 Hoppa till innehåll
Hoppa till innehåll 
En välgrundad TTFB-analys visar varför tidsstämpeln för den första byten ofta misstolkas och hur jag kombinerar mätningar med användarmätvärden på ett meningsfullt sätt. Jag förklarar specifikt var feltolkningar uppstår, hur jag samlar in konsekventa data och vilka optimeringar som Uppfattning faktiskt öka hastigheten.
Centrala punkter
- TTFB beskriver serverns start, inte den totala hastigheten.
- Sammanhang istället för ett enda värde: Läs LCP, FCP, INP.
- Plats och nätverk karakteriserar uppmätta värden.
- Caching och CDN minskar fördröjningen.
- Resurser och konfiguration har en direkt effekt.

TTFB kortfattat förklarat: Förstå mätkedjan
TTFB kartlägger tiden från begäran till den första byte som returneras och består av flera steg, som jag kallar Mätning av kedja måste beaktas. Detta inkluderar DNS-upplösning, TCP-handskakning, TLS-förhandling, serverbearbetning och sändning av den första byten. Varje avsnitt kan skapa flaskhalsar, vilket avsevärt förändrar den totala tiden. Ett verktyg visar ett enda värde här, men orsakerna ligger på flera nivåer. Jag separerar därför transportlatens, serversvar och applikationslogik för att Felkällor tydligt tilldelningsbar.
Optimera nätverkssökvägen: DNS till TLS
Jag börjar med namnet: DNS-resolvers, CNAME-kedjor och TTL påverkar hur snabbt en värd löses. För många omdirigeringar eller en resolver med hög latens lägger till märkbara millisekunder. Sedan är det anslutningen som räknas: Jag minskar antalet rundresor med keep-alive, TCP fast-open-liknande strategier och snabb portdelning. Med TLS kontrollerar jag certifikatkedjan, OCSP-häftning och återupptagande av session. En kort certifikatkedja och aktiverad häftning sparar handskakningar, medan moderna protokoll som HTTP/2 och HTTP/3 multiplexerar flera förfrågningar effektivt över en anslutning.
Jag noterar också vägen: IPv6 kan ha fördelar i väl sammankopplade nätverk, men svaga peering-vägar ökar jitter och paketförlust. I mobilnät spelar varje tur- och returresa en större roll, vilket är anledningen till att jag föredrar 0-RTT-mekanismer, ALPN och snabba TLS-versioner. Det viktiga för mig är att transportoptimeringen inte bara påskyndar TTFB, utan också stabiliserar variansen. Ett stabilt mätintervall gör mina optimeringar mer reproducerbara och besluten mer tillförlitliga.
De 3 vanligaste missuppfattningarna
1) TTFB står för den totala hastigheten
En låg TTFB säger lite om rendering, bildleverans eller JavaScript-körning, dvs. om vad människor kan göra direkt. Se. En sida kan skicka en första byte tidigt, men senare misslyckas på grund av det största innehållet (LCP). Jag ser ofta snabba första byte med trög interaktivitet. Den upplevda hastigheten uppstår först när det relevanta innehållet visas och reagerar. Det är därför en TTFB-fixerad vy kopplar ihop Verklighet av användning från det uppmätta värdet.
2) Låg TTFB = bra UX och SEO
Jag kan artificiellt driva TTFB, till exempel genom att använda tidiga rubriker, utan att tillhandahålla användbart innehåll, vilket är vad den verkliga Nyttovärde ökar inte. Sökmotorer och människor värdesätter synlighet och användbarhet mer än den första byten. Mätvärden som LCP och INP återspeglar bättre hur sidan känns. Ett rent TTFB-fokus ignorerar de kritiska stegen för rendering och interaktivitet. Jag mäter därför dessutom så att beslut kan baseras på Uppgifter med relevans.
