
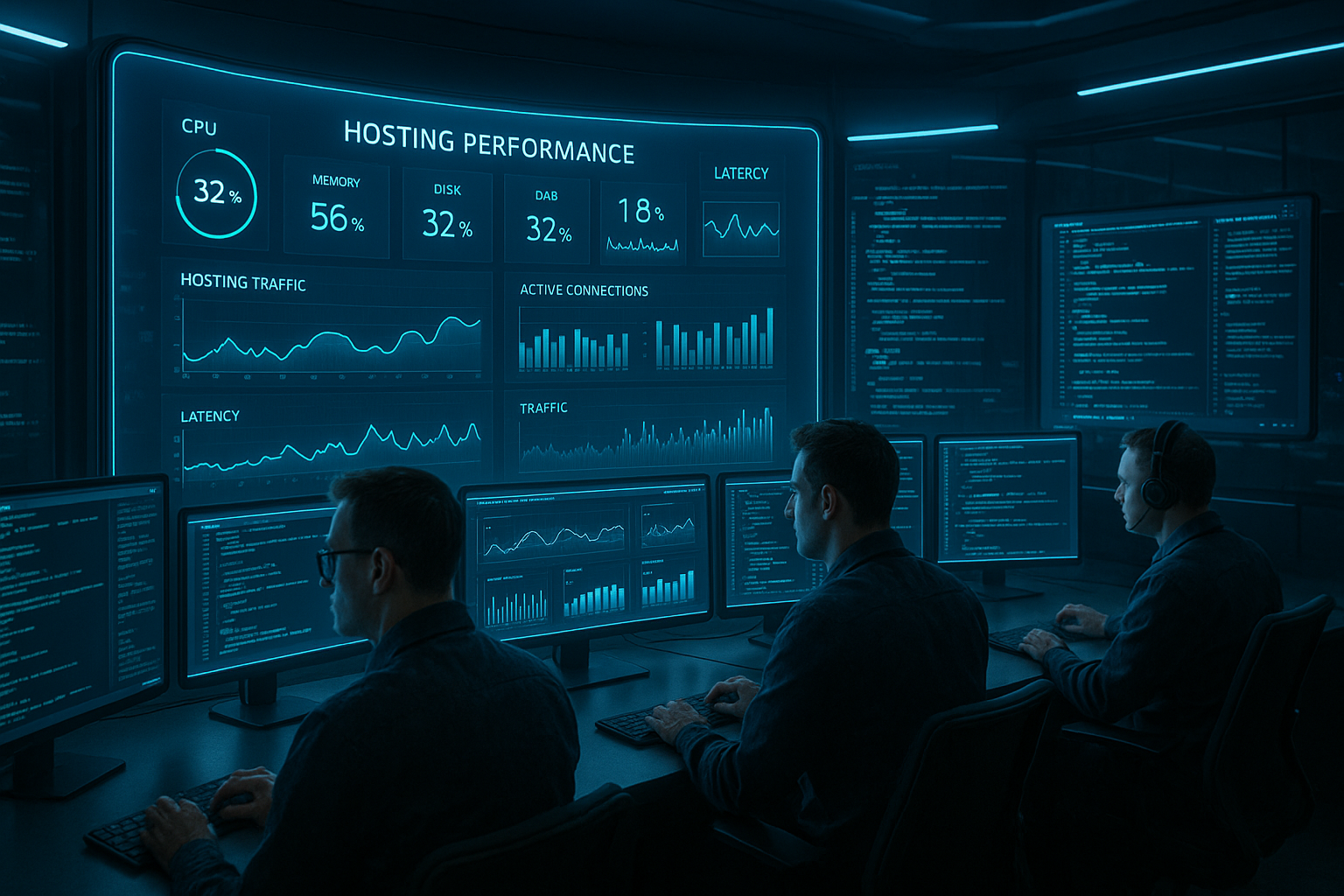
S spremljanjem zmogljivosti gostovanja zgodaj prepoznam ozka grla zmogljivosti, ker Orodja in . Dnevniki mi v realnem času posreduje ustrezne signale. S proaktivnimi opozorili, zaznavanjem anomalij in čisto koreliranimi dnevniškimi podatki ohranjam nizke zakasnitve, preprečujem izpade in podpiram vidnost pri iskanju.
