
Aktiv felsökningsloggning tvingar WordPress att utföra ytterligare skrivoperationer varje gång den anropas, vilket ökar TTFB och serverbelastningen ökar märkbart. Så snart hundratals notiser, varningar och avregistrerade notiser landar per begäran ökar serverbelastningen. felsök.logg och sidan reagerar långsamt.
Centrala punkter
- Skrivbelastning grows: Varje fel hamnar i debug.log och genererar I/O-överhead.
- E_ALL aktiv: Notiser och avskrivna notiser blåser upp loggningen.
- Produktiv riskabelt: hastigheten sjunker, känslig information hamnar i loggfilen.
- Caching begränsad: Overhead uppstår per förfrågan, cache är till liten hjälp.
- Rotation nödvändigt: Stora loggar blir långsammare och tar upp minne.
Varför aktiv felsökningsloggning gör WordPress långsammare
Varje begäran utlöser en wordpress felsökningsloggning tre uppgifter: Registrering av fel, formatering av meddelanden och skrivning av dem till hårddisken. Denna kedja tar tid eftersom PHP först genererar innehållet i meddelandet och sedan synkroniserar det i felsök.logg måste lagras. Speciellt med många plugins ackumuleras meddelanden, vilket innebär att varje sida plötsligt orsakar hundratals skrivoperationer. Filen växer snabbt med tiotals megabyte per dag, vilket saktar ner filåtkomsten. Jag ser sedan hur TTFB och den totala laddningstiden ökar, trots att inget har ändrats i temat eller cacheminnet.

Förståelse av felnivåer: E_ALL, meddelanden och föråldrade
Med WP_DEBUG till true höjer WordPress felrapporteringen till E_ALL, vilket innebär att även harmlösa meddelanden hamnar i loggen. Exakt dessa meddelanden och föråldrade varningar låter harmlösa, men ökar loggfrekvensen enormt. Varje meddelande utlöser en skrivåtkomst och kostar latenstid. Om du vill veta vilka felnivåer som orsakar hur mycket belastning kan du hitta bakgrundsinformation på PHP-felnivåer och prestanda. Jag sänker därför tillfälligt volymen, filtrerar bort onödigt brus och förkortar därmed Intensitet i skrivandet på begäran.
Filstorlek, TTFB och serverbelastning: dominoeffekten
Så snart som möjligt felsök.logg når flera hundra megabyte minskar filsystemets smidighet. PHP kontrollerar, öppnar, skriver och stänger filen non-stop, vilket ökar TTFB och backend-svarstiden. Dessutom formaterar CPU:n meddelanden, vilket är ett problem med hög trafik. I/O blir en flaskhals, eftersom många små synkroniserade skrivningar kan överbelasta Fördröjning dominerar. På delad hosting driver detta upp belastningsgenomsnittet tills till och med backend verkar trögt.
Typiska utlösande faktorer: plugins, WooCommerce och hög trafik
Butiker och tidningar med många anknytningar producerar snabbt ett stort antal Meddelanden. En WooCommerce-installation med 20 tillägg kan utlösa tiotusentals poster varje dag, vilket blåser upp loggfilen på kort tid. Om trafiken ökar, ökar flödet av meddelanden i samma takt. Varje sidförfrågan skrivs igen, även om frontend-utmatningen är cachad, eftersom loggning sker före cache-utmatningen. I sådana fall ser jag laddningstidstoppar och kollapsande cron-jobb på grund av Disk-I/O ständigt blockerad.
Produktiva miljöer: Förlorad hastighet och informationsläckage
På live-system klämmer jag Felsökning så snart felanalysen är avslutad. Debuggloggar avslöjar filsökvägar, frågedetaljer och därmed potentiellt känslig information. Dessutom sjunker svarstiden märkbart eftersom varje riktig besökare utlöser logglinjer igen. Om du vill gå grundligt tillväga bör du kontrollera alternativ och riktlinjer för Felsökningsläge i produktion. Jag håller mig till korta analysfönster, raderar gamla loggar och säkrar filen mot obehörig åtkomst. Tillgång.
