Sari la conținut
Sari la conținut 
Un Monitorizarea stivei cu Grafana și Prometheus oferă furnizorilor de servicii de găzduire web și clienților acestora o imagine clară asupra performanței, disponibilității și securității – de la servere individuale până la clustere Kubernetes întregi. Voi descrie cum Găzduire-Utilizați tablourile de bord, alertele și analizele self-service ale echipelor astfel încât să detectați din timp defecțiunile și să respectați în mod fiabil SLA-urile.
Puncte centrale
Voi rezuma pe scurt următoarele puncte, pentru ca tu să ai imediat o imagine de ansamblu asupra celor mai importante aspecte.
- Prometheus ca coloană vertebrală centrală a metricilor
- Grafana pentru tablouri de bord transparente
- Manager de alerte pentru reacții rapide
- Kubernetes-Monitorizare imediat după instalare
- Multi-tenancy și concepte juridice
De ce hostingul are nevoie de un stack de monitorizare
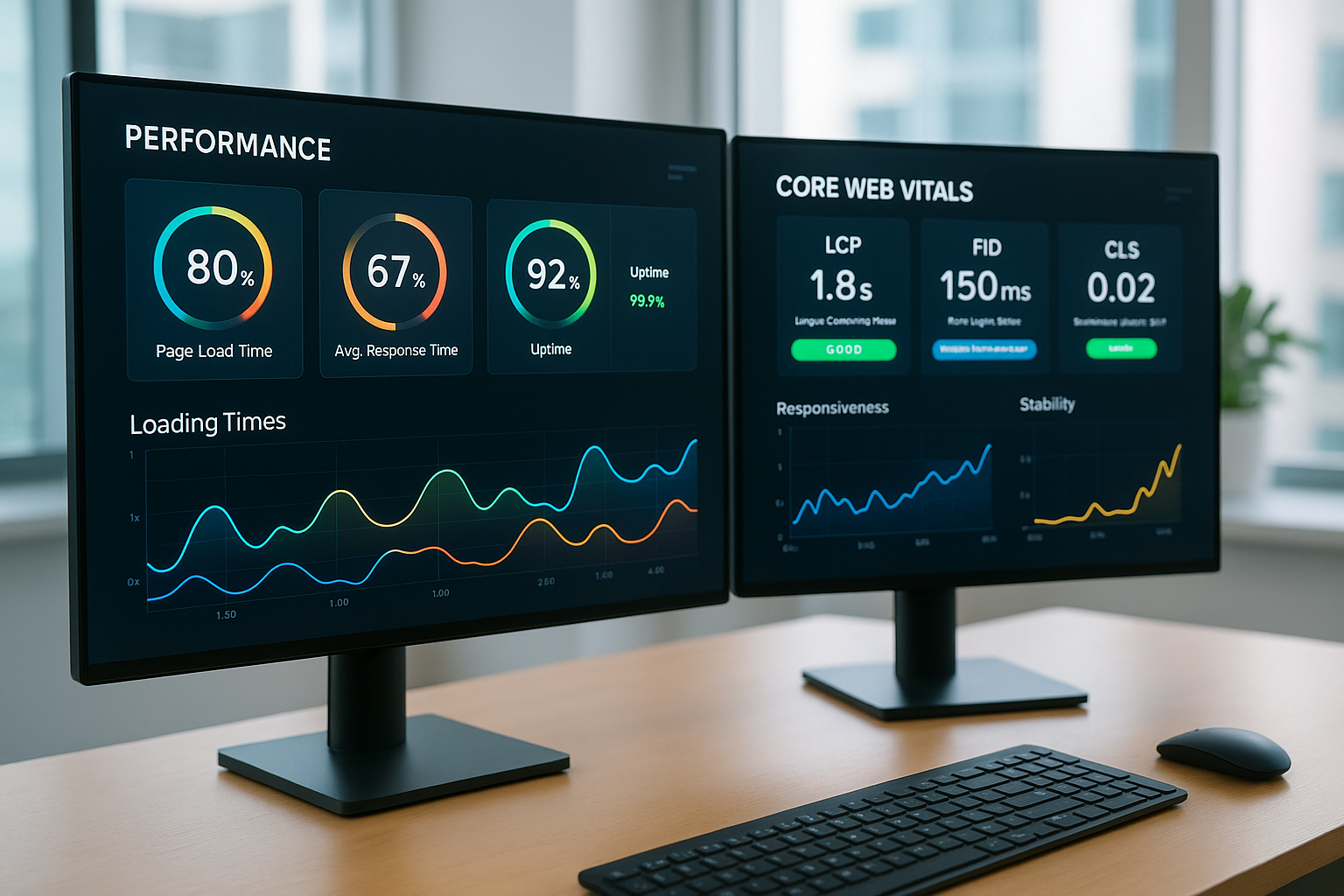
Mediile moderne de găzduire mută sarcinile de lucru în containere, orchestrează serviciile și se scalează dinamic, de aceea am nevoie de un Prezentare generală, care rămâne fiabil în orice moment. Verificările clasice nu sunt suficiente pentru acest lucru, deoarece ele nu reflectă aproape deloc vârfurile, sezonalitatea și dependențele, ceea ce îngreunează analiza cauzelor și prelungește timpii de reacție. Un stack bine structurat din Prometheus și Grafana îmi arată în timp real cum evoluează CPU, RAM, I/O și latențele și semnalează anomaliile înainte ca utilizatorii să observe ceva. Conectez toate exporturile relevante, atribui etichete semnificative și mențin cardinalitatea sub control, astfel încât interogările să rămână rapide și tablourile de bord să reacționeze imediat. Astfel, cresc Transparență pentru echipele de asistență și le ofer clienților mei o vizualizare sigură în regim self-service a propriilor servicii.
