Sari la conținut
Sari la conținut 
Insist asupra unei strategii clare de backup 3-2-1 pentru găzduire web cu Backup pentru găzduire web, Copie de rezervă offsite, imutabilitate, RPO, RTO, GDPR și teste regulate de restaurare, astfel încât să pot supraviețui întreruperilor într-un mod controlat. Cer obiective măsurabile și procese trasabile, astfel încât regula de backup 3-2-1 să nu existe doar pe hârtie, ci să ofere rezultate rapide în caz de urgență.
Puncte centrale
- Regula 3-2-1Trei copii, două suporturi, o copie offsite - plus o copie de rezervă inalterabilă ca extra.
- FrecvențaBackup-uri zilnice, backup-uri orare ale bazei de date, versionare și PITR.
- ImuabilitateWORM/Object Lock previne ștergerea sau suprascrierea de către atacatori.
- RPO/RTOObiectivele clare și căile de restaurare testate minimizează timpul de inactivitate și pierderea datelor.
- TransparențăProtocoale, SLA, claritatea costurilor și teste regulate de restaurare.
Ce înseamnă de fapt 3-2-1 în găzduirea web?
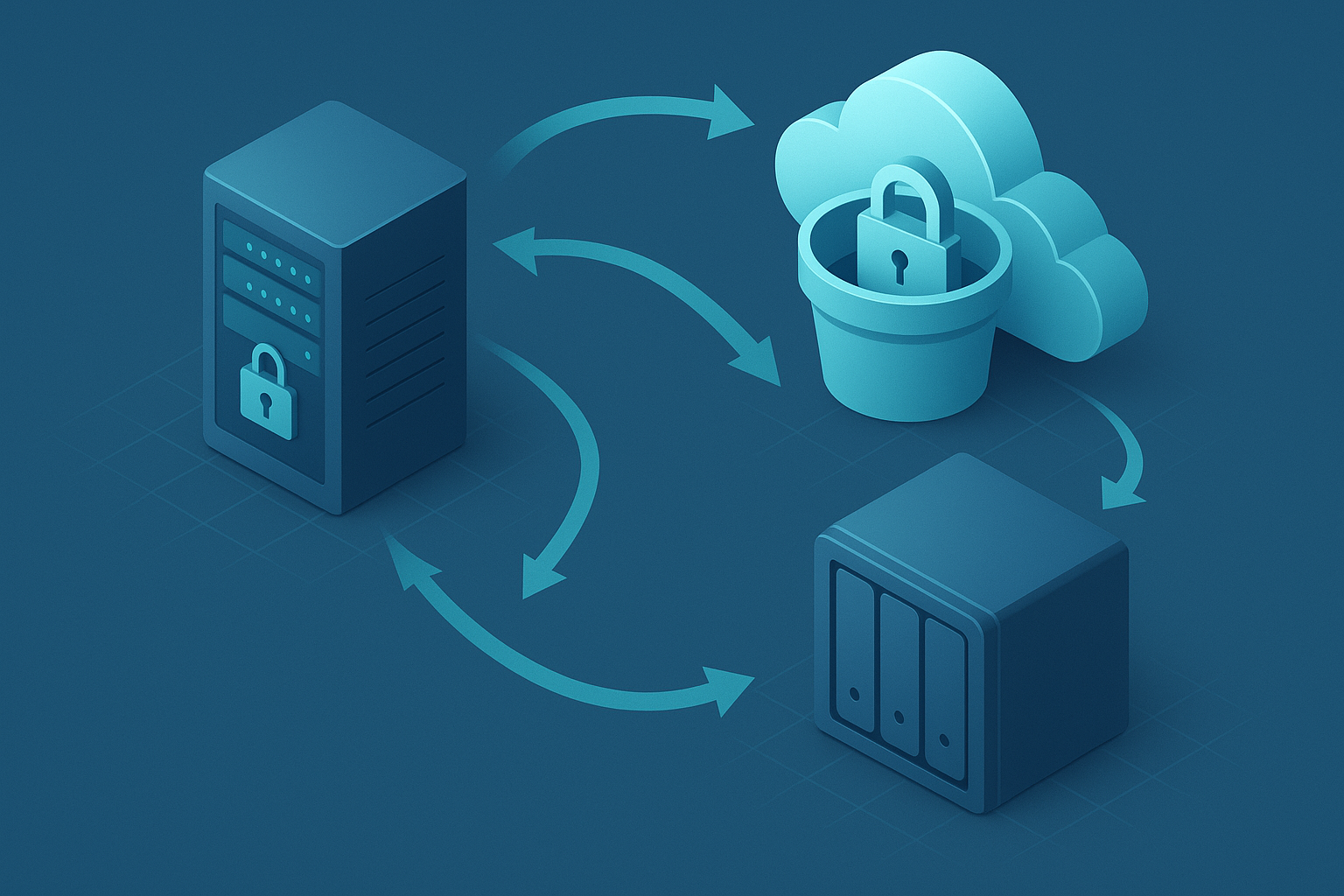
Am în vedere cel puțin trei exemplare: cel Original hosting, o a doua copie de siguranță pe un suport diferit și o a treia copie într-o locație diferită. În afara site-ului-locație. Două tipuri diferite de stocare reduc riscul de defecțiuni simultane cauzate de hardware, drivere de stocare sau ransomware. O copie separată din punct de vedere geografic mă protejează împotriva problemelor din centrele de date, a eșecurilor din zonele de incendiu și a erorilor de administrare. De asemenea, mă bazez pe extensia 3-2-1-1-0: o copie nealterabilă (WORM) plus copii de rezervă fără erori în suma de control. Astfel, șansele mele de recuperare rămân ridicate, chiar dacă sistemul de producție a fost complet compromis.