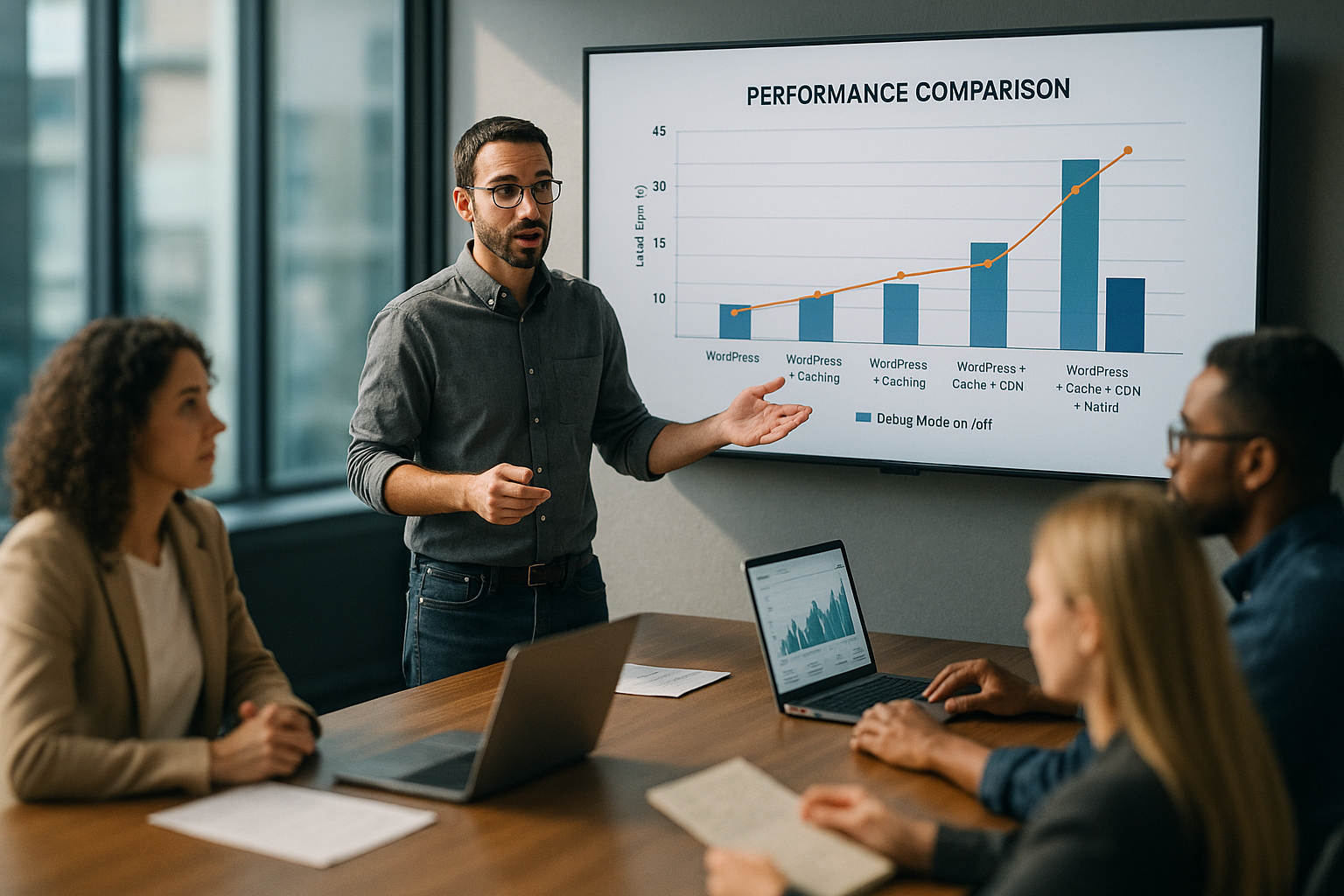
Jämförelse av uppmätta värden: utan vs. med debug-loggning
Avmattningen är lätt att mäta eftersom TTFB och serverbelastning tydligt skiftar under felsökningsloggning. Jag mäter ofta korta svarstider utan aktiv loggning, som ökar märkbart under loggning. Detta gäller inte bara frontend-vyer, utan även adminåtgärder, AJAX-anrop och REST-slutpunkter. Även om innehållet kommer statiskt från cacheminnet saktar den extra loggningsomkostnaden ner begäran. I följande tabell sammanfattar jag typiska Tendenser tillsammans.
