 Hoppa till innehåll
Hoppa till innehåll 
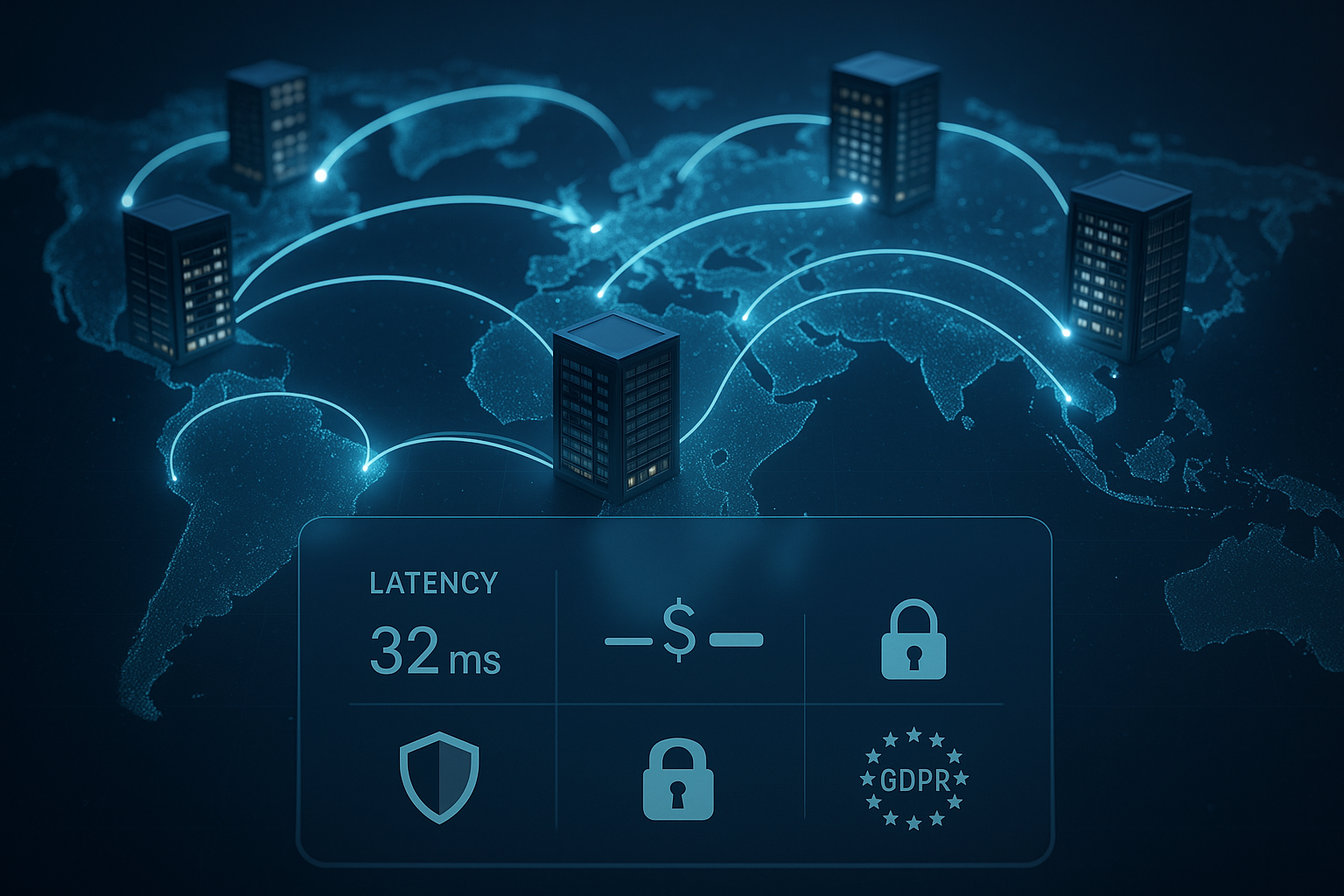
Serverns placering avgör hur snabbt sidorna laddas, hur säkra personuppgifter förblir och vilka löpande kostnader jag planerar för globala användare. Den som vill minimera latens, Uppgiftsskydd och utgifter kombineras strategiskt, vilket ger mätbart bättre laddningstider, stabila konverteringar och tydliga fördelar när det gäller efterlevnad för internationella målgrupper.
Centrala punkter
Följande aspekter utgör riktlinjerna för mitt beslut om platsval.
- Fördröjning: Närhet till användaren minskar millisekunder och ökar omsättningen.
- Uppgiftsskydd: EU-kontor underlättar efterlevnaden av GDPR.
- Kostnader: Energi, trafik och support avgör den totala kostnaden.
- Skalning: Multi-Region och CDN säkerställer global prestanda.
- SEO: Snabba svarstider stärker rankningen och crawlbudgeten.