3) Alla TTFB-värden är jämförbara
Mätpunkt, peering, belastning och avstånd förvränger jämförelser som jag knappast skulle kunna göra utan samma ramvillkor. Pris kan. En testserver i USA mäter på ett annat sätt än en i Frankfurt. Belastningsfluktuationer mellan morgon och kväll förändrar också resultaten märkbart. Därför använder jag flera körningar, på minst två platser och vid olika tidpunkter. Endast detta intervall ger en solid Klassificering av värdet.

Syntetisk vs. RUM: två perspektiv på TTFB
Jag kombinerar syntetiska tester med övervakning av verkliga användare (RUM) eftersom båda ger svar på olika frågor. Syntetiska tester ger mig kontrollerade riktmärken med tydliga ramar, perfekt för regressionstester och jämförelser. RUM speglar verkligheten i olika enheter, nätverk och regioner och visar hur TTFB fluktuerar i fält. Jag arbetar med percentiler i stället för genomsnitt för att identifiera avvikande värden och segmentera efter enhet (mobil/dator), land och nätverkskvalitet. Först när mönster hittas i båda världarna bedömer jag orsaker och åtgärder som robusta.
Vad är det egentligen som påverkar TTFB?
Valet av hostingmiljö har en stor inverkan på latens, IO och beräkningstid, vilket direkt återspeglas i TTFB visar. Överbokade system svarar långsammare, medan NVMe SSD-enheter, moderna stackar och bra peering-vägar ger korta svarstider. Serverkonfigurationen spelar också roll: olämpliga PHP-inställningar, svag opcache eller för lite RAM-minne leder till förseningar. När det gäller databaser märker jag av långsamma förfrågningar i varje förfrågan, särskilt med oindexerade tabeller. Ett CDN minskar avståndet och sänker Fördröjning för statiskt och cachat innehåll.