Prometheus Hosting – Indicatori sub control
Prometheus colectează continuu valori măsurate de la servere, containere și aplicații, de aceea mizez în mod consecvent pe Etichete și reguli de înregistrare pentru interogări rapide. Încep cu metrici de bază, cum ar fi CPU, RAM, disc, rețea, și extind treptat cu valori de aplicație, cum ar fi cereri, rate de eroare sau lungimi de coadă. Formulez alertele cu PromQL astfel încât să se concentreze pe cauze, cum ar fi creșterea erorilor cu creșterea simultană a latenței, și le trimit prin Alertmanager către canalele potrivite. Pentru medii dinamice, folosesc Service Discovery, astfel încât nodurile sau podurile noi să fie integrate automat și să nu se piardă nicio metrică. Celor care doresc să aprofundeze acest subiect, le recomand ca punct de plecare Monitorizarea utilizării serverului, pentru a înregistra și evalua în mod consecvent indicatorii cei mai importanți; astfel, Performanță atingibil.

Grafana Hosting – Tablouri de bord pentru operatori și clienți
Grafana face datele vizibile, de aceea construiesc tablouri de bord tematice pentru infrastructură, aplicații și indicatori de afaceri, astfel încât toată lumea să poată Părți implicate vede exact ceea ce are nevoie. Clienții primesc spații de lucru pentru clienți cu roluri și foldere, astfel încât separarea datelor este menținută și autoservirea este confortabilă. Folosesc variabile și șabloane pentru ca echipele să poată filtra și compara interactiv gazde, spații de nume sau implementări individuale. Comentariile din panouri leagă modificările sau incidentele direct de metrici, ceea ce accelerează enorm analiza cauzelor. Pentru analize ad-hoc rapide, completez vizualizările Explore, astfel încât să pot crea interogări fără ocolișuri, să testez ipoteze și să Cauza limitează rapid.
Portofoliul exportatorilor și standardele de măsurare
Pentru ca stiva să aibă o acoperire largă, definesc un set de bază de exportatori: node_exporter pentru gazde, cAdvisor și kube-state-metrics în Kubernetes, Blackbox Exporter pentru HTTP(S), TCP, ICMP și DNS, plus exportatori specializați pentru baze de date și cache-uri (de exemplu, PostgreSQL, MySQL/MariaDB, Redis), precum și servere web/ingress. Am grijă să folosesc nume și unități de măsură consistente și utilizez histograme pentru latențe cu bucket-uri alese în mod judicios, astfel încât percentilele să fie fiabile. Standardizez intervalele de scrape, timeout-urile și retry-urile pentru fiecare tip de componentă, pentru a evita vârfurile de încărcare. Etichetele precum tenant, cluster, namespace, service și instance sunt obligatorii, iar etichetele opționale sunt documentate pentru a evita creșterea necontrolată a cardinalității. Astfel, interogările rămân stabile, iar tablourile de bord comparabile.
