentelor. Pentru NoSQL, planific versionarea per document, astfel încât clienții să recunoască modificările de schemă. Tratez conductele de migrare ca pe un cod, le versionez și le testez cu date legate de producție (anonimizate). Acest lucru minimizează riscul modificărilor și permite planificarea versiunilor.
Gestionarea conexiunilor, cache și performanță
Sarcinile de lucru fără server generează multe conexiuni de scurtă durată. Prin urmare, folosesc API-uri de date bazate pe HTTP sau pooling de conexiuni pentru a evita depășirea limitelor. Eliberez accesele de citire prin replici de citire, vizualizări materializate și cache-uri cu un TTL scurt. Decuplez încărcările de scriere prin intermediul cozilor de așteptare sau al jurnalelor: Partea frontală confirmă rapid, iar persistența procesează loturi în fundal. Mențin planurile de interogare stabile prin utilizarea parametrizării și evitarea accesărilor N+1.
Pentru latența la margine, combin cache-urile regionale, magazinele KV și o sursă centrală de adevăr. Invalidarea este determinată de evenimente (write-through, write-behind sau bazată pe evenimente) pentru a păstra datele proaspete. Monitorizez rata de succes, percentilul 95/99 și costul per cerere pentru a găsi echilibrul între viteză și Controlul costurilor pentru a găsi.
Dezvoltare locală, teste și CI/CD
Dezvolt în mod reproductibil: scripturile de migrare se execută automat, datele de pornire reprezintă cazuri realiste și fiecare mediu al sucursalei primește o bază de date izolată, de scurtă durată. Testele de contract și de integrare verifică interogările, autorizațiile și comportamentul de blocare. Înainte de fuzionare, derulez teste de fum pe o regiune de staționare, măsor timpii de interogare și validez SLO-urile. Fluxurile de lucru CI/CD gestionează migrarea, lansarea canary și revenirea opțională cu recuperare punct în timp.
Întreținerea, persistența și caracteristicile speciale ale datelor
Mă bazez pe conexiuni de scurtă durată și pe servicii fără statel care procesează eficient evenimentele și persistă datele. Decuplez căile de scriere prin intermediul cozilor de așteptare sau al jurnalelor, pentru a tampona în mod curat încărcăturile de tip burst. Accelerez căile de citire prin intermediul cache-urilor, al vizualizărilor materializate sau al KV de margine, aproape de utilizator. Acest lucru reduce latența, iar DB-ul de bază rămâne relaxat chiar și în timpul vârfurilor de trafic. Planific indicii, partițiile și datele fierbinți/frigide astfel încât Întrebări rămâi rapid.

Facturarea și optimizarea costurilor
Costurile sunt compuse din operațiuni, stocare și transfer de date și sunt exprimate în euro, în funcție de utilizare. Reduc cheltuielile prin caching, batching, timpi de execuție scurți și indici eficienți. Mut datele reci în clase de stocare mai ieftine și păstrez hotset-urile mici. Zilnic, monitorizez parametrii și înăspresc limitele pentru a evita valorile aberante costisitoare. Acest lucru menține combinația de viteză și Controlul costurilor coerente.
Controlul practic al costurilor
Definesc garduri de protecție pentru buget: limite stricte pentru conexiunile simultane, timpi maximi de interogare și cote pe client. Rapoartele pe bază orară îmi arată care sunt rutele care generează costuri. Transfer exporturile și analizele mari în afara orelor de vârf. Materializez agregările în loc să le calculez în mod repetat live. Reduc mișcările de date dincolo de granițele regionale prin servirea încărcărilor de citire la nivel regional și prin centralizarea doar a evenimentelor care suferă mutații.
Deseori găsesc costuri neașteptate cu API-urile chatty, scanările nefiltrate și TTL-urile prea generoase. Prin urmare, păstrez câmpurile selective, folosesc paginarea și planific interogările pentru prefixele indexurilor. Cu NoSQL, acord atenție cheilor de partiție care evită punctele fierbinți. Astfel, factura rămâne previzibilă, chiar dacă cererea explodează la scurt timp.
Provocări și riscuri
Accesările rare pot declanșa porniri la rece, așa că ascund acest lucru prin strategii de încălzire sau cache-uri. Observabilitatea necesită jurnale, metrici și urme adecvate, pe care le integrez într-un stadiu incipient. Minimizez blocajul furnizorului cu interfețe standardizate și scheme portabile. Aleg servicii adecvate pentru sarcini de lungă durată, în loc să le forțez în funcții scurte. Acesta este modul în care păstrez Performanță ridicate și riscuri gestionabile.