PHP-FPM och körtidsoptimering i praktiken
Jag kontrollerar processhanteraren: för få PHP-arbetare genererar köer, för många flyttar cacher från RAM. Jag balanserar inställningar som max_children, pm (dynamisk/ondemand) och förfrågningsgränser baserat på verkliga belastningsprofiler. Jag håller Opcache varm och stabil, minskar autoloaderns overhead (optimerade classmaps), aktiverar realpath cache och tar bort debug-tillägg i produktion. Jag flyttar dyra initialiseringar till bootstraps och cachar resultaten i objektcachen. Detta minskar tiden mellan socketacceptans och den första byten utan att behöva offra funktionalitet.
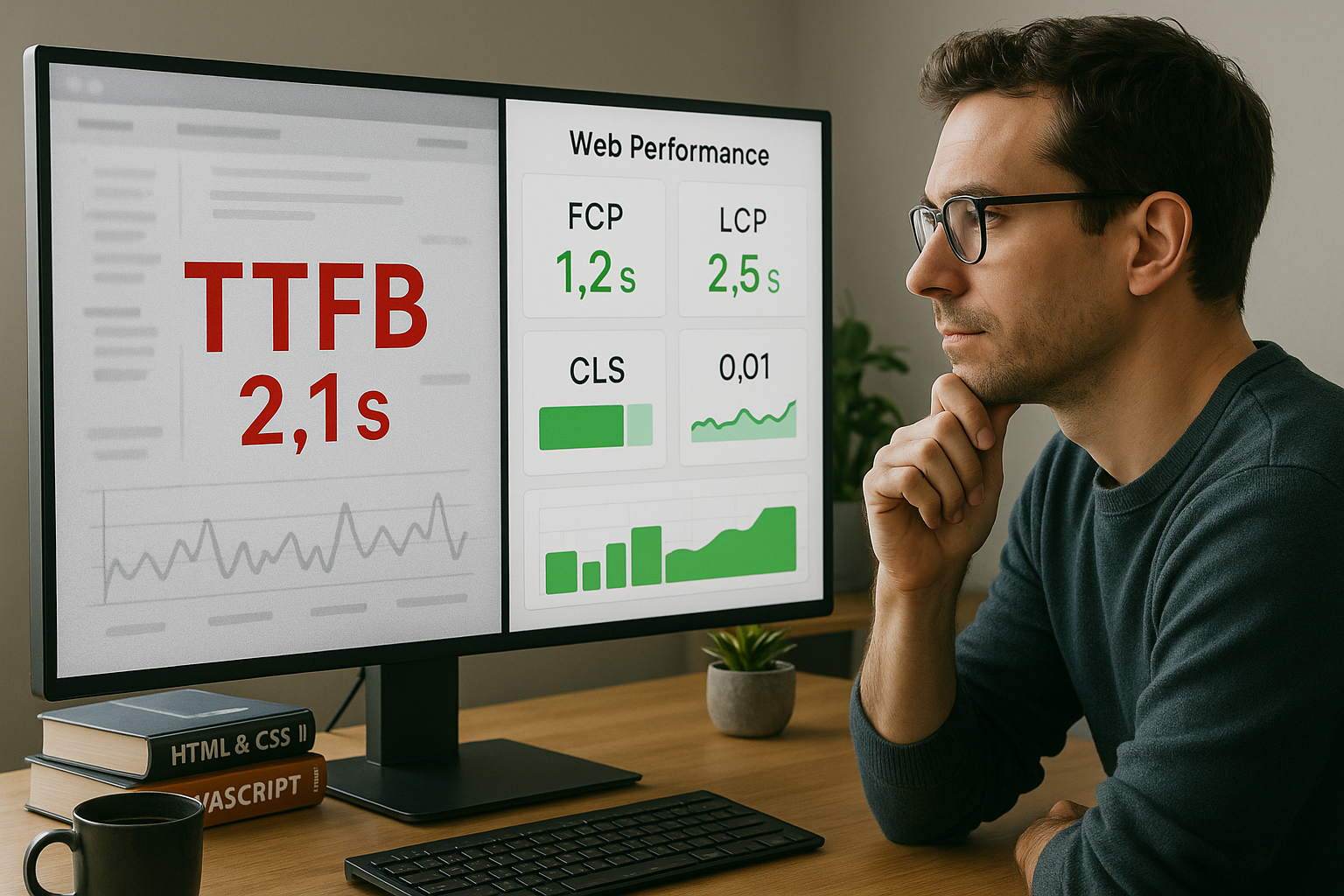
Hur man mäter TTFB korrekt
Jag testar flera gånger, vid olika tidpunkter, på minst två platser och bildar medianer eller percentiler för en tillförlitlig Grundläggande. Jag kontrollerar också om cacheminnet är varmt eftersom den första åtkomsten ofta tar längre tid än alla efterföljande åtkomster. Jag korrelerar TTFB med LCP, FCP, INP och CLS så att värdet blir begripligt i den totala bilden. För att göra detta använder jag dedikerade körningar för HTML, kritiska resurser och innehåll från tredje part. En bra utgångspunkt är utvärderingen kring Core Web Vitalseftersom de är Uppfattning av användarna.