Osrednje točke
Jasne ključne številke, samodejna opozorila in smiselni dnevniški podatki so zame prioriteta, saj mi omogočajo hitro diagnosticiranje in varovanje delovanja. Strukturiran postopek nastavitve preprečuje merilni kaos in ustvarja zanesljivo podatkovno podlago za utemeljene odločitve. Izberem malo, a smiselnih nadzornih plošč, da v stresnih situacijah ne izgubim pregleda nad dogajanjem. Integracije na področju klepeta in izdajanja vozovnic skrajšajo odzivni čas in zmanjšajo število eskalacij. Navsezadnje je pomembno, da spremljanje merljivo zmanjša čas izpada in izboljša uporabniško izkušnjo, namesto da bi ustvarjalo dodatno zapletenost; da bi to dosegel, se zanašam na jasne Standardi in dosledno Uglaševanje.
- Metrike določite prednostne naloge: zakasnitev, stopnja napak, izkoriščenost
- Dnevniki centralizacija: strukturirana polja, kontekst, zadrževanje
- Opozorila avtomatizirati: Pragovi, SLO, poti eskalacije
- Integracije uporaba: Slack/Email, Vstopnice, ChatOps
- Primerjava orodja: Funkcije, stroški, napori

Zakaj je proaktivno spremljanje pomembno
Ne čakam na pritožbe iz podpore, ampak prepoznam Napovedi in . Anomalije zgodaj ugotovite, kam gredo sistemi. Vsaka milisekunda zakasnitve vpliva na konverzijo in SEO, zato opazujem stalne trende in ne enkratne vrhunce. Tako lahko prekinem nepotrebne odvisnosti in ustvarim blažilnike, preden se pojavijo konice obremenitve. Napake se pogosto oglasijo same: stopnja napak se poveča, čakalne vrste se povečajo, zbiralniki smeti delujejo pogosteje. Z branjem teh znakov preprečim izpade, zmanjšam stroške in povečam zaupanje.
Katere metrike so resnično pomembne
Osredotočam se na nekaj ključnih vrednosti: zakasnitev Apdex ali P95, stopnja napak, CPU/RAM, I/O, zakasnitev omrežja in razpoložljive povezave DB, tako da lahko stanje določim v nekaj sekundah. Brez jasnosti glede virov pogosto spregledam vzrok, zato sem pozoren na korelirane poglede na vseh ravneh. Pri pogledu na gostitelja mi pomaga naslednje Spremljanje izkoriščenosti strežnikada hitro vidite ozka grla na ravni vozlišč. Namenoma ocenjujem intervale merjenja, saj 60-sekundni intervali spregledajo kratke konice, medtem ko 10-sekundni intervali pokažejo drobnejše vzorce. Še vedno je pomembno, da se meritve zrcalijo glede na opredeljene cilje SLO, sicer izgubim Prednostna naloga in Kontekst.
Načrtovanje metrik: USE/RED, histogrami in kardinalnost
Signale strukturiram v skladu s preizkušenimi metodami: Na ravni gostitelja uporabljam okvir USE (Utilisation, Saturation, Errors), na ravni storitev pa model RED (Rate, Errors, Duration). To zagotavlja, da je vsak graf ciljno usmerjen in preverljiv. Zakasnitve merim s histogrami in ne le s povprečnimi vrednostmi, tako da so P95/P99 zanesljivi in regresije vidne. Čisto opredeljeni vedri preprečujejo izenačevanje: preveč grobi podatki pogoltnejo konice, preveč drobni pa povečajo pomnilnik in stroške. Pri visokofrekvenčnih končnih točkah imam pripravljene podatke o kopijah, tako da lahko sledim posameznim počasnim zahtevkom.
Kardinalnost je zame nadzorni vzvod: oznake, kot so user_id ali request_id, spadajo v dnevnike/sledi, redko pa v metriko. Nizi oznak so majhni, zanašam se na storitev/različico/regijo/okolje in dokumentiram standarde poimenovanja. Tako so nadzorne plošče hitre, shranjevanje načrtovano, poizvedbe pa jasne. Metrike (npr. http_server_duration_seconds_v2) razlikujem, ko spremenim vedra, tako da zgodovinske primerjave ne zastarajo.

Dnevniki kot sistem zgodnjega opozarjanja
Dnevniki mi pokažejo, kaj se v resnici dogaja, saj so v njih vidni poti kode, časovni potek in uporabniški kontekst. Polja, kot so trace_id, user_id, request_id in service, strukturiram tako, da lahko sledim zahtevkom od začetka do konca. Za operativno delo uporabljam Analiza dnevnikovhitrejše prepoznavanje virov napak, najvišjih vrednosti zakasnitev in varnostnih vzorcev. Brez jasno opredeljenih ravni dnevnika postane količina draga, zato razhroščevanje uporabljam poredko in ga povečam le za kratek čas. Določim obdobja hranjenja, filtre in maskiranje, tako da podatki ostanejo uporabni, zakonsko skladni in jasno namesto razpotegnjeno.