Lista de verificare: Ce insist de la hoster
Am nevoie de backup-uri complete ale Fișiere, Baze de date și e-mailuri - în mod consecvent, cu descărcări adecvate sau snapshot quiescing, astfel încât aplicațiile să se restaureze curat. Fără backup-uri coerente ale bazelor de date, pierd tranzacții sau tabele corupte. Verific dacă sunt disponibile backup-uri orare ale bazei de date și backup-uri zilnice ale sistemului de fișiere. Versionarea și restaurarea punctuală (PITR) pentru MySQL/MariaDB fac parte din acest lucru pentru mine. Acesta este singurul mod în care pot îndeplini în mod fiabil obiective RPO stricte.
Am nevoie de redundanță offsite într-un alt centru de date sau la un furnizor independent, astfel încât nicio organizație să nu devină un Singur Punct de eșec. Dacă gazda mea are mai multe regiuni, solicit o copie într-o zonă de incendiu diferită. Analizez cu atenție separarea fizică, căile de rețea și granițele administrative. O a doua organizație pentru copia offsite reduce riscul unor configurații greșite frecvente. De asemenea, mă interesez dacă stocarea în afara site-ului oferă imutabilitate reală.
Insist asupra backup-urilor inalterabile prin Imuabilitate/WORM pentru a preveni ștergerea datelor de către ransomware și erorile de operare. Blocarea obiectului cu reținere și reținere legală opțională previne suprascrierea până la expirarea perioadei de blocare. Documentez logica de păstrare, astfel încât să știu cât de mult mă pot întoarce în timp în caz de urgență. Acest lucru mă protejează și împotriva amenințărilor din interior. Folosesc perioade de păstrare mai lungi pentru datele deosebit de critice.
Backup-urile nu trebuie să ruleze cu aceleași conturi de administrator ca și sistemul de producție, motiv pentru care am nevoie de Cel mai puțin Privilegiu și conturi separate. MFA/2FA este obligatoriu, rolurile sunt strict separate, iar cheile sunt securizate. Verific dacă furnizorul oferă proiecte sau chiriași separați. Solicit jurnale de audit pentru acțiunile de backup și restaurare. Acest lucru îmi permite să detectez manipularea și accesul neautorizat într-un stadiu incipient.
Aplic criptarea peste tot: TLS în tranzit și criptare puternică în repaus, în mod ideal cu propriul meu Chei. Locațiile trebuie să fie conforme cu GDPR și semnez o DPA pentru a mă asigura că prelucrarea este conformă din punct de vedere juridic. Documentez perioadele de păstrare în conformitate cu cerințele de conformitate. Metadatele și indicii trebuie, de asemenea, să fie stocate în formă criptată. Acest lucru previne scurgerile de informații prin numele și structurile fișierelor.