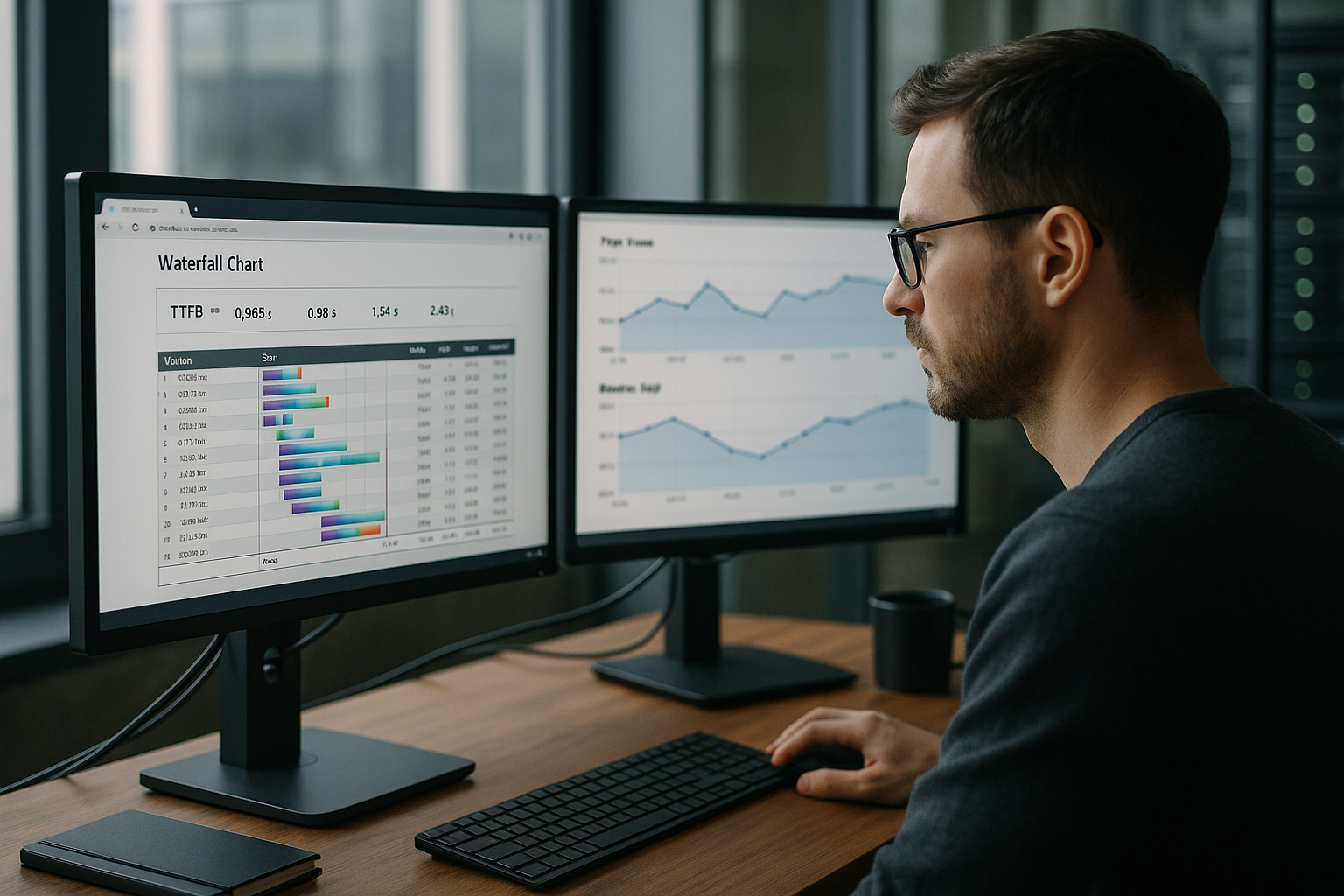
Server timing och spårbarhet
Jag skickar också servertidsrubriker för att göra tidsandelarna transparenta: t.ex. dns, connect, tls, app, db, cache. Jag lägger till samma markörer i loggar och lägger till spårnings-ID:n i förfrågningar så att jag kan spåra enskilda körningar via CDN, Edge och Origin. Denna granularitet förhindrar gissningsspel: I stället för "TTFB är hög" kan jag se om databasen behöver 180 ms eller om Origin har fastnat i en kö i 120 ms. Med percentiler per rutt (t.ex. produktdetaljer vs. sökning) definierar jag tydliga budgetar och kan stoppa regressioner i CI på ett tidigt stadium.