Stroški pod nadzorom: kardinalnost, zadržanje, vzorčenje
Aktivno nadzorujem stroške: podatke dnevnika ločujem na vroče/tople/hladne nivoje, vsak s svojim načinom shranjevanja in stiskanja. Ob vnosu normaliziram ali dedupliciram okvarjene, izjemno glasne dogodke, tako da ne prevladujejo na nadzornih ploščah. Sledi vzorčim dinamično: napake in visoke zakasnitve vedno, običajne primere le sorazmerno. Pri metrikah izberem zmanjševanje vzorčenja za dolgoročne trende in ohranjam kratke neobdelane podatke, tako da je izkoriščenost shrambe predvidljiva. Nadzorna plošča stroškov z zneski €/gostitelj, €/GB in €/opozorilo naredi porabo vidno; proračunska opozorila preprečujejo presenečenja ob koncu meseca.
Primerjava orodij: prednosti na prvi pogled
Raje imam rešitve, ki združujejo dnevnike, metrike in sledove, saj mi pomagajo hitreje najti temeljne vzroke. Better Stack, Sematext, Sumo Logic in Datadog pokrivajo številne scenarije aplikacij, vendar se razlikujejo po svoji usmeritvi, delovanju in cenovni logiki. Za ekipe, ki uporabljajo Kubernetes in AWS, se izplača tesna integracija oblaka. Če želite obdržati podatke, morate biti pozorni na možnosti izvoza in dolgoročno shranjevanje. Pred odločitvijo preverim TCO, napor pri vzpostavitvi in krivuljo učenja, saj ugodne tarife nimajo veliko smisla, če se napor poveča in Ugotovitve na koncu redko ostanejo.
| Orodje | Focus | Prednosti | Idealno za | Cena/naloga |
|---|---|---|---|---|
| Boljši kup | Dnevniki + Čas delovanja | Preprost vmesnik, hitro iskanje, dobre nadzorne plošče | Startupi, ekipe z jasnimi delovnimi tokovi | od približno dvomestne številke € na mesec, odvisno od obsega |
| Sematext | Upravljanje dnevnika, podobno kot pri ELK | Številne integracije, opozorila v realnem času, infrastruktura + aplikacija | Hibridna okolja, vsestranska telemetrija | v obsegu GB/dan, od dvomestne številke € na mesec. |
| Sumo Logic | Analitika dnevnika | zaznavanje trendov, anomalij, napovedne analize | Ekipe za varnost in skladnost | Na podlagi obsega, srednja do višja raven € |
| Datadog | Dnevniki + metrike + varnost | Anomalije ML, zemljevidi storitev, močna povezava z oblakom | Skaliranje delovnih obremenitev v oblaku | modularna cena, ločene funkcije, € odvisno od obsega |
Orodja preizkušam s pravimi vrhovi namesto z umetnimi vzorci, da lahko pošteno vidim meje zmogljivosti. Zanesljiv POC vključuje podatkovne cevovode, opozarjanje, usmerjanje na klic in koncepte avtorizacije. Premaknem se šele, ko so krivulje razčlenjevanja, zadrževanja in stroškov pravilne. Na ta način se izognem kasnejšim trenjem in ohranjam vitko pokrajino orodij. Na koncu je pomembno, da orodje izpolnjuje moje Ekipa hitreje in Napakacitatne stiskalnice.
Nastavitev samodejnih opozoril
Vrednosti praga določam na podlagi ciljev SLO in ne na podlagi občutka, tako da alarmi ostanejo zanesljivi. Zamuda P95, stopnja napak in dolžina čakalne vrste so primerni kot začetne varovalke. Vsak signal potrebuje pot eskalacije: klepet, telefon, nato prijava incidenta z jasnim lastništvom. Časovno zasnovano zatiranje preprečuje poplave alarmov med načrtovanimi uvajanji. Dokumentiram merila in odgovornosti, da lahko novi člani ekipe delujejo samozavestno in Pripravljenost ni v Utrujenost zaradi alarma nagibi.
Pripravljenost na incidente: priročniki, vaje, obdukcije
O knjigah poteka razmišljam kot o kratkih drevesih odločanja in ne kot o romanih. Dober alarm je povezan z diagnostičnimi koraki, kontrolnimi seznami in možnostmi povratka. Eskalacije vadim na suhih vajah in igralnih dnevih, da ekipa ostane mirna tudi v resničnih primerih. Po incidentih napišem naknadno poročilo brez krivde, opredelim konkretne ukrepe z lastnikom in rokom izvedbe ter jih zasidram v načrtu. Merim MTTA/MTTR in natančnost alarmov (resnični/nepravilni pozitivni rezultati), da lahko ugotovim, ali so moje izboljšave učinkovite.
