 Videre til indhold
Videre til indhold 
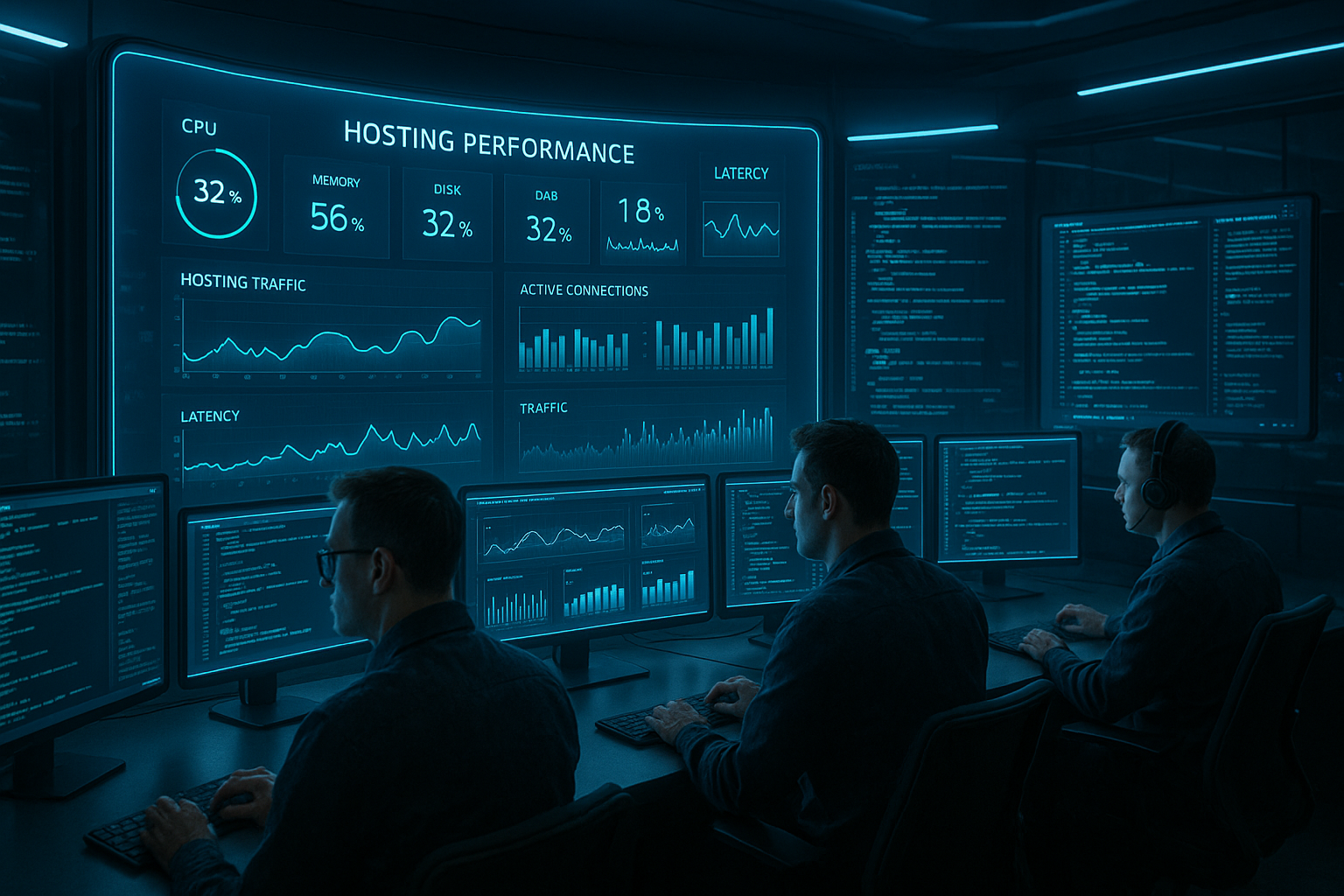
Med overvågning af hostings ydeevne opdager jeg flaskehalse tidligt, fordi Værktøjer og Logfiler giver mig de relevante signaler i realtid. Med proaktive advarsler, detektering af anomalier og rent korrelerede logdata holder jeg ventetiden nede, forhindrer udfald og understøtter synligheden i søgningen.