Monitorizarea sintetică și perspectiva utilizatorului
Pe lângă metricile interne, integrez verificări sintetice care reflectă perspectiva utilizatorilor. Cu ajutorul Blackbox Exporter, verific disponibilitatea, validitatea TLS, redirecționările sau timpii de răspuns DNS – ideal din mai multe regiuni, pentru a măsura și căile de rețea și CDN-urile. Pentru aplicațiile web, utilizez verificări simple ale tranzacțiilor (Canaries) și completez metricile de pe partea serverului, cum ar fi Time-to-First-Byte la intrare. SLO-urile pentru disponibilitate și latență se bazează pe aceste perspective end-to-end și le corelez cu semnalele backend. Astfel, pot identifica dacă o problemă provine din rețea, din aplicație sau din infrastructură și pot dovedi SLA-urile în mod credibil.
Mediile Kubernetes și container
În clustere, utilizez abordarea operatorului pentru ca Prometheus, Alertmanager și Exporter să funcționeze în mod fiabil și să înregistrare la noi implementări. Tablourile de bord prefabricate pentru noduri, poduri, sarcini de lucru și intrări evidențiază în mod clar blocajele și indică din timp saturația sau defecțiunile. Mă concentrez pe SLO-uri: disponibilitate, latență și rata de eroare, pe care le evaluez pentru fiecare serviciu și spațiu de nume. Cu etichete de spațiu de nume, limite de resurse și tipuri de sarcini, controlez cardinalitatea metricilor și rămân rapid cu interogările. Pe măsură ce clusterele cresc, distribui scrapes, segmentez joburile și folosesc federația, astfel încât Scalare se desfășoară fără probleme.
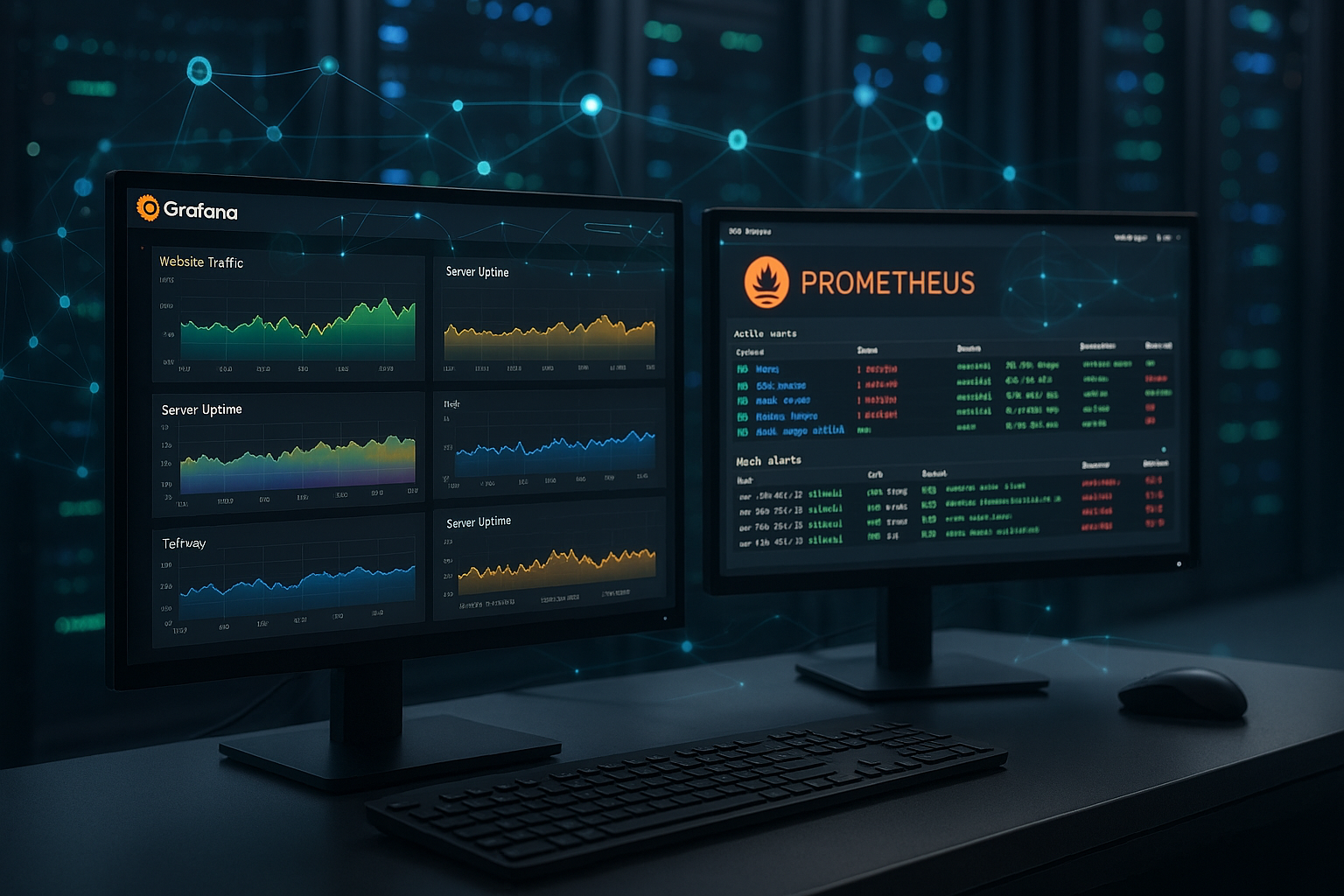
Arhitectura stivei de monitorizare Hosting
Planific stiva în straturi clare: exportatorii și aplicațiile furnizează metrici, Prometheus colectează și stochează, Alertmanager trimite mesaje, iar Grafana vizualizează Rezultate. Pentru datele pe termen lung, mă bazez pe Remote Write către un TSDB pe termen lung, astfel încât retenția și sarcina de interogare să rămână separate în mod clar. Calculez regulile de înregistrare pentru seriile temporale utilizate frecvent, astfel încât tablourile de bord să rămână rapide și fiabile. Documentez joburile, etichetele, convențiile de denumire și strategiile de alertă, astfel încât operațiunile și transferurile să se desfășoare fără probleme. Copiile de rezervă ale directorului TSDB, verificările de stare ale instanțelor și o fereastră de actualizare bine gândită asigură Disponibilitate în plus.
