 Ir al contenido
Ir al contenido 
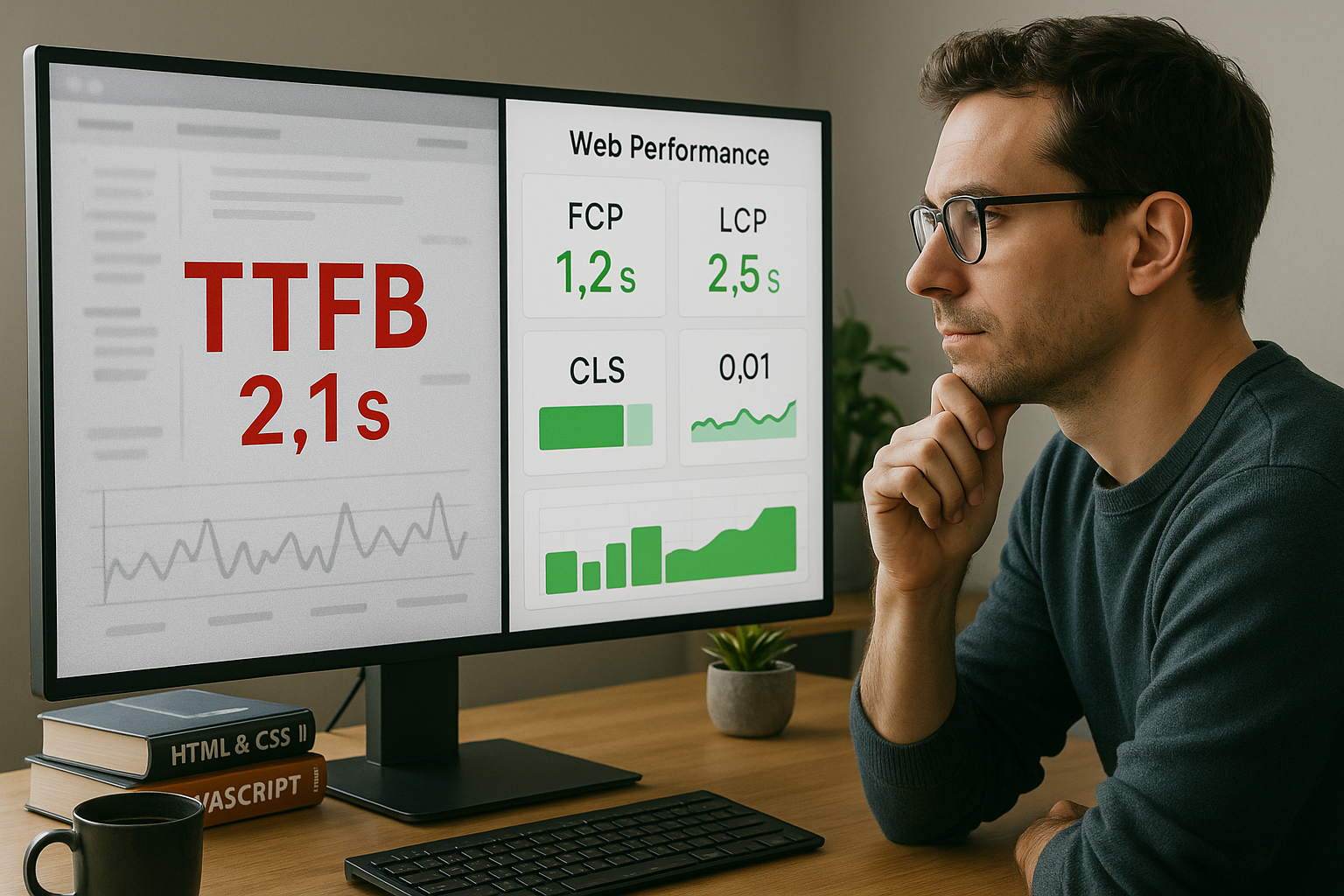
Un análisis TTFB bien fundamentado muestra por qué a menudo se malinterpreta la marca de tiempo del primer byte y cómo combino las mediciones con las métricas de usuario de forma significativa. Explico específicamente dónde se producen las interpretaciones erróneas, cómo recopilo datos coherentes y qué optimizaciones el Percepción aumentar realmente la velocidad.