Centrale punkter
Jeg prioriterer klare nøgletal, automatiske advarsler og meningsfulde logdata, fordi de giver mig mulighed for at stille hurtige diagnoser og sikre driften. En struktureret opsætningsproces forhindrer målekaos og skaber et pålideligt datagrundlag for velbegrundede beslutninger. Jeg vælger få, men meningsfulde dashboards, så jeg ikke mister overblikket i stressede situationer. Integrationer i chat og ticketing forkorter svartider og reducerer eskaleringer. I sidste ende er det, der tæller, at overvågning målbart reducerer nedetid og forbedrer brugeroplevelsen i stedet for at skabe yderligere kompleksitet; for at opnå dette er jeg afhængig af klare Standarder og konsekvent Indstilling.
- Metrikker prioritere: Latenstid, fejlrate, udnyttelse
- Logfiler centralisere: strukturerede felter, kontekst, fastholdelse
- Advarsler automatisere: Tærskler, SLO'er, eskaleringsstier
- Integrationer bruge: Slack/Email, Tickets, ChatOps
- Sammenligning af værktøjerne: Funktioner, omkostninger, indsats

Hvorfor proaktiv overvågning er vigtig
Jeg venter ikke på klager fra supporten, jeg gennemskuer dem. Prognoser og Anomalier tidligt på, hvor systemerne er på vej hen. Hvert millisekund af ventetid påvirker konvertering og SEO, så jeg observerer permanente tendenser i stedet for enkeltstående toppe. Det giver mig mulighed for at fjerne unødvendige afhængigheder og skabe buffere, før der opstår spidsbelastninger. Fejl meddeler ofte sig selv: Fejlraten stiger, køerne vokser, garbage collectors kører oftere. At læse disse tegn forhindrer nedetid, reducerer omkostningerne og øger tilliden.
Hvilke målinger er virkelig vigtige?
Jeg fokuserer på nogle få kerneværdier: Apdex- eller P95-forsinkelse, fejlrate, CPU/RAM, I/O, netværksforsinkelse og tilgængelige DB-forbindelser, så jeg kan bestemme status på få sekunder. Uden klarhed om ressourcer overser jeg ofte årsagen, så jeg er opmærksom på korrelerede visninger på alle niveauer. For værtsvisningen hjælper følgende mig Overvåg brugen af serverefor hurtigt at se flaskehalse på node-niveau. Jeg evaluerer bevidst måleintervallerne, fordi 60-sekunders scrapes går glip af korte spidser, mens 10-sekunders intervaller viser finere mønstre. Det er stadig vigtigt at spejle målingerne i forhold til definerede SLO'er, ellers mister jeg Prioritet og den Sammenhæng.
Metrisk design: USE/RED, histogrammer og kardinalitet
Jeg strukturerer signaler i henhold til gennemprøvede metoder: Jeg bruger USE-rammen (Utilisation, Saturation, Errors) på værtsniveau og RED-modellen (Rate, Errors, Duration) på serviceniveau. På den måde forbliver hver graf målrettet og verificerbar. Jeg måler latenstider med histogrammer i stedet for bare gennemsnitsværdier, så P95/P99 er pålidelige, og regressioner er synlige. Klart definerede spande forhindrer aliasing: for grove spidser sluges, for fine øger hukommelsen og omkostningerne. For højfrekvente slutpunkter holder jeg kopidata klar, så jeg kan spore individuelle langsomme anmodninger.
Kardinalitet er et kontrolgreb for mig: Etiketter som user_id eller request_id hører hjemme i logs/traces, men sjældent i metrics. Jeg holder label-sættene små, stoler på service/version/region/miljø og dokumenterer navngivningsstandarder. Det gør dashboards hurtige, storage planlægbar og forespørgsler overskuelige. Jeg versionerer metrikker (f.eks. http_server_duration_seconds_v2), når jeg skifter buckets, så historiske sammenligninger ikke bliver forældede.

Logfiler som et tidligt advarselssystem
Logs viser mig, hvad der virkelig sker, fordi de gør kodestier, timing og brugerkontekster synlige. Jeg strukturerer felter som trace_id, user_id, request_id og service, så jeg kan spore anmodninger fra start til slut. Til det operationelle arbejde bruger jeg Analyser logfilerat genkende fejlkilder, ventetidsspidser og sikkerhedsmønstre hurtigere. Uden klart definerede logniveauer bliver mængden dyr, og det er derfor, jeg bruger debug sparsomt og kun øger den i kort tid. Jeg definerer opbevaringsperioder, filtre og maskering, så data forbliver nyttige, lovmedholdelige og klar i stedet for Spredt.