| Prestationsfaktor | Utan felsökning | Med felsökningsloggning |
|---|---|---|
| TTFB (ms) | ≈ 200 | ≈ 1500+ |
| Serverbelastning | Låg | Hög |
| Loggstorlek (per dag) | 0 MB | 50-500 MB |
Dessa intervall återspeglar vanliga observationer och visar hur wp långsam felsökning är skapad. Jag analyserar APM-spår, sidtider och serverstatistik tillsammans. Jag tittar också på filsystemets profilering för att visualisera skrivamplituder. Mönstret är tydligt: fler meddelanden leder till en större andel I/O i begäran. Sammantaget ökar latensen, även om PHP-koden i sig förmodligen är lika kvarstår.

Varför cachelagring är till liten hjälp mot overhead
Sid- och objektcache minskar PHP-arbetet, men loggning sker både före och efter. Varje meddelande genererar en ny Skriv-operation, oavsett om HTML-svaret kommer från cacheminnet eller inte. Därför förblir TTFB och backend-svaret ökat trots cacheminnet. Jag använder ändå cache, men förväntar mig inga mirakel från den så länge felsökningsloggningen är aktiv. Det som räknas för verklig lättnad är att stänga av källan, inte att maskera den med Cache.
Säker aktivering och ännu snabbare avstängning
Jag aktiverar loggning specifikt, arbetar på ett fokuserat sätt och avaktiverar den omedelbart efter analysen. Det är så här jag ställer in det i wp-config.php och håller utdata borta från frontend:
define('WP_DEBUG', true);
define('WP_DEBUG_LOG', true);
define('WP_DEBUG_DISPLAY', false);
@ini_set('display_errors', 0);
Jag kontrollerar sedan de relevanta sidvisningarna, isolerar källan och ställer in WP_DEBUG till false igen. Slutligen tar jag bort en uppsvälld debug.log så att servern inte längre jonglerar med döda data. Denna disciplin sparar tid och bevarar Prestanda i det dagliga livet.

Loggrotation och underhåll: små steg, stor effekt
Odling utan rotation felsök.logg okontrollerad tills skrivåtkomsterna går överstyr. Jag ställer därför in daglig komprimering och raderar gamla filer efter en kort tid. Detta enkla steg minskar I/O avsevärt eftersom den aktiva loggfilen förblir liten. Jag använder också regex för att filtrera bort typiskt notisbrus för att dämpa flödet. Om du vill gå djupare kan du också kontrollera PHP-felnivåer och felhanterare för Granularitet.
Läs upp fel på ett säkert sätt: Skydd från nyfikna ögon
Debuggloggar får inte vara tillgängliga för allmänheten, annars hamnar sökvägar och nycklar i fel händer. Jag låser filen i Webroot konsekvent, t.ex. via .htaccess:
Order Tillåt,Neka
Neka från alla
Jag ställer in motsvarande regler på NGINX så att ingen direkt nedladdning är möjlig. Jag ställer också in restriktiva filbehörigheter för att begränsa åtkomsten till det absoluta minimum. Säkerhet går före bekvämlighet eftersom loggar ofta avslöjar mer än förväntat. Korta kontrollintervall och prydliga loggar minimerar attackytan liten.

Hitta källan till felet: Verktyg och tillvägagångssätt
För att begränsa det använder jag mig av gradvis avaktivering av plugins och en fokuserad Profilering. Under tiden analyserar jag logglinjerna med tail och filter för att snabbt identifiera de mest högljudda meddelandena. För mer djupgående analyser använder jag Query Monitor Praxis, för att spåra krokar, förfrågningar och HTTP-anrop. Samtidigt mäter jag TTFB, PHP-tid och databasvaraktighet så att jag tydligt kan identifiera flaskhalsen. Först när källan har fastställts återaktiverar jag plugin-programmet eller justerar koden så att ingen Buller kvarstår.