Puntos centrales
- TTFB describe el arranque del servidor, no la velocidad global.
- Contexto en lugar de un único valor: Leer LCP, FCP, INP.
- Ubicación y la red caracterizan los valores medidos.
- Almacenamiento en caché y CDN reducen la latencia.
- Recursos y la configuración tienen un efecto directo.

El TTFB explicado brevemente: Comprender la cadena de medición
El TTFB mapea el tiempo desde la petición hasta el primer byte devuelto y comprende varios pasos, que yo llamo Cadena de medición debe tenerse en cuenta. Esto incluye la resolución DNS, el handshake TCP, la negociación TLS, el procesamiento del servidor y el envío del primer byte. Cada sección puede crear cuellos de botella, lo que modifica significativamente el tiempo total. Una herramienta muestra aquí un único valor, pero las causas se encuentran en varios niveles. Por ello, separo la latencia del transporte, la respuesta del servidor y la lógica de la aplicación para Fuentes de error claramente asignable.
Optimizar la ruta de red: DNS a TLS
Empezaré por el nombre: Los resolvedores DNS, las cadenas CNAME y los TTL influyen en la rapidez con la que se resuelve un host. Demasiados redireccionamientos o un resolutor con alta latencia añaden milisegundos apreciables. Luego cuenta la conexión: Reduzco los viajes de ida y vuelta con keep-alive, estrategias tipo TCP fast-open y compartición rápida de puertos. Con TLS, compruebo la cadena del certificado, el grapado OCSP y la reanudación de la sesión. Una cadena de certificados corta y un grapado activado ahorran apretones de manos, mientras que los protocolos modernos como HTTP/2 y HTTP/3 multiplexan las peticiones de forma eficiente a través de una conexión.
También me fijo en la ruta: IPv6 puede tener ventajas en redes bien conectadas, pero las rutas peering débiles aumentan el jitter y la pérdida de paquetes. En las redes móviles, cada viaje de ida y vuelta desempeña un papel más importante, por lo que estoy a favor de mecanismos 0-RTT, ALPN y versiones rápidas de TLS. Lo importante para mí es que la optimización del transporte no sólo acelere el TTFB, sino que también estabilice la varianza. Un intervalo de medida estable hace que mis optimizaciones sean más reproducibles y mis decisiones más fiables.
Las 3 interpretaciones erróneas más comunes
1) TTFB significa velocidad total
Un TTFB bajo dice poco sobre el renderizado, la entrega de imágenes o la ejecución de JavaScript, es decir, sobre lo que la gente puede hacer directamente. Véase. Una página puede enviar un primer byte al principio, pero fallar después debido al mayor contenido (LCP). A menudo observo primeros bytes rápidos con una interactividad lenta. La velocidad percibida sólo se produce cuando el contenido relevante aparece y reacciona. Esta es la razón por la que una vista fija TTFB acopla el Realidad de uso a partir del valor medido.
2) Bajo TTFB = buena UX y SEO
Puedo empujar artificialmente TTFB, por ejemplo mediante el uso de cabeceras tempranas, sin proporcionar contenido útil, que es lo que el verdadero Valor útil no aumenta. Los motores de búsqueda y las personas valoran más la visibilidad y la usabilidad que el primer byte. Métricas como LCP e INP reflejan mejor cómo se siente la página. Un enfoque puramente TTFB ignora los pasos críticos de renderización e interactividad. Por tanto, yo mido además para que las decisiones puedan basarse en Datos con relevancia.
