
Aktiv fejlfindingslogning tvinger WordPress til at udføre yderligere skriveoperationer, hver gang den kaldes, hvilket øger TTFB og serverbelastningen stiger mærkbart. Så snart der lander hundredvis af meddelelser, advarsler og forældede meddelelser pr. anmodning, vokser serverbelastningen. debug.log og siden reagerer langsomt.
Centrale punkter
- Skriv belastning Grows: Hver fejl ender i debug.log og genererer I/O-overhead.
- E_ALL aktiv: Meddelelser og udgåede noter øger logningen.
- Produktiv risiko: hastigheden falder, følsomme oplysninger ender i logfilen.
- Caching begrænset: Overhead opstår pr. anmodning, cache er ikke til megen hjælp.
- Rotation nødvendigt: Store logfiler er langsomme og optager hukommelse.
Hvorfor aktiv debug-logning gør WordPress langsommere
Hver anmodning udløser en wordpress debug-logning tre opgaver: Registrere fejl, formatere beskeder og skrive dem til harddisken. Denne kæde tager tid, fordi PHP først genererer indholdet af beskeden og derefter synkroniserer det i debug.log skal gemmes. Især med mange plugins ophobes meddelelser, hvilket betyder, at hver side pludselig forårsager hundredvis af skriveoperationer. Filen vokser hurtigt med titusindvis af megabyte om dagen, hvilket bremser filadgangen. Jeg ser så, hvordan TTFB og den samlede indlæsningstid stiger, selv om der ikke er ændret noget i temaet eller cachen.

Forståelse af fejlniveauer: E_ALL, Notices og Deprecated
Med WP_DEBUG til true, hæver WordPress fejlrapporteringen til E_ALL, hvilket betyder, at selv harmløse meddelelser ender i loggen. Netop disse meddelelser og forældede advarsler lyder harmløse, men øger logfrekvensen enormt. Hver besked udløser en skriveadgang og koster latency. Hvis du vil vide, hvilke fejlniveauer der forårsager hvor meget belastning, kan du finde baggrundsinformation på PHP-fejlniveauer og ydeevne. Jeg reducerer derfor midlertidigt lydstyrken, filtrerer unødvendig støj fra og forkorter dermed tiden. Skrivningens intensitet efter anmodning.
Filstørrelse, TTFB og serverbelastning: Dominoeffekten
Så snart debug.log når op på flere hundrede megabyte, falder filsystemets smidighed. PHP tjekker, åbner, skriver og lukker filen non-stop, hvilket øger TTFB- og backend-svartiden. Desuden formaterer CPU'en beskeder, hvilket er et problem ved høj trafik. I/O bliver en flaskehals, fordi mange små synkroniseringsskrivninger kan overbelaste Forsinkelse dominerer. På delt hosting driver det den gennemsnitlige belastning op, indtil selv backend virker træg.
Typiske udløsere: plugins, WooCommerce og høj trafik
Butikker og magasiner med mange filialer producerer hurtigt et stort antal Meddelelser. En WooCommerce-opsætning med 20 udvidelser kan udløse titusindvis af poster hver dag, hvilket får logfilen til at svulme op i løbet af kort tid. Hvis trafikken stiger, øges mængden af beskeder i samme takt. Hver sideanmodning skrives igen, selv hvis frontend-outputtet er cachelagret, da logning finder sted før cache-outputtet. I sådanne tilfælde ser jeg toppe i indlæsningstiden og kollapsende cron-jobs, fordi Disk-I/O konstant blokeret.
Produktive miljøer: Tab af hastighed og informationslækage
På live-systemer klemmer jeg Fejlfinding så snart fejlanalysen er afsluttet. Debug-logfiler afslører filstier, forespørgselsdetaljer og dermed potentielt følsomme oplysninger. Desuden falder svartiden mærkbart, fordi hver rigtig besøgende udløser loglinjer igen. Hvis du vil gå grundigt til værks, kan du tjekke alternativer og retningslinjer for Fejlfindingstilstand i produktionen. Jeg holder mig til korte analysevinduer, sletter gamle logfiler og sikrer filen mod uautoriseret adgang. Adgang.