Automatizare și GitOps
Pentru ca configurațiile să rămână reproductibile, le gestionez ca cod: versiunez țintele de scrape, regulile și alertele în Git, automatizez aprovizionarea pentru sursele de date și tablourile de bord Grafana. În Kubernetes folosesc Operator și Helm-Charts, în afara acestuia mizez pe Ansible sau Terraform. Modificările sunt efectuate prin pull request-uri cu revizuire și validări automate (verificări de sintaxă, promtool) înainte de a fi implementate. Parametrii precum punctele finale, chiriașii și retenția sunt incluse în variabile, astfel încât mediile Stage/Prod să rămână consistente. Astfel, stiva rămâne gestionabilă în ciuda numărului mare de clienți și echipe.
Disponibilitate ridicată și reziliență
Pentru o disponibilitate ridicată, utilizez Alertmanager în modul cluster și Prometheus în redundanță activă: două scraper-uri cu configurație identică, dar cu external_labels diferite, asigură că alertele sunt trimise o singură dată și că datele nu sunt numărate de două ori. Împărțesc sarcinile în funcție de client sau de volumul de lucru, astfel încât instanțele individuale să rămână mai mici. Jurnalele Write-Ahead și bufferele Remote-Write protejează împotriva întreruperilor scurte; exercițiile de restaurare validează periodic backup-urile. Pentru o vizualizare globală, agreghez prin federație sau utilizez un nivel separat pe termen lung, fără a supraîncărca instanțele operaționale. Documentez și testez procesele de failover, astfel încât acestea să funcționeze în caz de urgență.

Componente în comparație
Pentru a facilita luarea deciziilor, compar cele mai importante componente și le clasific în funcție de utilitatea lor pentru echipele de hosting care doresc să reflecte în mod clar clienții și obiectivele SLA. Tabelul arată ce sarcini preiau instrumentele și cum interacționează acestea atunci când combin transparența, viteza și fiabilitatea. Iau în considerare vizualizarea, înregistrarea metricilor, alertele și, opțional, analizele jurnalelor și urmăririlor, deoarece aceste niveluri împreună asigură o observabilitate completă. Clasificarea mă ajută să stabilesc priorități și să planific investițiile în mod precis. Astfel, configurarea, funcționarea și dezvoltarea ulterioară rămân ușor de urmărit, iar eu mențin Costuri sub control.