3) Todos los valores TTFB son comparables
El punto de medición, el peering, la carga y la distancia distorsionan comparaciones que difícilmente podría hacer sin las mismas condiciones marco. Tarifa puede. Un servidor de prueba en EE.UU. mide de forma diferente a uno en Fráncfort. Las fluctuaciones de carga entre la mañana y la noche también modifican notablemente los resultados. Por ello, hago varias pruebas, al menos en dos lugares y a distintas horas. Sólo este rango proporciona una Clasificación del valor.

Sintéticos vs. RUM: dos perspectivas sobre TTFB
Combino las pruebas sintéticas con la monitorización de usuarios reales (RUM) porque ambas responden a preguntas diferentes. Las sintéticas me proporcionan puntos de referencia controlados con marcos claros, ideales para pruebas de regresión y comparaciones. La RUM refleja la realidad en distintos dispositivos, redes y regiones y muestra cómo fluctúa el TTFB sobre el terreno. Trabajo con percentiles en lugar de medias para reconocer los valores atípicos y segmentar por dispositivo (móvil/escritorio), país y calidad de la red. Sólo cuando se encuentran patrones en ambos mundos evalúo las causas y las medidas como sólidas.
¿Qué influye realmente en el TTFB?
La elección del entorno de alojamiento tiene una gran repercusión en la latencia, la IO y el tiempo de computación, lo que se refleja directamente en la TTFB muestra. Los sistemas sobrecargados responden más lentamente, mientras que los SSD NVMe, las pilas modernas y las buenas rutas de peering permiten tiempos de respuesta cortos. La configuración del servidor también cuenta: una configuración de PHP inadecuada, una opcache débil o una RAM escasa provocan retrasos. Con las bases de datos, noto consultas lentas en cada petición, especialmente con tablas no indexadas. Una CDN reduce la distancia y disminuye el Latencia para contenidos estáticos y en caché.
PHP-FPM y la optimización en tiempo de ejecución en la práctica
Compruebo el gestor de procesos: muy pocos PHP workers generan colas, demasiados desplazan cachés de la RAM. Equilibro ajustes como max_children, pm (dynamic/ondemand) y límites de peticiones basándome en perfiles de carga reales. Mantengo Opcache caliente y estable, reduzco la sobrecarga del autoloader (classmaps optimizados), activo la caché realpath y elimino las extensiones de depuración en producción. Muevo las inicializaciones costosas a bootstraps y almaceno los resultados en la caché de objetos. Esto reduce el tiempo entre la aceptación del socket y el primer byte sin tener que sacrificar la funcionalidad.
Cómo medir correctamente la TTFB
Pruebo varias veces, en momentos diferentes, en al menos dos lugares y formo medianas o percentiles para una fiable Base. También compruebo si la caché está caliente porque el primer acceso suele tardar más que todos los accesos posteriores. Correlaciono TTFB con LCP, FCP, INP y CLS para que el valor tenga sentido en el conjunto. Para ello, utilizo ejecuciones dedicadas para HTML, recursos críticos y contenidos de terceros. Un buen punto de partida es la evaluación en torno a Core Web Vitalsporque son los Percepción de los usuarios.