Vad „serverplatshosting“ konkret innebär
Jag träffar med Serverns placering Ett geografiskt och juridiskt beslut: Valet av land eller stad påverkar latens, tillgänglighet, datatillgång och till och med supportkvaliteten. Det fysiska avståndet till besökaren avgör transporttiden för datapaketen och därmed den upplevda reaktionshastigheten. Samtidigt gäller lagarna på platsen, vilket gör en betydande skillnad när det gäller personuppgifter. Den som är verksam i hela Europa drar nytta av enhetliga regler inom EU, medan den som arbetar globalt måste kontrollera ytterligare krav. Jag betraktar därför alltid platsen som en hävstång för prestanda, rättssäkerhet och beräkningsbarhet. Totala kostnader.
Nätverksanslutning och peering som lokaliseringsfaktor
Förutom den rena distansen avgör även Nätets kvalitet datacenter. Jag kontrollerar om platsen är ansluten till stora internetknutpunkter (IXP) som DE‑CIX, AMS‑IX eller LINX, hur många operatörer som finns tillgängliga och om Peering-policyer öppna och skalbara. Det är också viktigt att Ruttdiversitet: separata glasfiberkablar och oberoende uppströmsminimerar risken för strömavbrott. För applikationer med höga trafiktoppar ser jag till att det finns 25/40/100G-uppkopplingar, överbelastningshantering och låga paketförluster. I praktiken använder jag Looking Glasses, Traceroutes och aktiva mätningar från målmarknader för att inte bara mäta bandbredden utan också Stabilitet vägarna. En bra nätverkstopologi påverkar TTFB, genomströmning och feltolerans – och därmed direkt på omsättning och driftskostnader.
Förstå latens: millisekunder och deras effekt
Fördröjning är tiden mellan förfrågan och svar – och varje millisekund påverkar användarupplevelsen och konverteringen. Om servern ligger nära besökaren minskar den fysiska avståndet och därmed också tiden för TCP-handskakningar och TLS-förhandlingar. I Europa ser jag ofta ping-värden i enmanskalsintervall, till exempel Amsterdam till Frankfurt med cirka 7 ms, medan Singapore till Frankfurt kan nå över 300 ms – vilket märks i interaktion och omsättning [1][2]. Jag satsar på edge-noder, Anycast-DNS och latensbaserad routing så att trafiken alltid får den snabbaste vägen. Om du vill fördjupa dig i grunderna hittar du praktiska tips om Ping och TTFB, som jag regelbundet utvärderar i revisioner.

Snabbare service till globala användare
För internationella målgrupper kombinerar jag CDN, multiregionala instanser och moderna protokoll. Ett CDN lagrar statiska tillgångar nära användaren, medan distribuerade applikationsnoder förkortar dynamiska svar. Med HTTP/2 och QUIC minskar jag latensspikar över långa sträckor och ökar genomströmningen vid paketförluster [1][2][10]. Jag mäter kontinuerligt med Real User Monitoring och syntetiska kontroller från kärnmarknader för att utvärdera verkliga laddningstider istället för laboratorievärden [1][18]. Den som vill fördjupa sig i inställningarna använder bästa praxis för Latensoptimering internationellt, som jag har testat i globala projekt.
Multiregional arkitektur: status, sessioner och data
Så snart jag driver flera regioner bestämmer jag var Skick . För webbappar eliminerar jag serverlokala sessioner och använder distribuerade lagringsplatser (t.ex. Redis/Key-Value) eller signerade, kortlivade tokens. Läsintensiva arbetsbelastningar drar nytta av Read-repliker per region, medan skrivoperationer konsekvent körs i en primär region – eller delas upp med hjälp av geo-sharding. Jag definierar tydligt vilka data som måste förbli regionala och undviker onödig trafik som ökar latensen och kostnaderna. Konfliktlösning, idempotens och omförsök är obligatoriska för att undvika inkonsekvenser eller dubbelbokningar under belastning.
Dataskydd och val av plats: följ GDPR på ett smart sätt
När jag behandlar uppgifter om EU-medborgare prioriterar jag Uppgiftsskydd och väljer EU-baserade leverantörer med certifierade datacenter. På så sätt säkerställer jag överföring, kryptering, orderhantering och dokumentationskrav på en hållbar nivå [3][5][13]. Utanför EU kontrollerar jag överföringsmekanismer, lagringsplatser och potentiell åtkomst från tredje part – arbetsinsatsen ökar, liksom risken [15][17]. Leverantörer med anläggningar i Tyskland får pluspoäng: korta avstånd, stark rättssäkerhet och tyskspråkig support som ger tydliga svar på revisionsfrågor. För känsliga data föredrar jag oftast tyska datacenter, eftersom de kombinerar prestanda och efterlevnad utan omvägar [3][5][13][15][17].