Observabilitate și procese operaționale
Măsor înainte de a optimiza: SLI precum latența, rata de eroare, debitul și saturația îmi cartografiază SLO-urile. Urmările arată punctele fierbinți în interogări și în cache, iar eșantionarea jurnalelor previne inundațiile de date. Am configurat alerte bazate pe simptome (de exemplu, latența P99, rata de anulare, lungimea cozii), nu doar pe CPU. Runbook-urile descriu pași clari pentru strangulare, failover și redimensionare, inclusiv căile de comunicare pentru apel.
GameDays regulate simulează eșecurile: Regiune offline, blocaj de stocare, partiție fierbinte. Documentez constatările, ajustez limitele și timpii de așteptare și exersez reveniri. Astfel, operațiunile rămân robuste, chiar și atunci când realitatea se desfășoară altfel decât pe tablă.
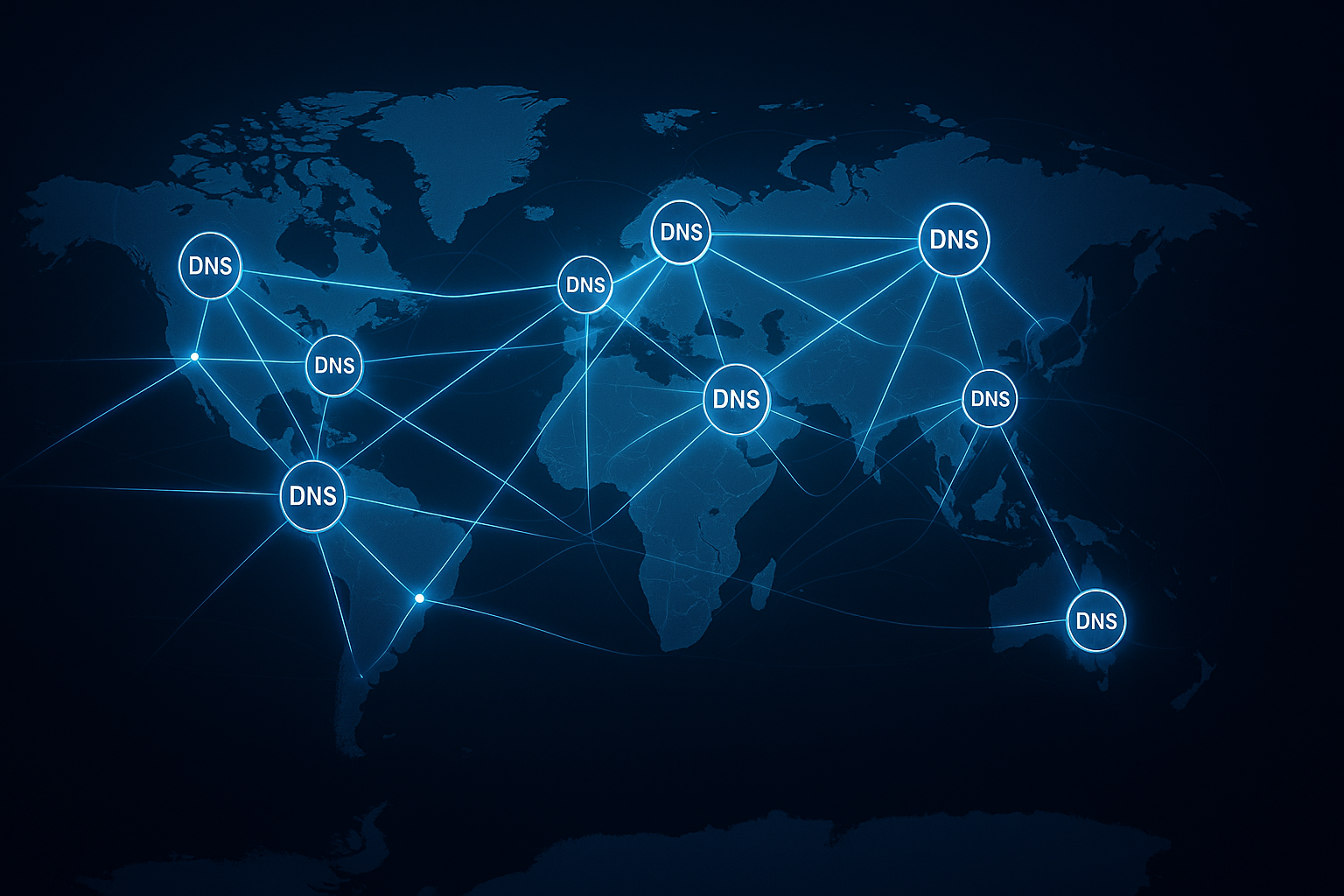
Multiregiune, replicare și recuperare în caz de dezastru
Aplicațiile globale beneficiază de configurații multiregiune. În funcție de cerința de consecvență, aleg între activ/activ (eventual, apropiere rapidă de utilizator) și activ/pasiv (consecvență ridicată, failover definit). Formulez RPO/RTO în mod explicit și testez recuperările cu recuperare punct în timp. Rezolv conflictele în mod determinist (ultima scriere câștigă, reguli de fuzionare) sau utilizând rezolvatoare specializate. Backup-urile regulate, testele de restaurare și playbook-urile asigură capacitatea de a acționa în caz de urgență.