Omkostninger under kontrol: kardinalitet, fastholdelse, prøveudtagning
Jeg kontrollerer aktivt omkostningerne: Jeg adskiller logdata i varme/varme/kolde niveauer, hver med sin egen opbevaring og komprimering. Jeg normaliserer eller deduplikerer fejlbehæftede, ekstremt højlydte hændelser ved indlæsningen, så de ikke dominerer dashboards. Jeg sampler spor dynamisk: fejl og høje latenstider altid, normale tilfælde kun forholdsmæssigt. Til metrikker vælger jeg downsampling til langsigtede tendenser og holder rådata korte, så lagerudnyttelsen forbliver forudsigelig. Et omkostningsdashboard med €/host, €/GB og €/alert gør forbruget synligt; budgetadvarsler forhindrer overraskelser sidst på måneden.
Værktøjer i sammenligning: styrker på et øjeblik
Jeg foretrækker løsninger, der kombinerer logfiler, metrikker og spor, fordi de hjælper mig med at finde de grundlæggende årsager hurtigere. Better Stack, Sematext, Sumo Logic og Datadog dækker mange applikationsscenarier, men adskiller sig i deres fokus, drift og prislogik. For teams med Kubernetes og AWS kan tæt cloud-integration betale sig. Hvis du vil beholde data, skal du være opmærksom på eksportfunktioner og langtidsopbevaring. Før jeg træffer en beslutning, tjekker jeg TCO, opsætningsindsats og indlæringskurve, for fordelagtige tariffer er ikke til megen nytte, hvis indsatsen stiger, og det er svært at lære. Resultater til sidst sparsom forbliver.
| Værktøj | Fokus | Styrker | Ideel til | Pris/hint |
|---|---|---|---|---|
| Bedre stak | Logfiler + oppetid | Enkel grænseflade, hurtig søgning, gode dashboards | Startups, teams med klare arbejdsgange | fra ca. et tocifret beløb pr. måned, afhængigt af volumen |
| Sematext | ELK-lignende loghåndtering | Mange integrationer, advarsler i realtid, infrastruktur + app | Hybride miljøer, alsidig telemetri | skaleret med GB/dag, fra et tocifret beløb pr. måned. |
| Sumo-logik | Log-analyser | Trendregistrering, anomalier, forudsigelige analyser | Sikkerheds- og compliance-teams | Volumenbaseret, mellemhøjt til højt €-niveau |
| Datadog | Logfiler + målinger + sikkerhed | ML-anomalier, servicekort, stærk cloud-forbindelse | Skalering af cloud-arbejdsbelastninger | modulær pris, funktioner separat, € afhængigt af omfang |
Jeg tester værktøjer med rigtige peaks i stedet for kunstige prøver, så jeg ærligt kan se grænserne for ydeevnen. En robust POC omfatter datapipelines, alarmering, on-call routing og autorisationskoncepter. Jeg går først i gang, når analyser, fastholdelse og omkostningskurver er rigtige. På den måde undgår jeg friktion senere og holder mit værktøjslandskab slankt. I sidste ende er det, der tæller, at værktøjet opfylder mine Team hurtigere og Fejlcitat presser.
Opsæt automatiske advarsler
Jeg definerer tærskelværdier baseret på SLO'er, ikke mavefornemmelse, så alarmerne forbliver pålidelige. P95-latency, fejlrate og kø-længde er velegnede som indledende beskyttelseslinjer. Hvert signal har brug for en eskaleringssti: chat, telefon og derefter incident ticket med klart ejerskab. Tidsbaseret undertrykkelse forhindrer alarmoversvømmelser under planlagte implementeringer. Jeg dokumenterer kriterier og ansvarsområder, så nye teammedlemmer kan handle trygt, og Parathed ikke i Alarmtræthed hælder.