Setați corect RPO și RTO
Definesc o pierdere maximă admisibilă de date (RPO) și un timp maxim de recuperare (RTO) și înregistrați-le pe amândouă în contract. Pentru magazine și portaluri, un RPO de 1 oră are adesea sens; pentru CMS cu puține tranzacții, 4-6 ore sunt de asemenea suficiente. Un RTO de 4 ore este realist pentru multe proiecte; platformele critice au nevoie de obiective mai rapide. Fără obiective clare de timp, nimeni nu planifică bugetul și arhitectura în mod corespunzător. Exercițiile de restaurare demonstrează dacă obiectivele sunt realizabile.
| Aspect | Descrierea | Valoare tipică | Verificare/testare |
|---|---|---|---|
| RPO | Maxim tolerat Pierderea datelor | 1 oră (DB cu PITR) | Binlogs, timestamps, restaurare la un punct în timp |
| RTO | Maximum Timpul de recuperare până la productivitate | 4 ore | Cărți de joc, cronometru, protocol |
| Depozitare | Versiuni și păstrare Zile | 7/30/90 | Plan, politică privind ciclul de viață, prezentare generală a costurilor |
| Frecvența de testare | Regular Restaurare-teste | lunar/trimestrial | Raport, verificare hash, capturi de ecran |
Documentez modul în care colectez valorile măsurate și instrumentele pe care le folosesc. Fără această transparență, RPO/RTO rămân teoretice și nu mă ajută în caz de urgență. De asemenea, înregistrez care sunt componentele critice și, prin urmare, le restaurez cu prioritate. Pentru bazele de date, definesc PITR și securizez binlogs în mod corespunzător. Pentru fișierele media, am nevoie de versionare și de o păstrare clară.

Punerea în aplicare practică a extravilanului și a imuabilității
Am plasat în mod constant a treia copie într-un alt Regiunea sau către un furnizor independent, astfel încât firewall-urile, conturile de administrare și facturarea să fie separate. Stocarea obiectelor cu imutabilitate activată (de exemplu, Object Lock) împiedică ștergerea în cadrul reținerii. Verific separarea regiunilor și verific dacă furnizorul utilizează zone de incendiu diferite. O bună introducere este oferită de prezentarea compactă a Regula 3-2-1 în găzduire. Acest lucru elimină riscul ca o configurație greșită să afecteze toate copiile.
Transfer doar backup-uri offsite în formă criptată și cu propriul meu Chei sau fraze de acces. De asemenea, izolez datele de acces, astfel încât o breșă pe serverul web să nu deschidă automat spațiul de stocare în afara site-ului. Aplic roluri IAM separate și MFA. Documentez protecția împotriva ștergerii într-o manieră inteligibilă, astfel încât auditurile să o poată evalua. Doar câteva persoane sunt autorizate să solicite modificări ale retenției.
Securitate: acces, criptare, GDPR
Separ strict accesele și dau doar backup-urilor minim drepturile necesare. Niciun cont root identic, nicio parolă comună, nicio cheie comună. Aplic MFA cu furnizorul și cu propriile mele conturi cloud. Criptez datele pe partea de client sau de server utilizând proceduri sigure. Acest lucru minimizează riscul ca un hoț să citească conținutul de pe suporturile de stocare.
Acord atenție conformității cu GDPR Locații și închei o APD cu o limitare clară a scopului. Verific dacă jurnalele conțin metadate care pot fi considerate personale. Înregistrez în scris conceptele de păstrare și ștergere. Am nevoie de procese inteligibile pentru cererile de informații și de ștergere. Acest lucru îmi asigură securitatea juridică și mă ferește de amenzi.
Test de restaurare: exersați restaurarea în mod regulat
Nu numai că testez recuperarea teoretic, dar, de asemenea, efectuez regulat Restaurare-exerciții pe un mediu de testare izolat. Măsor timpii, documentez etapele și rezolv obstacolele. Compar sumele de control ale fișierelor și verific coerența aplicațiilor prin intermediul verificărilor funcțiilor. Restaurez bazele de date la un moment dorit în timp (PITR) și verific tranzacțiile. Doar acest document arată dacă RPO/RTO sunt realiste.
Am pregătit playbook-urile: Ce persoană începe restaurarea, unde sunt datele de acces, cum contactez asistența, ce sisteme au prioritate. Scriu secvența: Mai întâi baza de date, apoi fișierele, apoi configurațiile. Păstrez informațiile importante Parole offline. Actualizez documentația și timpii după fiecare test. În acest fel, nu sunt surprins de o urgență reală.

Cum să vă construiți propriul setup 3-2-1
Eu rămân la structură: date productive pe Server web, a doua copie pe un NAS sau alt sistem de stocare, a treia copie în afara site-ului cu imutabilitate. Pentru fișiere, folosesc restic sau BorgBackup cu deduplicare și criptare. Pentru bazele de date, folosesc mysqldump, backup-uri logice cu blocaje consistente sau Percona XtraBackup. Pentru transferuri, folosesc rclone cu limită de lățime de bandă și repetiții.