Bästa praxis: Snabbare första byte
Jag använder cachelagring på serversidan för HTML så att servern kan leverera färdiga svar och CPU behöver inte räkna om varje förfrågan. Ett globalt CDN för innehållet närmare användarna och minskar avstånd, DNS-tid och routing. Jag håller PHP, databas och webbserver uppdaterade, aktiverar Opcache och använder HTTP/2 eller HTTP/3 för bättre anslutningsutnyttjande. Jag flyttar dyra externa API-anrop asynkront eller cachar dem så att den första byten inte väntar i onödan. Regelbunden profilering täcker långsamma förfrågningar och Insticksprogram som jag desarmerar eller ersätter.
Cachelagringsstrategier i detalj: TTL, Vary och Microcaching
Jag gör en strikt åtskillnad mellan dynamisk och cache. HTML får korta TTL:er och mikrocaching (t.ex. 5-30 s) för belastningstoppar, medan API-svar med tydliga cache control-rubriker och ETags kan leva längre. Jag använder Vary selektivt: Endast där språk, cookies eller användaragent verkligen genererar olika innehåll. Vary-nycklar som är för breda förstör träffprocenten. Med stale-while-revalidate levererar jag omedelbart och uppdaterar i bakgrunden; stale-if-error håller sidan tillgänglig om backend hänger sig. Viktigt: Undvik cookies på rotdomänen om de oavsiktligt förhindrar cachelagring.
För ändringar planerar jag ren cache-busting via versionsparametrar eller innehållshashar. Jag begränsar HTML-invalideringar till berörda rutter istället för att utlösa globala rensningar. För CDN:er använder jag regionala uppvärmningar och en ursprungssköld för att skydda ursprungsservern. Detta håller TTFB stabil även under trafiktoppar utan att behöva överdimensionera kapaciteten.
TTFB vs. användarupplevelse: viktiga mätvärden
Jag betygsätter LCP för Largest Visible Content, FCP för First Content och INP för Input Response eftersom dessa mätvärden är erfarenheten märkbar göra. En sida kan ha en måttlig TTFB och ändå verka snabb om viktig rendering sker tidigt. Omvänt är en liten TTFB till liten nytta om blockerande skript fördröjer visningen. Jag använder Analys av fyrtornför att kontrollera resurssekvensen, renderingsvägen och prioriteringarna. Detta gör att jag kan se vilken optimering som verkligen Hjälper till.

Ställ in renderingsprioriteringar korrekt
Jag ser till att kritiska resurser kommer före allt annat: Kritisk CSS inline, teckensnitt med font-display och förnuftig förladdning/prioritering, bilder i above-the-fold med lämplig fetchprioritet. Jag laddar JavaScript så sent eller asynkront som möjligt och rensar upp i huvudtrådbelastningen så att webbläsaren kan måla snabbt. Jag använder tidiga tips för att utlösa förladdningar före det slutliga svaret. Resultat: Även om TTFB inte är perfekt känns sidan mycket snabbare tack vare tidig synlighet och snabb respons.
Undvik mätfel: typiska stötestenar
En varm cache förvränger jämförelserna, vilket är anledningen till att jag skiljer mellan kalla och varma förfrågningar. separat. Ett CDN kan också ha föråldrade eller icke-replikerade kanter, vilket förlänger den första hämtningen. Jag kontrollerar serverutnyttjandet parallellt så att säkerhetskopior eller cron-jobb inte påverkar mätningen. På klientsidan är jag uppmärksam på webbläsarens cache och anslutningskvaliteten för att minimera lokala effekter. Även DNS-resolvers ändrar latensen, så jag håller testmiljön som konstant.
Överväg CDN, WAF och säkerhetslager
Intermediära system som WAF, botfilter och DDoS-skydd kan öka TTFB utan att ursprunget är felaktigt. Jag kontrollerar om TLS-terminering sker vid kanten, om en sköld är aktiv och hur regler utlöser komplexa kontroller. Hastighetsgränser, geofencing eller JavaScript-utmaningar är ofta användbara, men bör inte flytta medianvärdena obemärkt. Jag mäter därför både edge hit och origin miss separat och har undantagsregler för syntetiska tester redo att skilja verkliga problem från skyddsmekanismer.