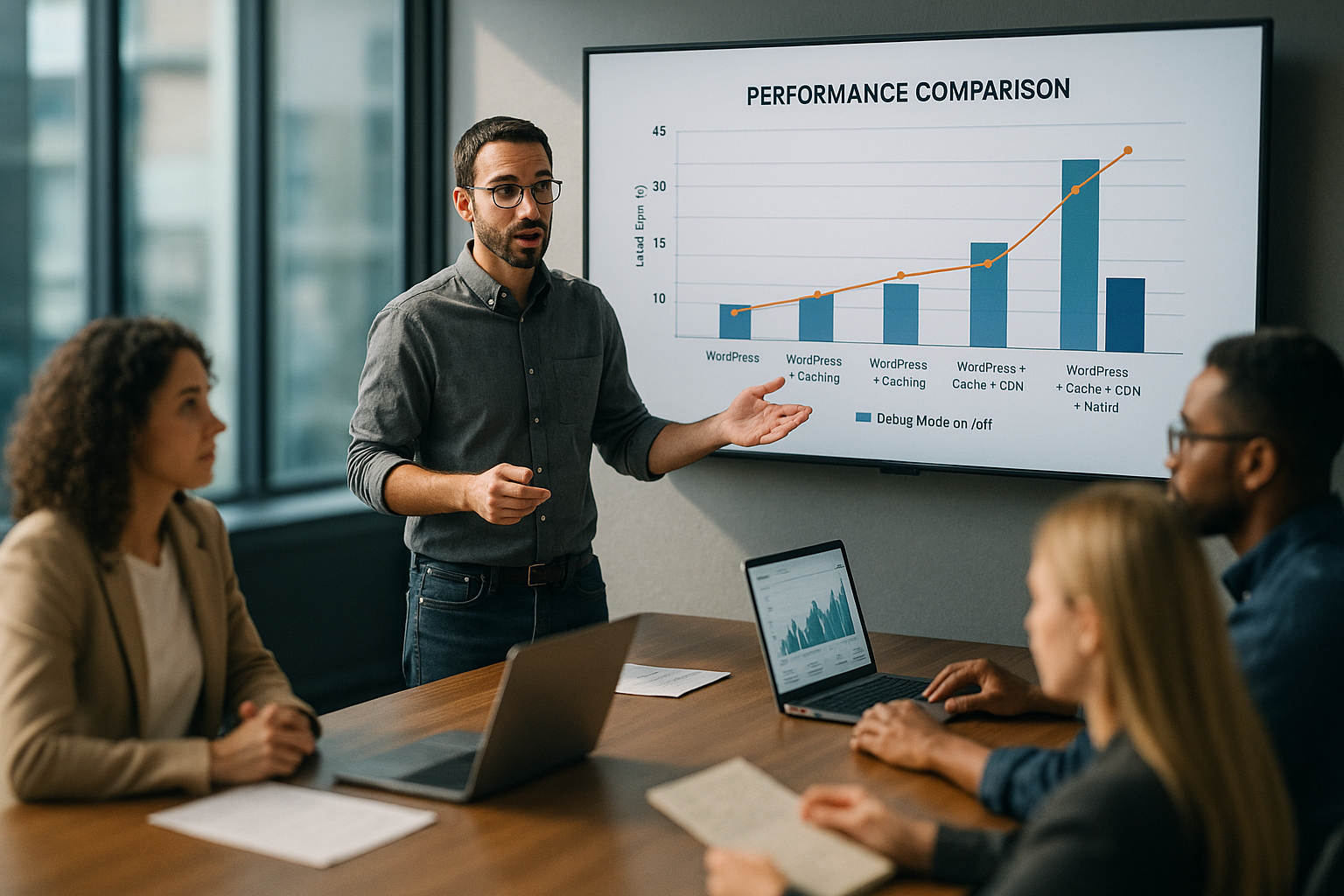
Sammenligning af målte værdier: uden vs. med fejlsøgningslogning
Afmatningen er nem at måle, fordi TTFB og serverbelastning tydeligt skifter under debug-logning. Jeg måler ofte korte svartider uden aktiv logning, som stiger mærkbart under logning. Dette gælder ikke kun for frontend-visninger, men også for administratorhandlinger, AJAX-kald og REST-slutpunkter. Selv hvis indholdet kommer statisk fra cachen, gør det ekstra logningsoverhead anmodningen langsommere. I den følgende tabel opsummerer jeg typiske Tendenser sammen.