Välj hostingresurser på ett klokt sätt
Felsökningsloggning är särskilt märkbar på långsam lagringshårdvara, eftersom varje Skriv-drift tar längre tid. Jag förlitar mig därför på snabb I/O, tillräckliga CPU-reserver och lämpliga gränser för processer. Detta inkluderar en bra PHP-arbetarkonfiguration och en ren separation av staging och live. Om du använder staging kan du testa uppdateringar utan belastningstoppar och kan aktivera hög loggning med gott samvete. Mer utrymme hjälper, men jag löser orsaken så att WordPress kan köras utan Bromsar kör.
Finjustering av WP- och PHP-inställningar
Jag använder ytterligare justeringsskruvar i wp-config.php för att exakt styra volymen och minimera biverkningarna:
// Böj sökvägen: Logga utanför webroot
define('WP_DEBUG_LOG', '/var/log/wp/site-debug.log');
// Öka volymen endast tillfälligt, stäng sedan av igen
@ini_set('log_errors', 1);
@ini_set('error_reporting', E_ALL & ~E_NOTICE & ~E_DEPRECATED & ~E_STRICT);
Jag använder en dedikerad sökväg för att lagra loggfilen utanför webroot och separera den rent från distributioner. Om fel_rapportering Jag dämpar medvetet bruset när jag i första hand letar efter hårda fel. Så snart jag byter till staging använder jag E_NOTICE och E_DEPRECATED igen för att arbeta mig igenom gamla problem.
SAVEQUERIES, SCRIPT_DEBUG och dolda bromsar
Vissa brytare utvecklar endast en stark bromseffekt när de kombineras. SÄKRAQUERIER loggar varje databasförfrågan i PHP-minnesstrukturer och ökar CPU- och RAM-belastningen. SCRIPT_DEBUG tvingar WordPress att ladda icke-minifierade tillgångar; bra för analys, men sämre för laddningstiden. Jag aktiverar dessa switchar endast under strikt begränsade tidsfönster och endast i staging-miljöer. Jag definierar också WP_MILJÖ_TYP (t.ex. “staging” eller “production”) för att villkorligt styra beteendet i koden och undvika felkonfigurationer.
Serverfaktorer: PHP-FPM, lagring och fillås
På servernivå bestämmer jag mycket om den märkbara effekten: PHP FPM-pooler med för få arbetare överbelastar förfrågningar, medan överdimensionerade pooler ökar I/O-konkurrensen. Jag ställer in separata pooler per webbplats eller kritisk rutt (t.ex. /wp-admin/ och /wp-cron.php) för att minimera kollisioner mellan loggning och backend-arbete. På lagringssidan presterar lokala NVMe-volymer betydligt bättre än långsammare nätverksfilsystem, där fillås och latens multiplicerar effekten av loggning. Med PHP-FPM slowlog känner jag igen flaskhalsar som orsakas av frekventa error_log()-samtal eller låsa väntetider.
Avlastning: Syslog, Journald och fjärrleverans
Om jag inte kan stänga av loggning helt, avlastar jag hårddisken genom offloading. PHP fel_logg kan skicka meddelanden till Syslog, som sedan buffras och bearbetas asynkront. Detta minskar skrivamplituden för lokala filer, men flyttar ansträngningen till loggsubsystemet. Det är viktigt att begränsa hastigheten, annars ersätter jag bara flaskhalsen. För korta tester föredrar jag lokala filer (bättre kontroll), för längre analyser korta avlastningsfaser med en tydlig avstängningsgräns.