Integracije, ki delujejo v vsakdanjem življenju
Kritična opozorila preusmerim v Slack ali e-pošto, v primeru visoke prioritete pa tudi s telefonskim klicem, tako da nihče ne zamudi dogodkov. Integracije vozovnic zagotavljajo, da se na podlagi opozorila samodejno ustvari naloga s kontekstom. Spletne kljuke (webhooks) povežem z dnevniki izvedbe, ki predlagajo korake ukrepanja ali celo sprožijo sanacijo. Dobre integracije opazno skrajšajo MTTA in MTTR ter ohranjajo mirne živce. Pomembno je, zlasti ponoči, da so procesi učinkoviti, da so vloge jasne in da so Akcija prihaja hitreje kot Negotovost.
Od simptomov do vzrokov: APM + dnevniki
Spremljanje delovanja aplikacij (APM) kombiniram s korelacijo dnevnikov, da vidim poudarjene poti napak. Sledi mi pokažejo, katera storitev se upočasnjuje, dnevniki pa zagotavljajo podrobnosti o izjemi. Tako lahko razkrijem N+1 poizvedbe, počasne API-je tretjih oseb ali okvarjene predpomnilnike, ne da bi mi bilo treba tipati v temi. Vzorčenje uporabljam ciljno usmerjeno, tako da stroški ostanejo dostopni, vroče poti pa so popolnoma vidne. S to povezavo ciljno določim popravke, zaščitim hitrost izdaje in povečam kakovost z manj Stres.

Signali DB, predpomnilnika in čakalne vrste, ki štejejo
Pri podatkovnih zbirkah ne spremljam le procesorja, temveč tudi izkoriščenost bazena povezav, čakalne čase za zaklepanje, zamik replikacije in delež najpočasnejših poizvedb. Pri predpomnilnikih me zanimajo stopnja zadetkov, evikcije, zakasnitev polnjenja in delež zastalih branj; če se stopnja zadetkov zmanjša, obstaja nevarnost, da se v podatkovni zbirki sprožijo lavinski učinki. Pri čakalnih vrstah sem pozoren na starost zaostankov, zamik porabnikov, prepustnost na porabnika in delež mrtvih črk. Na strani JVM/.NET merim premor GC, izkoriščenost kupa in zasičenost sklada niti, da lahko pošteno vidim rezervo.
Praktični priročnik: Prvih 30 dni spremljanja
V prvem tednu razjasnim cilje, SLO in metrike, vzpostavim osnovne nadzorne plošče in zabeležim najpomembnejše storitve. V drugem tednu aktiviram dnevniške cevovode, normaliziram polja in nastavim prva opozorila. V tretjem tednu popravim mejne vrednosti, povežem knjige izvedbe in preizkusim eskalacije v suhem postopku. V četrtem tednu optimiziram stroške s profili zadržanja in preverim razumljivost nadzornih plošč. Končni rezultat so jasni priročniki, zanesljivi alarmi in merljivi Izboljšaveki jih imam v Ekipa deli.
Načrtovanje zmogljivosti in preizkusi odpornosti
Zmogljivosti ne načrtujem na podlagi občutka, temveč na podlagi trendov, porabe SLO in profilov obremenitve. Ponovitve prometa iz dejanskih uporabniških tokov mi pokažejo, kako se sistemi odzivajo ob največjih obremenitvah. Samodejno skaliranje preizkušam s časom povečanja in varnostnimi kopijami (min/max), da me hladni zagoni ne bi presenetili. Kanarske izdaje in postopno uvajanje omejujejo tveganje; spremljam porabo proračunskih sredstev za napake na izdajo in zaustavim uvajanje, če se SLO prevrnejo. Vaje s kaosom in odpovedjo dokazujejo, da HA ni le pobožna želja: izklopite regijo, izgubite vodjo podatkovne zbirke, preverite odpoved DNS.
Izbira ponudnika gostovanja: Na kaj sem pozoren
Preverjam pogodbeno razpoložljivost, odzivni čas podpore in dejansko zmogljivost pod obremenitvijo, ne le tržne trditve. Zame je pomembno, kako hitro se odzivajo strežniki, kako dosledno deluje pomnilnik in kako hitro so na voljo popravki. Ponudniki, kot je webhoster.de, točkujejo z dobrimi paketi in zanesljivo infrastrukturo, ki opazno varuje projekte. Zahtevam pregledne strani s stanjem, jasna okna za vzdrževanje in smiselne metrike. Če izpolnite te točke, zmanjšate tveganje, omogočite Spremljanje in ščiti Proračun.