Värdskapsbeslut som lönar sig
Snabba NVMe SSD-enheter, tillräckligt med RAM-minne och moderna processorer ger backend tillräckligt med kraft. Effektså att svaren börjar snabbt. Jag skalar PHP-arbetare för att matcha trafiken så att förfrågningar inte hamnar i kö. Effekten av denna flaskhals blir ofta uppenbar först under belastning, vilket är anledningen till att jag planerar kapaciteten realistiskt. För praktisk planering, guiden till Planera PHP-medarbetare på rätt sätt. Närheten till målmarknaden och bra peering gör också att Fördröjning låg.

Processer för driftsättning och kvalitet
Jag behandlar prestanda som en kvalitetsegenskap i leveransen: Jag definierar budgetar för TTFB, LCP och INP i CI/CD-pipelinen och blockerar releaser med tydliga regressioner. Kanariefågelversioner och funktionsflaggor hjälper mig att dosera risker och mäta dem steg för steg. Innan större förändringar kör jag belastningstester för att identifiera gränser för arbetare, anslutningsgränser och databaslås. Med återkommande "smoke tests" på representativa rutter upptäcker jag försämringar omedelbart - inte bara när det är som värst. Detta gör att jag kan bibehålla den uppmätta förbättringen på lång sikt.
Praktisk tabell: Mätningsscenarier och åtgärder
Följande översikt kategoriserar typiska situationer och kopplar den observerade TTFB till ytterligare nyckeltal och konkreta Steg. Jag använder dem för att snabbare ringa in orsaker och för att tydligare härleda åtgärder. Det är fortfarande viktigt att kontrollera värdena flera gånger och att läsa sammanhangsmätningar. På så sätt undviker jag att fatta beslut som bara påverkar symptomen och inte förbättrar uppfattningen. Tabellen hjälper mig att planera och analysera tester. Prioriteringar att ställa in.
| Scenario | Observation (TTFB) | Kompletterande mätvärden | Möjlig orsak | Konkret åtgärd |
|---|---|---|---|---|
| Första samtalet på morgonen | Hög | LCP ok, FCP ok | Kall cache, DB-väckning | Förvärm servercache, underhåll DB-anslutningar |
| Trafikens topp | Ökar med stormsteg | INP försämrades | För få PHP-arbetare | Öka antalet anställda, outsourca långa arbetsuppgifter |
| Global tillgång USA | Betydligt högre | LCP fluktuerar | Avstånd, peering | Aktivera CDN, använd edge cache |
| Många produktsidor | Ostadig | FCP bra, LCP dåligt | Stora bilder, ingen tidig antydan | Optimera bilder, prioritera förinläsning |
| API:er från tredje part | Förändringsbar | INP ok | Väntetid för API | Cache-svar, bearbeta asynkront |
| Uppdatering av CMS backend | Högre än tidigare | CLS oförändrad | Ny plugin bromsar utvecklingen | Profilering, ersättning eller patchning av plug-ins |
Sammanfattning: Kategorisera TTFB korrekt i sitt sammanhang
Ett enda TTFB-värde förklarar sällan hur en sida känns, så jag länkar den till LCP, FCP, INP och real Användare. Jag mäter flera gånger, synkroniserar platser och kontrollerar belastningen så att jag får konsekventa resultat. För snabba lanseringar använder jag cachelagring, CDN, uppdaterad programvara och smala frågor. Samtidigt prioriterar jag rendering av synligt innehåll eftersom tidig synlighet tydligt förbättrar uppfattningen. Så här leder min TTFB-analys till beslut som optimerar Erfarenhet av besökarna.