Riktat felsökningsfönster via MU plug-in
Jag begränsar felsökningen till mig själv eller ett tidsfönster för att undvika buller från produktiva användare. Ett litet MU-plugin slår på felsökning endast för administratörer av en specifik IP eller cookie:
<?php
// wp-content/mu-plugins/targeted-debug.php
if (php_sapi_name() !== 'cli') {
$allow = isset($_COOKIE['dbg']) || ($_SERVER['REMOTE_ADDR'] ?? '') === '203.0.113.10';
if ($allow) {
define('WP_DEBUG', true);
define('WP_DEBUG_LOG', '/var/log/wp/site-debug.log');
define('WP_DEBUG_DISPLAY', false);
@ini_set('log_errors', 1);
@ini_set('error_reporting', E_ALL);
}
}
På så sätt loggar jag bara mina egna reproduktioner och skonar resten av besökarna. När jag är klar tar jag bort plugin-programmet eller raderar cookien.
Rotation i praktiken: robust och säker
Jag roterar loggar med kompakta regler och är uppmärksam på öppna filbeskrivningar. kopiera avkorta är användbart om processen inte öppnar filen på nytt; annars använder jag skapa och signalerar till PHP-FPM så att nya poster flödar in i den nya filen. Exempel på detta:
/var/log/wp/site-debug.log {
dagligen
rotera 7
komprimera
missingok
notifempty
skapa 0640 www-data www-data
postrotera
/usr/sbin/service php8.2-fpm reload >/dev/null 2>&1 || true
Slutar skript
}
Dessutom håller jag den aktiva loggfilen liten (<10-50 MB) eftersom korta sökningar, greps och tails körs märkbart snabbare och genererar färre cachemiss-kaskader i filsystemet.
WooCommerce och plugin-specifik loggning
Vissa plugins har sina egna loggar (t.ex. WooCommerce). Där ställer jag in tröskelvärdena på “error” eller “critical” och avaktiverar “debug”-kanalerna i produktionen. Detta minskar dubbel loggning (WordPress och plugin) och skyddar I/O. Om jag misstänker ett fel i insticksprogrammet ökar jag nivån specifikt och återställer den sedan omedelbart.
Multisite, staging och containrar
I installationer med flera webbplatser samlar WordPress meddelanden i en gemensam felsök.logg. Jag distribuerar dem avsiktligt per webbplats (separat sökväg per blogg-ID) så att enskilda “bullriga” webbplatser inte saktar ner de andra. I containermiljöer skriver jag tillfälligt till /tmp (snabbt), arkivera specifikt och kassera innehåll under ombyggnaden. Viktigt: Även om filsystemet är snabbt kvarstår CPU-belastningen för formateringen - så jag fortsätter att eliminera orsaken.
Teststrategi: ren mätning i stället för gissningar
Jag jämför identiska förfrågningar med och utan loggning under stabiliserade förhållanden: samma cacheuppvärmning, samma PHP FPM-arbetare, identisk belastning. Sedan mäter jag TTFB, PHP-tid, DB-tid och I/O-väntetid. Dessutom kör jag belastningstester i 1-5 minuter, eftersom effekten av stora loggar och låskonflikter bara blir synlig under kontinuerlig skrivning. Först när mätningen är konsekvent härleder jag åtgärder.
Dataskydd och lagring
Loggar kan snabbt innehålla personuppgifter (t.ex. sökparametrar, e-postadresser i förfrågningar). Jag håller lagringen till ett minimum, anonymiserar där det är möjligt och raderar konsekvent efter slutförandet. För team dokumenterar jag start- och sluttiden för felsökningsfönstret så att ingen glömmer att ta bort loggningen igen. På så sätt minimerar jag risker, lagringsbehov och omkostnader.
Kortfattat sammanfattat
Aktiv Felsökningsloggning saktar ner WordPress eftersom varje begäran utlöser skrivoperationer och formatering som ökar TTFB och serverbelastning. Jag aktiverar loggning specifikt, filtrerar meddelanden, roterar loggfilen och blockerar debug.log från åtkomst. I produktionsmiljöer är loggning fortfarande undantaget, medan staging är regeln. Cachelagring lindrar symptomen, men eliminerar inte overhead per begäran. Om du konsekvent eliminerar orsakerna säkerställer du hastighet, sparar resurser och håller prestanda wordpress permanent hög.