| Præstationsfaktor | Uden fejlsøgning | Med fejlfindingslogning |
|---|---|---|
| TTFB (ms) | ≈ 200 | ≈ 1500+ |
| Serverbelastning | Lav | Høj |
| Logstørrelse (pr. dag) | 0 MB | 50-500 MB |
Disse intervaller afspejler almindelige observationer og viser, hvordan wp langsom debug er oprettet. Jeg analyserer APM-spor, sidetider og serverstatistikker sammen. Jeg ser også på filsystemets profilering for at visualisere skriveamplituder. Mønsteret er klart: Flere beskeder fører til en større andel af I/O i anmodningen. Samlet set øges ventetiden, selv om selve PHP-koden angiveligt er lige rester.

Hvorfor caching ikke er til megen hjælp mod overhead
Side- og objektcache reducerer PHP-arbejdet, men logningen starter både før og efter. Hver meddelelse genererer en ny Skriv-operation, uanset om HTML-svaret kommer fra cachen. Derfor forbliver TTFB og backend-respons øget på trods af cachen. Jeg bruger alligevel cache, men forventer ikke mirakler fra den, så længe debug-logning er aktiv. Det, der virkelig hjælper, er at slukke for kilden, ikke at maskere den med Cache.
Aktiver sikkert og sluk igen endnu hurtigere
Jeg aktiverer logningen specifikt, arbejder fokuseret og deaktiverer den umiddelbart efter analysen. Det er sådan, jeg indstiller det i wp-config.php og holder outputtet væk fra frontend:
define('WP_DEBUG', true);
define('WP_DEBUG_LOG', true);
define('WP_DEBUG_DISPLAY', false);
@ini_set('display_errors', 0);
Derefter tjekker jeg de relevante sidevisninger, isolerer kilden og indstiller WP_DEBUG til false igen. Til sidst sletter jeg en oppustet debug.log, så serveren ikke længere jonglerer med døde data. Denne disciplin sparer tid og bevarer Ydelse i hverdagen.

Logrotation og vedligeholdelse: små skridt, stor effekt
Dyrkning uden rotation debug.log uafkrydset, indtil skriveadgangene kommer ud af kontrol. Derfor sætter jeg daglig komprimering op og sletter gamle filer efter kort tid. Dette enkle trin reducerer I/O betydeligt, fordi den aktive logfil forbliver lille. Jeg bruger også regex til at filtrere typisk notice-støj for at dæmpe floden. Hvis du vil gå dybere, kan du også tjekke PHP-fejlniveauer og fejlhåndteringer for Granularitet.
Sikker aflæsning af fejl: Beskyttelse mod nysgerrige blikke
Debug-logfiler må ikke være offentligt tilgængelige, ellers falder stier og nøgler i de forkerte hænder. Jeg låser filen i Webroot konsekvent, for eksempel via .htaccess:
.
Ordre Tillad,Afvis
Afvis fra alle
.
Jeg sætter tilsvarende regler på NGINX, så ingen direkte download er mulig. Jeg indstiller også restriktive filtilladelser for at begrænse adgangen til det absolutte minimum. Sikkerhed kommer før bekvemmelighed, fordi logfiler ofte afslører mere end forventet. Korte kontrolintervaller og ryddelige logs minimerer angrebsfladen lille.

Find kilden til fejlen: Værktøjer og fremgangsmåde
For at indsnævre det bruger jeg gradvis deaktivering af plugins og en fokuseret Profilering. I mellemtiden analyserer jeg loglinjerne med tail og filtre for hurtigt at identificere de mest højlydte beskeder. Til mere dybtgående analyser bruger jeg Query Monitor i praksis, til at spore hooks, forespørgsler og HTTP-kald. Samtidig måler jeg TTFB, PHP-tid og databasens varighed, så jeg klart kan identificere flaskehalsen. Først når kilden er fundet, genaktiverer jeg plugin'et eller justerer koden, så der ikke er nogen Støj rester.