| Componentă | Sarcina | Beneficiile găzduirii | Multi-tenancy |
|---|---|---|---|
| Prometheus | Colectarea și stocarea metricilor | Interogări rapide, etichete flexibile | Separare prin etichete/sarcini |
| Manager de alerte | Reguli și rutare pentru alerte | Reacție rapidă, responsabilități clare | Destinatar per client |
| Grafana | Tablouri de bord și analiză | Transparență pentru echipe și clienți | Dosare, drepturi, echipe |
| Loki (opțional) | Indexarea și căutarea în jurnale | Analiza rapidă a cauzelor | ID-uri chiriaș |
| Viteză/OTel (opțional) | Înregistrarea urmelor | Transparență de la un capăt la altul | Conducte izolate |
Cele mai bune practici pentru multi-tenancy și securitate
Separ clienții prin echipe, foldere și surse de date în Grafana, astfel încât numai persoanele autorizate să aibă acces la informațiile corecte. Date Accesez. În Prometheus respect cu strictețe convențiile de etichetare, astfel încât alocarea clienților, clusterul, spațiul de nume și serviciul să fie ușor de recunoscut. Secretele, acreditările și webhook-urile sunt gestionate centralizat și reînnoite periodic pentru a minimiza riscurile. Regulile de rețea și TLS securizează căile dintre exportatori, ținte de scrape și vizualizare, reducând astfel suprafețele de atac. Auditul în Grafana și configurațiile revizibile ale alertelor îmi oferă o imagine clară. Procese, atunci când verific sau raportez modificări.
Conformitatea și protecția datelor
Înregistrez numai datele de care am nevoie pentru funcționare și raportare și evit detaliile personale în etichete. În cazul în care sunt necesare identificatori, utilizez pseudonimizarea sau hash-uri și documentez căile de ștergere pentru clienți. Stabilesc perioada de păstrare pentru fiecare client, în conformitate cu cerințele contractuale și legale. Funcțiile de export și jurnalele de audit sprijină cererile de informații, iar nivelurile de acces (SSO, roluri, token-uri API) împiedică proliferarea necontrolată. Astfel, combin transparența cu protecția datelor și fac verificările fără stres.

Jurnalele și urmele completează metricile
Metricile îmi arată ce, jurnalele și urmele îmi arată de ce, așa că conectez panouri cu vizualizări de jurnale și urme pentru o Analiză. Recomand jurnale structurate și etichete relevante, astfel încât corelațiile dintre codurile de eroare, vârfurile de latență și implementări să fie vizibile imediat. Conectez tablourile de bord direct la fluxurile de jurnale, astfel încât să pot trece de la un vârf la evenimentele corespunzătoare. Pentru backup-urile indexurilor de jurnale, planific clase de stocare și retenție pentru fiecare client, astfel încât conformitatea și costurile să fie în concordanță. Ca introducere, este utilă prezentarea generală a Agregarea jurnalelor în găzduire, care este conexiuni între metrici, evenimente și audit.
Interogări, cardinalitate și performanță
Controlez valorile etichetelor, evit dimensiunile infinite, cum ar fi ID-urile utilizatorilor, și verific etichetele noi înainte de introducere. În PromQL, mă bazez pe agregări cu grupări clare (sum by, avg by) și evit expresiile regulate costisitoare în interogările frecvente. Calculele frecvente ajung să fie reguli de înregistrare, astfel încât tablourile de bord să nu colecteze date brute de fiecare dată. Pentru latențe, folosesc histograme și deriv p90/p99 în mod consecvent; limitez în mod explicit analizele Top-N (topk) și documentez sarcina lor. Astfel, panourile rămân reactive și interogările planificabile – chiar și cu o cantitate crescândă de date.
Scalare, federație și strategii de stocare
Pe măsură ce infrastructura crește, separ înregistrarea, procesarea și stocarea pe termen lung, astfel încât Putere rămâne stabilă și interogările pot fi planificate. Folosesc federația atunci când doresc să agreghez metrici pe locații sau clustere, fără a păstra fiecare set de date la nivel central. Scrierea la distanță într-un magazin de lungă durată îmi permite păstrarea pe termen lung și analizele istorice, în timp ce instanțele operaționale rămân eficiente. Monitorizez cardinalitatea metricilor și limitez valorile etichetelor foarte variabile, astfel încât memoria și CPU-ul să nu depășească limitele. Pentru ca tablourile de bord să reacționeze rapid, grupez agregările utilizate frecvent ca reguli de înregistrare și documentez Valori limită inteligibil.