Dataresidens, kryptering och nyckelhantering
För strängt reglerade projekt skiljer jag på Dataresidens (där data finns) från Tillgång till data (vem som har åtkomst till den). Jag satsar konsekvent på kryptering vid lagring och överföring, med kunderna själva hanterar nycklarna (BYOK/HYOK) som förblir i önskad jurisdiktion. Jag utvärderar nyckelrotation, åtkomstloggar och HSM-stöd samt nödprocesser. På så sätt minimerar jag risker genom extern åtkomst och har bevis tillgängliga för revisioner. Viktigt: Loggar, säkerhetskopior och ögonblicksbilder räknas också som personuppgifter – därför planerar jag uttryckligen deras lagringsplats och lagringstid i platsstrategin.
Kostnadsstruktur: Lokal vs. global beräkning
Jag betraktar aldrig hosting isolerat från Budget. Låga elpriser och hyror kan sänka de månatliga avgifterna i vissa regioner, men längre latens eller extra kostnader för efterlevnad relativiserar besparingarna. Multiregionala strukturer medför ytterligare fasta kostnader för instanser, trafik, lastbalanserare, DDoS-skydd och observabilitetsverktyg. I Tyskland räknar jag ofta med paket som inkluderar hanterade tjänster, säkerhetskopiering och övervakning, vilket minskar de interna personalkostnaderna. Det avgörande är den totala kostnaden i euro per månad, inklusive säkerhetsåtgärder och supporttider – inte bara det rena serverpriset.
Undvik kostnadsfällor: Egress, interconnects och support
Jag tror det. dolda kostnader konsekvent: utgående trafik (CDN-Origin-Egress, API-Calls), interregionala avgifter, Load-Balancer-genomströmning, NAT-Gateways, offentliga IPv4-adresser, Snapshots/Backups, Log-Retention och Premium-Support. Särskilt när det gäller globala appar kan Egress överstiga serverkostnaderna. Därför kontrollerar jag volymrabatter, privata interconnects och regionala priser. För planerbara budgetar hjälper gränser, varningar och månatliga prognoser per marknad. Målet är att bygga kostnadsstrukturen så att tillväxt linjär istället för att bli dyrt – utan negativa överraskningar i slutet av månaden.
SEO-effekter: plats, laddningstid och ranking
Jag kopplar ihop Serverns placering, kodoptimering och caching för att stabilisera laddningstider och Core Web Vitals. Snabba TTFB-värden underlättar arbetet för sökrobotarna och minskar avvisningsfrekvensen – båda dessa faktorer påverkar synligheten och omsättningen [11]. Regional närhet förbättrar prestandan för den huvudsakliga målgruppen; på globala marknader sköter jag distributionen via CDN och georouting. Jag mäter kontinuerligt Largest Contentful Paint, Interaction to Next Paint och Time to First Byte för att identifiera flaskhalsar. För strategiska frågor använder jag gärna kompakta SEO-tips för serverplatsen, som hjälper mig att prioritera.

Drift och mätning: SLO, RUM och belastningstester per region
Jag formulerar tydliga SLO:er per marknad (t.ex. TTFB-percentiler, felfrekvens, tillgänglighet) och använder felbudgetar för välgrundade beslut om lanseringar. Jag kombinerar RUM-data med syntetiska tester för att återspegla verkliga användarvägar. Innan expansioner kör jag Belastningsprov från målregioner, inklusive nätverksjitter och paketförlust, så att kapacitet, autoskalning och cacheminnen dimensioneras realistiskt. Underhållsfönster lägger jag utanför lokala toppar, failover övar jag regelbundet. Dashboards måste sammanföra mätvärden, loggar och spår – bara så kan jag identifiera orsakskedjor istället för enskilda symptom.
Praxis: Stegvis tillvägagångssätt – från start till expansion
Till att börja med placerar jag arbetsbelastningar nära Huvudmålgrupp och håller arkitekturen smidig. Sedan inför jag RUM, lägger till syntetiska mätpunkter och dokumenterar TTFB-trender på kärnmarknaderna [7][18]. När de första beställningarna från utlandet kommer in lägger jag till ett CDN och utvärderar en ytterligare region beroende på svarstiderna. Jag automatiserar distributioner, skapar observabilitetsdashboards och tränar supporten för eskaleringar under peak-tider. Med denna färdplan skalar jag på ett kontrollerat sätt istället för att ändra allt på en gång.

Migrering utan driftstopp: planera, DNS och dubbelkörning
Om jag byter plats, minskar jag i god tid DNS-TTL:er, synkronisera data inkrementellt och testa Dual-Run med Mirror-Traffic. Jag definierar cutover-kriterier, hälsokontroller och en tydlig rollback-strategi. För databaser använder jag replikerade inställningar eller logisk replikering; skrivspärrar under den slutliga övergången håller jag så korta som möjligt. Efter lanseringen övervakar jag TTFB, felfrekvenser och konverterings-KPI:er noggrant och låter den gamla miljön fasas ut först efter en definierad observationsfas.