Vælg hosting-ressourcer med omtanke
Fejlfindingslogning er især mærkbar på langsom storage-hardware, fordi hver Skriv-drift tager længere tid. Jeg er derfor afhængig af hurtig I/O, tilstrækkelige CPU-reserver og passende grænser for processer. Dette inkluderer en god PHP-arbejderkonfiguration og en ren adskillelse af staging og live. Hvis du bruger staging, kan du teste opdateringer uden belastningstoppe og kan aktivere højlydt logning med god samvittighed. Mere headroom hjælper, men jeg løser årsagen, så WordPress kan køre uden Bremser Løb.
Finjustering af WP- og PHP-indstillinger
Jeg bruger ekstra justeringsskruer i wp-config.php til at styre lydstyrken præcist og minimere bivirkningerne:
// Bøj stien: Log uden for webroot
define('WP_DEBUG_LOG', '/var/log/wp/site-debug.log');
// Øg kun volumen midlertidigt, og luk derefter ned igen
@ini_set('log_errors', 1);
@ini_set('error_reporting', E_ALL & ~E_NOTICE & ~E_DEPRECATED & ~E_STRICT);
Jeg bruger en dedikeret sti til at gemme logfilen uden for webroot og adskille den rent fra implementeringer. Omkring fejl_rapportering Jeg dæmper bevidst støjen, når jeg primært leder efter hårde fejl. Så snart jeg skifter til staging, trækker jeg E_NOTICE og E_DEPRECATED ind igen for at arbejde med ældre problemer.
SAVEQUERIES, SCRIPT_DEBUG og skjulte bremser
Nogle kontakter udvikler kun en stærk bremseeffekt, når de kombineres. SPARERIER logger hver databaseforespørgsel i PHP-hukommelsesstrukturer og øger CPU- og RAM-belastningen. SCRIPT_DEBUG tvinger WordPress til at indlæse ikke-minimerede aktiver; godt for analyser, men værre for indlæsningstiden. Jeg aktiverer kun disse switches i strengt begrænsede tidsvinduer og kun i staging-miljøer. Jeg definerer også WP_ENVIRONMENT_TYPE (f.eks. “staging” eller “production”) for at kunne kontrollere adfærden i koden og undgå fejlkonfigurationer.
Serverfaktorer: PHP-FPM, lagring og fillåse
På serverniveau bestemmer jeg meget over den mærkbare effekt: PHP FPM-pools med for få arbejdere overbelaster forespørgsler, mens overdimensionerede pools øger I/O-konkurrencen. Jeg indstiller separate pools pr. site eller kritisk rute (f.eks. /wp-admin/ og /wp-cron.php) for at minimere kollisioner mellem logning og backend-arbejde. På lagersiden fungerer lokale NVMe-volumener betydeligt bedre end langsommere netværksfilsystemer, hvor fillåse og ventetid mangedobler effekten af logning. Med PHP-FPM slowlog genkender jeg flaskehalse forårsaget af hyppige error_log()-opkald eller ventetider på låse.
Offloading: Syslog, Journald og fjernforsendelse
Hvis jeg ikke kan slå logningen helt fra, aflaster jeg harddisken ved at offloade. PHP'er fejl_log kan sende beskeder til Syslog, som derefter lagres i en buffer og behandles asynkront. Dette reducerer skriveamplituden for lokale filer, men flytter indsatsen til log-subsystemet. Det er vigtigt at begrænse hastigheden, ellers erstatter jeg bare flaskehalsen. Til korte tests foretrækker jeg lokale filer (bedre kontrol), til længere analyser korte offload-faser med en klar afbrydelsesgrænse.