Planific retenția în conformitate cu JRC (zilnic/săptămânal/lunar) și rezerv suficient Memorie pentru versionare. Cronjobs sau CI orchestrează backup-urile și verificările. Monitorizarea raportează erorile prin e-mail sau webhook. Acest articol oferă o clasificare compactă a Strategii de rezervă în găzduirea web. În acest fel păstrez controlul, chiar dacă hosterul meu oferă puțin.
Automatizare și monitorizare
Automatizez toate apelurile recurente Trepte și documentează comenzile exacte. Scripturile verifică codurile de ieșire, hash-urile și timestamps-urile. Backup-urile eșuate declanșează alarme imediate. Stochez jurnalele în mod centralizat și la adăpost de manipulări. De asemenea, limitez lățimea de bandă și efectuez verificări ale stării de sănătate a obiectivului din afara site-ului.
Discut cu gazda despre accesul la API, SFTP/rsync și punctele finale compatibile cu S3, astfel încât să pot utiliza căi de restaurare independente. Înregistrez costurile pentru serviciile de ieșire și de restaurare, astfel încât să nu existe surprize la final. Verific dacă este posibilă restaurarea prin autoservire pentru fiecare Fișiere și conturile complete sunt disponibile. Dacă nu, îmi planific propriile instrumente. Acest lucru îmi economisește timp în caz de urgență.

Greșeli frecvente - și cum să le evitați
Nu mă bazez niciodată pe un singur Copiați sau același sistem de stocare. Instantaneele singure nu sunt suficiente pentru mine dacă nu sunt nici offsite, nici imuabile. Verific consecvența bazei de date în loc să copiez doar fișiere. Testele de monitorizare și de restaurare fac parte din calendarul meu. Stocarea neclară sau lipsa versiunilor cauzează perioade lungi de nefuncționare în caz de urgență.
Verific, de asemenea, dacă costurile de restaurare sunt transparente și dacă nicio taxă nu întârzie restaurarea. Evit conturile de administrare partajate și folosesc MFA peste tot. Înregistrez procedurile pentru rotația cheilor. Efectuez cel puțin o verificare trimestrială Test-Refaceți prin. Erorile rezultate în urma acestor exerciții se regăsesc în playbook-urile mele.
SLA, transparență și costuri
Am arhitectura de rezervă cu Diagrame și procese. Acestea includ rapoarte de monitorizare, trasee de alarmă și timpi de răspuns. Solicit contacte de urgență 24 de ore din 24, 7 zile din 7 și solicit ferestre de timp în care restaurările sunt prioritizate. De asemenea, solicit tabele clare de costuri pentru stocare, ieșire și servicii. Dacă acestea lipsesc, planific amortizoare suplimentare în buget.
Pentru proiectele critice, combin backup-urile cu DR-scenarii și evitarea punctelor unice de eșec. Aici merită să aruncați o privire la Recuperarea în caz de dezastru ca serviciu, dacă doresc să reduc timpii de failover. Documentez lanțurile de escaladare și datele de testare. De asemenea, mențin canale de contact redundante. În acest fel, mă asigur că nimeni nu confirmă responsabilitățile care lipsesc într-o situație de urgență.

Ce să mai salvez - în afară de fișiere și baze de date?
Nu protejez doar webroot-ul și baza de date, ci și toate componentele care alcătuiesc platforma mea. Aceasta include zone DNS, certificate TLS, cronjobs, configurații ale serverului web și PHP, fișiere .env, chei API, chei SSH, reguli WAF/firewall, redirecționări și filtre de e-mail. De asemenea, export liste de pachete, fișiere de blocare composer/npm și configurații de aplicații. Pentru e-mail, mă bazez pe backup-uri complete ale folderelor maildir și pe exporturi separate ale aliasurilor și ale regulilor de transport. Pentru găzduirea de conturi multiple, realizez, de asemenea, copii de siguranță ale configurațiilor panoului, astfel încât să pot restaura conturi întregi într-o manieră trasabilă.
Iau decizii conștiente cu privire la ceea ce nu sigure: Las deoparte cache-urile, sesiunile, încărcările temporare și artefactele generabile (de exemplu, imaginile optimizate) pentru a economisi costuri și a scurta timpul de restaurare. În ceea ce privește indicii de căutare sau cache-urile fine, documentez modul în care acestea sunt reconstruite automat în cazul unei restaurări.