Hændelsesberedskab: Runbooks, øvelser, postmortems
Jeg tænker på runbooks som korte beslutningstræer, ikke romaner. En god alarm linker til diagnostiske trin, tjeklister og muligheder for at rulle tilbage. Jeg øver eskaleringer i dry runs og game days, så teamet forbliver roligt i virkelige sager. Efter hændelser skriver jeg postmortems uden skyld, definerer konkrete tiltag med ejer og forfaldsdato og forankrer dem i køreplanen. Jeg måler MTTA/MTTR og alarmpræcisionen (true/false positives), så jeg kan se, om mine forbedringer virker.
Integrationer, der fungerer i hverdagen
Jeg videresender kritiske advarsler til Slack eller e-mail, og i tilfælde af høj prioritet også via telefonopkald, så ingen går glip af begivenheder. Ticket-integrationer sikrer, at der automatisk oprettes en opgave med kontekst ud fra en alarm. Jeg forbinder webhooks med runbooks, der foreslår handlingstrin eller endda udløser afhjælpning. Gode integrationer forkorter MTTA og MTTR mærkbart og holder nerverne i ro. Det, der tæller, især om natten, er, at processerne er effektive, at rollerne er klare, og at Handling kommer hurtigere end Usikkerhed.
Fra symptomer til årsager: APM + logfiler
Jeg kombinerer Application Performance Monitoring (APM) med logkorrelation for at se fejlveje fremhævet. Traces viser mig, hvilken tjeneste der er langsom, og logs giver detaljer om undtagelsen. Det giver mig mulighed for at afsløre N+1-forespørgsler, langsomme tredjeparts-API'er eller defekte cacher uden at skulle famle i blinde. Jeg bruger sampling på en målrettet måde, så omkostningerne forbliver overkommelige, og hot paths er helt synlige. Med denne kobling indstiller jeg rettelser på en målrettet måde, beskytter udgivelsestempoet og øger kvalitet med mindre Stress.

DB-, cache- og kø-signaler, der tæller
For databaser overvåger jeg ikke kun CPU, men også udnyttelsen af forbindelsespuljen, ventetider på låse, replikationsforsinkelse og andelen af de langsomste forespørgsler. For cacher er jeg interesseret i hitrate, evictions, refill latency og andelen af stale reads; hvis hitraten falder, er der risiko for lavineeffekt på databasen. For køer er jeg opmærksom på backlog-alder, consumer lag, throughput pr. consumer og dead letter rate. På JVM/.NET-siden måler jeg GC-pause, heap-udnyttelse og mætning af trådpuljen, så jeg ærligt kan se headroom.
Praktisk drejebog: De første 30 dages overvågning
I den første uge afklarer jeg mål, SLO'er og metrikker, opsætter grundlæggende dashboards og registrerer de vigtigste tjenester. I uge to aktiverer jeg log-pipelines, normaliserer felter og opsætter de første alarmer. I uge tre korrigerer jeg tærskler, linker runbooks og tester eskaleringer i tørløbet. I uge fire optimerer jeg omkostningerne gennem retention-profiler og tjekker dashboards for forståelighed. Slutresultatet er klare drejebøger, pålidelige alarmer og målbare resultater. Forbedringersom jeg har i Team dele.
Kapacitetsplanlægning og robusthedstest
Jeg planlægger ikke kapacitet ud fra mavefornemmelse, men ud fra tendenser, SLO-forbrug og belastningsprofiler. Trafikafspilninger fra rigtige brugerstrømme viser mig, hvordan systemerne reagerer under spidsbelastninger. Jeg tester automatisk skalering med ramp-up-tid og skalerer backups (min/max), så jeg ikke bliver ramt af kolde starter. Canary releases og progressive udrulninger begrænser risikoen; jeg overvåger forbruget af fejlbudgetter pr. release og stopper udrulninger, hvis SLO'er vælter. Kaos- og failover-øvelser beviser, at HA ikke er ønsketænkning: Sluk for regionen, mist databaselederen, tjek DNS failover.
Valg af hostingudbyder: Hvad jeg holder øje med
Jeg tjekker kontraktlig tilgængelighed, supportresponstider og reel ydeevne under belastning, ikke kun markedsføringspåstande. Det, der tæller for mig, er, hvor hurtigt serverne reagerer, hvor konsekvent storage fungerer, og hvor hurtigt patches er tilgængelige. Udbydere som webhoster.de scorer point med gode pakker og pålidelig infrastruktur, som i høj grad sikrer projekterne. Jeg kræver gennemsigtige statussider, klare vedligeholdelsesvinduer og meningsfulde målinger. Hvis du opfylder disse punkter, reducerer du risikoen, gør Overvågning og beskytter den Budget.