Cele mai bune practici pentru găzduirea web cu serverless
Proiectez din timp arhitectura datelor: separarea datelor fierbinți de cele grele, partiții curate și indici direcționați. Accept consecvența eventuală atunci când contează randamentul și blocajele dure încetinesc lucrurile. Strategiile de margine reduc latența; descriu modele adecvate la Serverless la margine. Aplicațiile globale multiregiune și replicare au fost susținute cu căi scurte. Cu SLO-uri clare și alerte bugetare, mențin Calitatea serviciilor în viața de zi cu zi.
Prezentare generală a pieței și alegerea furnizorului
Verific mai întâi modelele de volum de lucru, cerințele de protecție a datelor și regiunile dorite. Apoi compar ofertele SQL/NoSQL, modelele de tarifare și limitele de conectare. Căile de migrare, ecosistemul de drivere și opțiunile de observabilitate sunt importante. Pentru scenariile hibride, acord atenție conectorilor la sistemele și instrumentele BI existente. Acesta este modul în care găsesc Platformă, care se potrivește tehnologiei, echipei și bugetului.
| Criterii | Baze de date clasice | Baze de date fără server |
|---|---|---|
| Dispoziție | Instanțe manuale, dimensiuni fixe | Automat, la cerere |
| Scalare | Manual, limitat | Dinamic, automat |
| Facturare | Rata fixă, termen minim | Plata pentru utilizare |
| Întreținere | Complex, autonom | Complet gestionat |
| Disponibilitate | Opțional, parțial separat | Integrat, geo-redundant |
| Infrastructură | Vizibil, administratori necesari | Abstract, invizibil |
| Furnizor | Integrare fără server | Caracteristici speciale |
|---|---|---|
| webhoster.de | Da | Înaltă Putere, sprijin puternic |
| AWS | Da | Selecție largă de servicii |
| Google Cloud | Da | Caracteristici susținute de AI |
| Microsoft Azure | Da | Opțiuni hibride bune |

Greșeli frecvente și anti-patternuri
- Așteptați-vă la o scalare nelimitată: orice sistem are limite. Eu planific cote, presiuni și soluții de rezervă.
- Consecvență puternică peste tot: fac diferența în funcție de cale; acolo unde este posibil, accept consecvența finală.
- Un singur DB pentru toate: Separ încărcătura analitică de cea tranzacțională pentru a menține ambele lumi rapide.
- Fără indici de teama costurilor: Indicii bine aleși economisesc mai mult timp și buget decât costă.
- Observabilitate ulterioară: fără măsurători timpurii, nu am semnale atunci când sarcina și costurile cresc.
Arhitectură de referință pentru o aplicație web globală
Combin un CDN pentru active statice, funcții de margine pentru autorizare și agregări ușoare, o bază de date centrală fără server în regiunea primară cu replici de citire aproape de utilizator și un jurnal de evenimente pentru fluxuri de lucru asincrone. Cererile de scriere sunt sincronizate cu regiunea primară, iar cererile de citire sunt servite de la replici sau de la cache-uri de margine. Modificările generează evenimente care invalidează cache-urile, actualizează vizualizările materializate și alimentează fluxurile analitice. Astfel, răspunsurile rămân rapide, consecvența controlată și costurile gestionabile.
Rezumatul meu pe scurt
Bazele de date fără server îmi oferă libertate în ceea ce privește scalarea, costurile și operarea fără a pierde controlul asupra modelelor de date. Am amânat întreținerea recurentă a platformei și investesc timp în caracteristici pe care utilizatorii le observă. Cu o arhitectură curată, cache-uri bune și SLO-uri clare, totul rămâne rapid și accesibil. Acest model este deosebit de potrivit pentru aplicații dinamice și de anvergură globală. Dacă doriți să rămâneți agili astăzi, serverless este alegerea potrivită. durabile Decizie.