Compararea metodelor și topologiilor de rezervă
Aleg metoda potrivită pentru fiecare volum de lucru: dump-urile logice (de exemplu, mysqldump) sunt portabile, dar durează mai mult. Backup-urile fizice la cald (de exemplu, prin mecanisme snapshot) sunt rapide și consecvente, dar necesită funcții de stocare adecvate. Folosesc quiescing (fsfreeze/LVM/ZFS) atunci când este posibil și binlogs InnoDB securizate pentru PITR adevărat. Pentru copiile de siguranță ale fișierelor, mă bazez pe sistemul incremental-forever cu deduplicare.
Mă decid între topologia push și pull: cu pull, un server de backup inițiază backup-ul și reduce riscul de compromitere a sistemelor sursă. Cu push, serverele de aplicații inițiază ele însele backup-urile - acest lucru este mai simplu, dar necesită o separare IAM strictă și controale de ieșire. Metodele bazate pe agenți oferă o mai mare coerență, iar metodele fără agenți sunt mai ușor de utilizat. Îmi documentez alegerea și riscurile.
Granularitate și căi de recuperare
Planific mai multe tipuri de restaurări: fișiere individuale, foldere, tabele individuale/înregistrări de date, baze de date întregi, căsuțe poștale, conturi complete de găzduire web. Pentru sistemele CMS/magazine, prioritizez „DB first, then uploads/media, then configuration“. Am pregătită o abordare albastră/verde: restaurare în staging, validare, apoi comutare controlată. Acest lucru minimizează timpul de indisponibilitate și reduce surprizele în timpul funcționării productive.
Mă asigur că restaurările self-service sunt posibile: Utilizatorii pot selecta în mod independent o versiune, pot căuta puncte temporale și le pot restaura într-un mod direcționat. Am pregătit un proces de tip „break-glass“ pentru situații de urgență: Acces de urgență cu logare, limitat în timp și bazat pe principiul controlului dublu.
Integritate, sume de control și corupere silențioasă a datelor
Am încredere doar în copiile de siguranță cu integritate end-to-end. Fiecare artefact primește sume de control (de exemplu, SHA256), care sunt stocate separat și verificate periodic. Planific lucrări de curățare care citesc obiectele din afara site-ului în mod aleatoriu sau complet și compară hașurile. Acest lucru îmi permite să detectez în stadiu incipient putregaiul biților sau erorile de transmisie. De asemenea, salvez fișiere de manifest cu trasee, dimensiuni și hash-uri pentru a putea detecta lacunele.
Automatizez testele de restaurare ca dovadă a integrității: restaurări zilnice aleatorii ale fișierelor, restaurări săptămânale complete ale BD cu PITR, teste lunare de la un capăt la altul, inclusiv verificarea sănătății aplicației. Rezultatele ajung în rapoarte cu marcaje temporale, extrase din jurnale și capturi de ecran.
Performanță, calendar și resurse
Definesc ferestre de timp pentru backup care evită vârfurile de încărcare și respectă timpii de tranzacționare. Deduplicarea, compresia și execuțiile incrementale reduc volumul de transfer și de stocare. Limitez lățimea de bandă (rclone/restic throttle), mă bazez pe încărcări paralele și chunking și iau în considerare bugetele CPU și IO. Fac backup diferențiat pentru stocurile media mari și le împart în segmente pentru a evita timeout-urile. Documentez cât durează o execuție completă și incrementală - și dacă aceasta se armonizează cu RPO/RTO.
Planificarea capacității și a costurilor
Calculez capacitățile în mod conservator: inventarul de date, rata de modificare zilnică, factorul de compresie/dedupe, nivelurile de retenție (GFS). Din aceste date, generez o previziune lunară și limite bugetare superioare. Planific diferite clase de stocare (fierbinte/cald/frigid) și stabilesc politici privind ciclul de viață pentru schimbări automate în cadrul retenției. Înregistrez costurile de ieșire, API și restaurare. Compar costurile preconizate ale unei întreruperi (pierderi de venituri, penalizări SLA) cu cheltuielile de backup - acesta este modul în care formulez argumente bazate pe buget.