Overblik over Edge, DNS og certifikater
Jeg overvåger ikke kun oprindelsen, men også kanten: CDN-cache hit rate, origin fallbacks, HTTP state distribution og latency per POP. DNS-tjek kører fra flere regioner; jeg tjekker NS-sundhed, TTL'er og rekursionsfejlrater. Jeg lader TLS-certifikater udløbe tidligt (alarm 30/14/7 dage i forvejen) og overvåger cipher suites og handshake-tider, da disse kendetegner den opfattede ydeevne. Syntetiske rejser kortlægger kritiske brugerstier (login, checkout, søgning), og RUM viser mig rigtige slutenheder, netværk og browservarianter. Begge dele repræsenterer det eksterne perspektiv og supplerer servermålinger.
Oppetid, SLO'er og budgetter
Jeg måler tilgængelighed med eksterne kontroller, ikke kun internt, så jeg kan kortlægge reelle brugerstier. Et serviceniveaumål uden et målepunkt forbliver en påstand, så jeg kobler SLO'er med uafhængige kontroller. En sammenligning som f.eks. Overvågning af oppetidtil hurtigt at vurdere dækning, intervaller og omkostninger. Jeg planlægger budgetter pr. GB log, pr. host og pr. kontrolinterval, så omkostningerne forbliver forudsigelige. Den, der gør SLO-fejl synlige, argumenterer rent for roadmaps og vinder Baggrund med hver eneste Prioritering.

Datapipeline og kontekst: ren forbindelse af telemetri
Jeg er afhængig af kontinuerlig kontekst: trace_id og span_id ender i logfiler, så jeg kan springe direkte fra en fejllog til sporet. Jeg registrerer implementeringshændelser, funktionsflag og konfigurationsændringer som separate hændelser; korrelationsoverlejringer på graferne viser, om en ændring påvirker målingerne. Jeg er opmærksom på label-hygiejne: klare navneområder, konsistente nøgler og hårde grænser for at forhindre ukontrolleret vækst. Tail-based sampling prioriterer unormale spænd, mens head-based sampling reducerer belastningen; jeg kombinerer begge dele for hver tjeneste. Det holder indsigten skarp og omkostningerne stabile.
Ergonomi på vagt og teamets sundhed
Jeg strukturerer alarmer efter sværhedsgrad, så man ikke bliver vækket af hver eneste spids. Sammenfattende begivenheder (gruppering) og stille timer reducerer støjen uden at øge risikoen. Rotationer er retfærdigt fordelt, overdragelser er dokumenteret, og en backup er tydeligt navngivet. Jeg måler antallet af personsøgere pr. person, antallet af falske alarmer og natlige indgreb for at forhindre alarmtræthed. Trænede førstehjælpstrin (first responder playbook) giver sikkerhed; mere dybtgående analyser følger først, når situationen er stabil. På den måde forbliver beredskabet bæredygtigt og teamet modstandsdygtigt.
Integrer signaler om sikkerhed og overholdelse af regler
Jeg ser sikkerhed som en del af overvågningen: afvigelser i login-frekvenser, usædvanlige IP-klynger, 4xx/5xx-mønstre og WAF/audit-logfiler flyder ind i mine dashboards. Jeg maskerer konsekvent PII; kun det, der er nødvendigt for diagnosticering, forbliver synligt. Jeg organiserer opbevarings- og adgangsrettigheder i henhold til need-to-know, og revisionsspor dokumenterer forespørgsler på følsomme data. Det holder sikkerhed, diagnosticering og compliance i balance uden at miste driftshastighed.
Kort resumé
Jeg holder overvågningen slank, målbar og handlingsorienteret, så den fungerer fra dag til dag. Kernemålinger, centraliserede logfiler og klare advarsler giver mig hurtig diagnose og respons. Med en fokuseret værktøjsstak sparer jeg omkostninger uden at gå på kompromis med indsigten. Integrationer, playbooks og SLO'er gør arbejdet med hændelser mere roligt og sporbart. Det betyder, at overvågning af hostingperformance ikke er et mål i sig selv, men en Håndtag for bedre Tilgængelighed og stabile brugerrejser.