Målrettet debug-vindue via MU-plug-in
Jeg begrænser debug til mig selv eller et tidsvindue for at undgå støj fra produktive brugere. Et lille MU-plugin slår kun fejlsøgning til for administratorer af en bestemt IP eller cookie:
<?php
// wp-content/mu-plugins/targeted-debug.php
if (php_sapi_name() !== 'cli') {
$allow = isset($_COOKIE['dbg']) || ($_SERVER['REMOTE_ADDR'] ?? '') === '203.0.113.10';
if ($allow) {
define('WP_DEBUG', true);
define('WP_DEBUG_LOG', '/var/log/wp/site-debug.log');
define('WP_DEBUG_DISPLAY', false);
@ini_set('log_errors', 1);
@ini_set('error_reporting', E_ALL);
}
}
På den måde logger jeg kun mine egne reproduktioner og skåner resten af de besøgende. Når jeg er færdig, fjerner jeg plugin'et eller sletter cookien.
Rotation i praksis: robust og sikker
Jeg roterer logfiler med kompakte regler og er opmærksom på åbne filbeskrivelser. Kopier afkortning er nyttig, hvis processen ikke genåbner filen; ellers bruger jeg skabe og signalerer til PHP-FPM, så nye poster flyder ind i den friske fil. Et eksempel:
/var/log/wp/site-debug.log {
dagligt
roter 7
komprimere
missingok
notifempty
opret 0640 www-data www-data
postrotate
/usr/sbin/service php8.2-fpm reload >/dev/null 2>&1 || true
slutter script
}
Derudover holder jeg den aktive logfil lille (<10-50 MB), fordi korte søgninger, greps og tails kører mærkbart hurtigere og genererer færre cache-miss-kaskader i filsystemet.
WooCommerce og plugin-specifik logning
Nogle plugins har deres egne loggere (f.eks. WooCommerce). Der sætter jeg tærskelværdierne til “fejl” eller “kritisk” og deaktiverer “debug”-kanaler i produktionen. Dette reducerer dobbelt logning (WordPress og plugin) og beskytter I/O. Hvis jeg har mistanke om en fejl i pluginet, øger jeg specifikt niveauet og nulstiller det derefter med det samme.
Multisite, staging og containere
I multisite-opsætninger samler WordPress meddelelser i en fælles debug.log. Jeg fordeler dem bevidst pr. site (separat sti pr. blog-ID), så enkelte “højlydte” sites ikke bremser de andre. I containermiljøer skriver jeg midlertidigt til /tmp (hurtigt), arkivere specifikt og kassere indhold under genopbygningen. Vigtigt: Selv om filsystemet er hurtigt, forbliver CPU-belastningen ved formateringen - så jeg fortsætter med at fjerne årsagen.
Teststrategi: ren måling i stedet for gætværk
Jeg sammenligner identiske forespørgsler med og uden logning under stabiliserede forhold: samme cacheopvarmning, samme PHP FPM-arbejdere, identisk belastning. Derefter måler jeg TTFB, PHP-tid, DB-tid og I/O-ventetid. Derudover kører jeg belastningstests i 1-5 minutter, fordi effekten af store logs og lock contention kun bliver synlig under kontinuerlig skrivning. Først når målingen er konsistent, udleder jeg mål.
Databeskyttelse og lagring
Logfiler indeholder hurtigt personlige data (f.eks. forespørgselsparametre, e-mailadresser i anmodninger). Jeg holder opbevaringen på et minimum, anonymiserer, hvor det er muligt, og sletter konsekvent efter afslutning. For teams dokumenterer jeg start- og sluttidspunktet for debug-vinduet, så ingen glemmer at fjerne logningen igen. På den måde minimerer jeg risikoen, lagerkravene og de faste omkostninger.
Kort opsummeret
Aktiv Fejlfindingslogning gør WordPress langsommere, fordi hver anmodning udløser skriveoperationer og formatering, der øger TTFB og serverbelastningen. Jeg aktiverer logning specifikt, filtrerer beskeder, roterer logfilen og blokerer for adgang til debug.log. I produktive miljøer er logning fortsat undtagelsen, mens staging er reglen. Caching lindrer symptomerne, men fjerner ikke overhead pr. anmodning. Hvis du konsekvent fjerner årsagerne, sikrer du hastighed, sparer ressourcer og holder performance wordpress permanent høj.