Organizare, roluri și principiul controlului dublu
Separ strict rolurile: orice persoană care salvează nu are voie să șteargă; orice persoană care modifică retenția are nevoie de autorizație. Acțiunile critice (ștergerea, scurtarea păstrării, dezactivarea imuabilității) se desfășoară în conformitate cu principiul controlului dublu, cu trimitere la bilet. Am definit lanțuri de escaladare, substituții și soluții de rezervă. Accesurile de tip break-glass sunt sigilate, limitate în timp și reînnoite prin rotație după utilizare. Jurnalele de audit consemnează toate acțiunile în mod nealterabil.
Particularități ale platformelor comune
Pentru WordPress, fac o copie de rezervă a bazei de date, a conținutului wp (încărcări, teme, pluginuri), precum și a wp-config.php și a sărurilor. Pentru magazine, se adaugă statele de coadă/job, pluginurile de plată și expediere și CDN-urile media. Pentru configurațiile multisite, documentez atribuirea domeniilor către site-uri. De asemenea, securizez setările de redirecționare și SEO pentru a evita pierderile de trafic după restaurare. Fac o copie de rezervă a indicilor de căutare (de exemplu, Elasticsearch/OpenSearch) ca instantaneu sau îi reconstruiesc cu ajutorul scripturilor, astfel încât funcțiile de căutare să fie din nou disponibile rapid după o restaurare.
Recuperarea în caz de dezastru și reproductibilitatea infrastructurii
Minimizez RTO făcând infrastructura reproductibilă: configurare ca cod (de exemplu, setările serverului și ale panoului), implementări repetabile, versiuni fixe. Păstrez secretele aplicațiilor criptate și versionate și le rotesc după un incident de securitate. Planific locații alternative pentru DR și documentez modul în care schimb DNS, TLS, caching și rutarea corespondenței în cazul unei crize. Înregistrez dependențele (API-uri terțe, furnizori de plăți) și pregătesc soluții de rezervă.
Lege și conformitate în contextul de rezervă
Armonizez perioadele de păstrare cu obligațiile de ștergere: Pentru datele cu caracter personal, definesc procese privind modul în care implementez practic cererile de ștergere fără a pune în pericol integritatea backup-urilor istorice. Documentez categoriile de date care ajung în copiile de siguranță și minimizez metadatele. Descriu TOM (măsuri tehnice și organizatorice) într-o manieră verificabilă: criptare, control al accesului, înregistrare, imuabilitate, limite geografice. Înregistrez riscurile pentru transferurile din țări terțe și decid asupra locațiilor în funcție de cerințele mele de conformitate.

Teste practice și cifre-cheie
Definesc indicatori cheie de performanță clari: rata de succes a backup-ului, vârsta ultimului backup reușit, timpul până la primul octet în restaurare, timpul de restaurare completă, ratele de eroare pe sursă, numărul de versiuni verificate, timpul până la alertă. Compar periodic acești indicatori cu obiectivele mele RPO/RTO. Planific zile de joc: eșecuri țintite și controlate (de exemplu, foldere șterse în mod deliberat) pentru a testa căile de răspuns, alertele și căile de restaurare sub presiune. Rezultatele intră în programul meu de îmbunătățire.
Întrebări frecvente scurte
Cât de des fac o copie de rezervă corectă? Eu folosesc zilnic Backup-uri pentru fișiere și backup-uri orare pentru bazele de date; aleg intervale mai scurte pentru traficul intens. Cât timp păstrez versiunile? 30-90 de zile este o perioadă obișnuită; de asemenea, păstrez lunar versiuni pe termen lung. Ce este RPO vs. RTO? RPO este pierderea maximă de date, iar RTO este timpul până când totul este din nou online. Scriu ambele în contracte și testez valorile.
Cum securizez e-mailurile? Extrag maildir/cutiile poștale separat și testez Restaurare un singur dosar. Cum procedez cu fișierele media de mari dimensiuni? Deduplicarea și copiile de siguranță incrementale reduc costurile; versionarea permite restaurarea direcționată. Ce înseamnă imutabilitatea în practică? Protecția la ștergere cu reținere împiedică manipularea până la expirare. Cum integrez WordPress sau magazinele? Fac copii de siguranță ale fișierelor, ale bazei de date și ale configurației și documentez secvența.
Rezumat pe scurt
Eu insist pe 3-2-1 cu În afara site-ului și imutabilitate, obiective clare RPO/RTO, teste regulate și documentație curată. Ancorăm responsabilități, playbook-uri și valori măsurate. Cer restaurări self-service și costuri trasabile. Respect cerințele GDPR, inclusiv AVV și chei și conturi strict securizate. Acest lucru îmi permite să revin online rapid după un incident - cu un efort previzibil și o calitate trasabilă.