Procese operaționale și raportare SLA
Eu combin monitorizarea cu gestionarea incidentelor, calendarul schimbărilor și planurile de gardă, astfel încât reacție funcționează fără probleme în caz de urgență. Tablourile de bord cu obiective SLO afișează gradul de îndeplinire și valorile aberante, ceea ce facilitează comunicarea cu clienții. Pentru rapoartele săptămânale și lunare, export automat indicatorii și adaug comentarii contextuale. Runbook-urile documentează modelele obișnuite de defecțiuni, inclusiv punctele de măsurare, interogările și contramăsurile. Organizez întâlniri de revizuire după incidente majore, verific zgomotul de alarmă și ajustez pragurile astfel încât calitatea semnalului creșteri.
Testabilitate, calitatea alarmelor și exerciții
Testez alertele cu evenimente sintetice și teste unitare pentru reguli înainte ca acestea să fie activate. Verific rutele în Alertmanager cu dry-run-uri, silențierile sunt limitate în timp și comentate. Măsor MTTD/MTTR, urmăresc falsele pozitive și elimin zgomotul prin reguli orientate către cauze (de exemplu, defecțiuni grupate în loc de defecțiuni per gazdă). Exercițiile de haos și failover validează faptul că tablourile de bord afișează semnalele corecte, iar runbook-urile ghidează prin pașii de remediere. Astfel, monitorizarea devine o parte fiabilă a fluxului de lucru al incidentelor – nu un flux de notificări.
Migrație și integrare
Când trec de la sistemele vechi, lucrez o perioadă în paralel: Prometheus în paralel cu verificările existente, pentru a găsi lacune. Exportul îl derulez treptat, începând cu mediile de bază și preluând tablourile de bord din șabloane. Clienții primesc pachete de integrare cu SLO-uri, roluri și exemple de alerte predefinite; cerințele individuale le completez iterativ. Astfel, operațiunile rămân stabile, în timp ce echipele și clienții se obișnuiesc cu noile perspective.
Costuri, licențe și exploatare
Cu componentele open source reduc costurile de licență, dar planific în mod conștient timpul și Resurse pentru operare, întreținere și instruire. Grafana Enterprise poate fi utilă atunci când gestionarea drepturilor, rapoartele sau asistența devin importante, în timp ce variantele comunitare sunt suficiente pentru multe scenarii. Evaluez costurile de infrastructură în euro pe lună, inclusiv stocarea, rețeaua și backup-urile, pentru ca bugetele să rămână realiste. Pentru clienți, stabilesc cote clare pentru retenție și limite de interogare, pentru a asigura echitatea și performanța. Păstrez calculele transparente și le transfer în cataloage de servicii, astfel încât clienții să poată Pachete de servicii înțeleg.
Controlez costurile prin igiena metrică: elimin seriile temporale inutile, limitez etichetele foarte variabile și dimensionez retenția în funcție de utilitate. Urmăresc numărul de serii active per job și client și setez alerte atunci când pragurile sunt depășite. Pentru stocare, folosesc clase adecvate (rapide pentru TSDB operaționale, ieftine pentru termen lung) și planific traficul de rețea pentru scriere la distanță și rapoarte, astfel încât să nu existe surprize.
Viitorul: servicii gestionate și IA
Văd o tendință clară către platforme asistate, care reunesc metrici, jurnale și urme sub un singur acoperiș și oferă tablouri de bord self-service, ceea ce permite echipelor să lucreze mai repede. act. Detectarea anomaliilor bazată pe IA, pragurile adaptive și corelațiile automate reduc timpul de analiză. Testez mai întâi astfel de funcții în căi secundare, compar ratele de succes și le adaug în mod echilibrat la conceptul de alarmă. Pentru inspirație, merită să aruncați o privire la Monitorizare asistată de IA, care oferă idei privind automatizarea, jurnalele și previziunile. Astfel, pas cu pas, se creează un sistem de monitorizare care previne defecțiunile, stabilește ferestrele de întreținere în mod optim și Experiența utilizatorului ridică.

Rezumat pe scurt
Un structurat în mod clar Monitorizare-Stack cu Prometheus și Grafana îmi oferă o imagine fiabilă asupra infrastructurii, sarcinilor de lucru și aplicațiilor. Colectez metrici în mod cuprinzător, mențin interogările rapide și vizualizez concluziile astfel încât departamentul de asistență și clienții să poată lua decizii în siguranță. Alertele sunt specifice, jurnalele și urmele furnizează context, iar conceptele de drepturi protejează datele pentru fiecare client. Cu federație, scriere la distanță și reguli de înregistrare, sistemul se scalează fără a pierde din viteza de reacție. Cei care oferă servicii de găzduire profesionale și doresc să furnizeze SLA-uri clare vor avea succes pe termen lung cu acest stack. eficiente și transparent.