Jämförelse efter användningsområde: Var står servern?
Beroende på användningsområdet prioriterar jag Fördröjning eller dataskydd. E-handel i DACH kräver blixtsnabba reaktioner och tillförlitlig GDPR-efterlevnad, medan en renodlad amerikansk marknadsföringssida strävar efter maximal hastighet inom USA. Jag föredrar att placera interna verktyg nära platsen för att säkerställa konfidentialitet och åtkomstkontroll. Globala appar drar nytta av multiregionala strategier som fördelar belastningen och minskar svarstiderna. Följande tabell ger en kompakt översikt som jag använder som utgångspunkt i projekt.
| Scenario | Optimal plats | Prioritet Latens | Prioritet: Dataskydd | Kommentar |
|---|---|---|---|---|
| E-handel DACH | Tyskland/Europa | Högsta | Högsta | GDPR, snabba konverteringar |
| Global app | Globalt/flera regioner/CDN | Hög | Medelhög till hög | Latens- och trafikutjämning |
| Intern användning inom företaget | Lokalt vid företagets huvudkontor | Medelhög till hög | Högsta | Sekretess och kontroll |
| Marknadsföringswebbplats för USA | USA eller CDN | Hög (USA) | Låg | Snabbhet före efterlevnad |
Val av leverantör: Vad jag personligen tittar på
När det gäller leverantörer prioriterar jag NVMe-Lagring, högpresterande nätverk, tydliga SLA:er och transparenta säkerhetskontroller. Jag uppskattar informativa statusidor, begripliga RPO/RTO-värden och support på tyska med korta svarstider. För känsliga projekt kontrollerar jag certifieringar, platsgarantier och protokoll för incidenthantering [5][9][15][17]. Jag tar hänsyn till benchmark för latens och tillgänglighet i mitt beslut, tillsammans med kostnader för bandbredd och DDoS-mitigering. I slutändan är det helhetspaketet av teknik, rättssäkerhet och drift som avgör, inte bara grundpriset.
Hög tillgänglighet: zoner, RPO/RTO och failover
Jag planerar att Tolerans mot fel med tydliga mål: Hur många minuters dataförlust (RPO) och driftstopp (RTO) är acceptabla? Detta leder till arkitekturbeslut: Multi-AZ inom en region för lokal redundans, Multi-Region för platsomfattande driftstopp. DNS-baserade failover kräver korta TTL:er och tillförlitliga hälsokontroller. På databassidan undviker jag split-brain genom entydiga primärer eller verifierade kvorummodeller. Underhålls- och nödövningar (Game Days) förankrar rutiner så att failover inte förblir ett engångsexperiment.
Hållbarhet och energi: PUE, WUE och CO₂-balans
Förutom kostnaderna bedömer jag även Hållbarhet för platsen. Ett lågt PUE-värde (energieffektivitet), ansvarsfull vattenförbrukning (WUE) och en hög andel förnybar energi förbättrar den ekologiska balansen – ofta utan att prestandan försämras. Elnätets stabilitet och kylkoncept (frikylning, värmeåtervinning) minskar risken för driftstopp och driftskostnaderna på lång sikt. För företag med ESG-mål dokumenterar jag utsläpp per region och tar hänsyn till dem i beslutet om platsval, utan att försumma latenskraven i mina målmarknader.
Minska inlåsning och säkerställ portabilitet
För att förbli flexibel satsar jag på Bärbarhet: Containerbilder, öppna protokoll, infrastruktur som kod och CI/CD-pipelines som körs på flera leverantörer. Jag separerar stateful-komponenter från stateless-komponenter, håller data exporterbara och använder så neutrala tjänster som möjligt (t.ex. standarddatabaser istället för proprietära API:er) om styrningen kräver det. På så sätt kan jag byta plats, öppna upp ytterligare regioner eller byta leverantör utan att behöva spendera månader i migrationsläge.

Sammanfattning: Platsstrategi för prestanda, dataskydd och kostnader
Jag väljer Serverns placering längs mina målmarknader, mäter verklig latens och arkiverar efterlevnadsbevis på ett överskådligt sätt. Europaomfattande projekt drar nytta av tyska eller EU-datacenter, globala projekt av multiregionala och CDN. Jag utvärderar kostnaderna holistiskt, inklusive trafik, säkerhet, drift och support i euro per månad. För SEO och användarupplevelse är mätbar hastighet viktig: låg TTFB, stabila Core Web Vitals och låga avbrottsfrekvenser [11]. Den som går tillväga på detta sätt får en robust infrastruktur som reagerar snabbt, förblir rättssäker och kan skalas steg för steg över hela världen.