Edge, DNS in certifikati na prvi pogled
Spremljam ne le izvor, temveč tudi rob: stopnjo zadetkov v predpomnilniku CDN, izvorne nadomestne rešitve, porazdelitev stanja HTTP in zakasnitve na POP. Preverjanja DNS se izvajajo iz več regij; preverjam stanje NS, TTL in stopnje napak pri ponovnem iskanju. Potrdila TLS predčasno potečejo (alarm 30/14/7 dni vnaprej), spremljam šifrirne komplete in čase pretresov, saj ti označujejo zaznano zmogljivost. Sintetične poti prikažejo kritične poti uporabnikov (prijava, odjava, iskanje), RUM pa mi pokaže dejanske končne naprave, omrežja in različice brskalnikov. Oboje skupaj predstavlja zunanji pogled in lepo dopolnjuje strežniške metrike.
Čas delovanja, cilji SLO in proračuni
Razpoložljivost merim z zunanjimi preverjanji, ne le z notranjimi, tako da lahko prikažem prave poti uporabnikov. Cilj ravni storitev brez merilne točke ostaja trditev, zato cilje ravni storitev združujem z neodvisnimi preverjanji. Primerjava, kot je npr. Spremljanje brezhibnostihitro ocenite pokritost, intervale in stroške. Načrtujem proračune na GB dnevnika, na gostitelja in na interval preverjanja, tako da so stroški predvidljivi. Kdor poskrbi, da so napake SLO vidne, jasno argumentira načrte in zmaga Podpora z vsakim Določanje prednostnih nalog.

Podatkovni cevovod in kontekst: čisto povezovanje telemetrije
Zanašam se na neprekinjen kontekst: trace_id in span_id se znajdeta v dnevnikih, tako da lahko skočim neposredno iz dnevnika napak v sled. Dogodke uvajanja, oznake funkcij in spremembe konfiguracije beležim kot ločene dogodke; korelacijski prekrivki na grafih kažejo, ali sprememba vpliva na metrike. Pozoren sem na higieno oznak: jasni imenski prostori, dosledni ključi in trdne omejitve za preprečevanje nenadzorovane rasti. Vzorčenje na podlagi repa daje prednost neobičajnim razponom, medtem ko vzorčenje na podlagi glave zmanjšuje obremenitev; za vsako storitev kombiniram oboje. Tako ohranjam ostre vpoglede in stabilne stroške.
Ergonomija dežurstva in zdravje ekipe
Alarme strukturiram glede na resnost, tako da vas ne zbudi vsak udarec. Povzeti dogodki (združevanje v skupine) in mirni časi zmanjšujejo hrup, ne da bi povečali tveganje. Rotacije so pravično razporejene, predaje so dokumentirane, rezervna enota pa je jasno imenovana. Merim obremenitev pagerja na osebo, stopnjo lažnih alarmov in nočne intervencije, da preprečim utrujenost zaradi alarmov. Usposobljeni ukrepi prve pomoči (priročnik za prve posredovalce) zagotavljajo varnost; bolj poglobljene analize sledijo šele, ko so razmere stabilne. Na ta način pripravljenost ostane trajnostna, ekipa pa odporna.
Integracija signalov o varnosti in skladnosti
Na varnost gledam kot na del spremljanja: anomalije v številu prijav, nenavadni skupki IP, vzorci 4xx/5xx in dnevniki WAF/avdita se stekajo v moje nadzorne plošče. Dosledno prikrivam podatke o zasebnosti; vidno je le tisto, kar je potrebno za diagnostiko. Hrambo in pravice dostopa organiziram glede na potrebo po seznanitvi, revizijske sledi pa dokumentirajo poizvedbe po občutljivih podatkih. Tako ohranjam ravnovesje med varnostjo, diagnostiko in skladnostjo, ne da bi pri tem izgubil operativno hitrost.
Kratek povzetek
Spremljanje je vitko, merljivo in usmerjeno v ukrepanje, tako da deluje vsak dan. Osnovne metrike, centralizirani dnevniki in jasna opozorila mi omogočajo hitro diagnosticiranje in odzivanje. Z usmerjenim naborom orodij prihranim stroške, ne da bi pri tem žrtvoval vpogled. Integracije, priročniki za izvajanje in SLO omogočajo, da je delo ob incidentih mirnejše in sledljivo. To pomeni, da spremljanje učinkovitosti gostovanja ni samo sebi namen, temveč Vzvod za boljše Razpoložljivost in stabilne uporabniške poti.