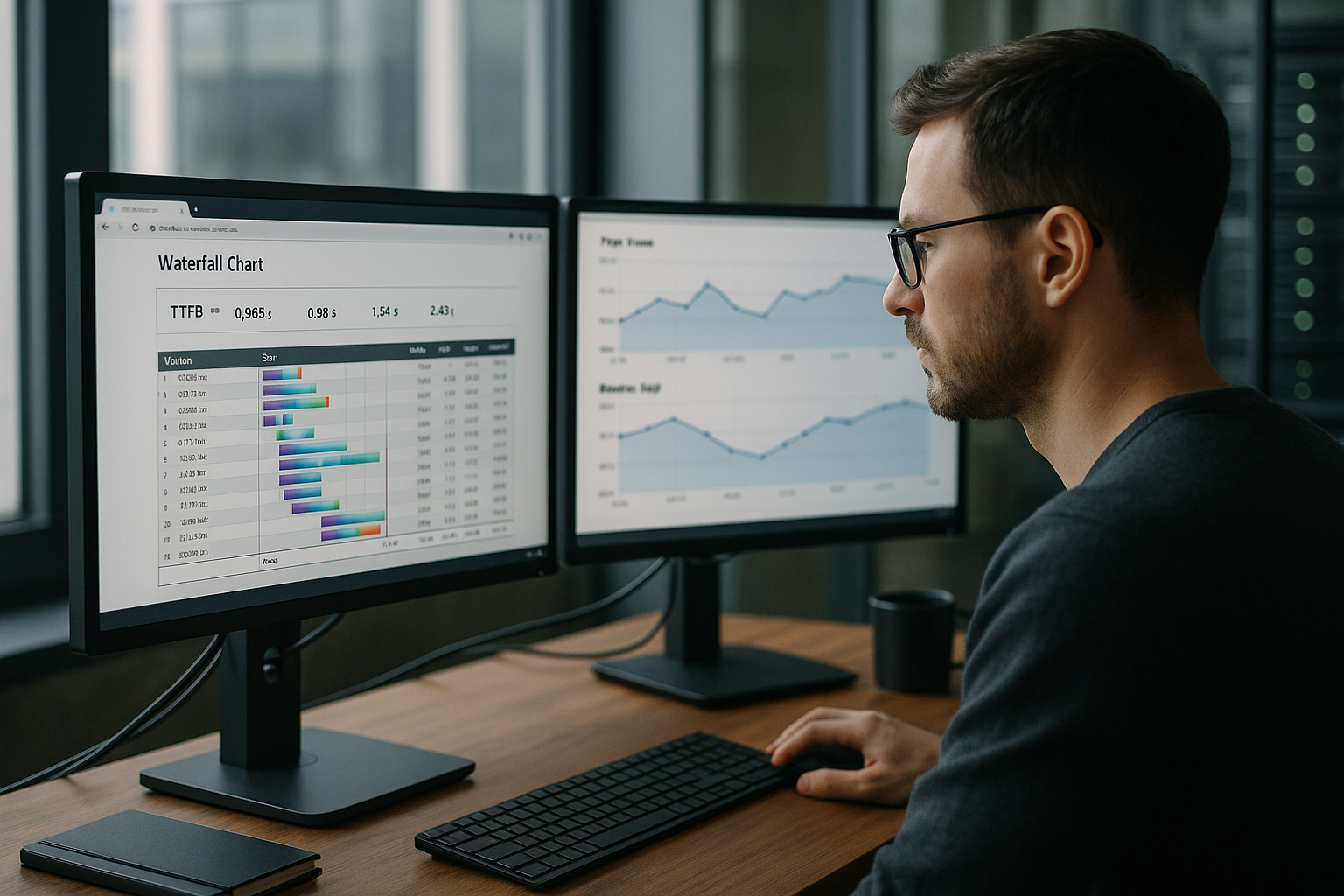
Cronometraje y trazabilidad de los servidores
También envío cabeceras de temporización del servidor para que los tiempos compartidos sean transparentes: por ejemplo, dns, connect, tls, app, db, cache. Añado los mismos marcadores a los registros y proporciono solicitudes con ID de seguimiento para poder rastrear ejecuciones individuales a través de CDN, Edge y Origin. Esta granularidad evita los juegos de adivinanzas: En lugar de "TTFB es alto", puedo ver si la base de datos necesita 180 ms o el Origin está atascado en una cola durante 120 ms. Con los percentiles por ruta (por ejemplo, detalle de producto frente a búsqueda), defino presupuestos claros y puedo detener regresiones en el CI en una fase temprana.
Buenas prácticas: Primer byte más rápido
Utilizo el almacenamiento en caché del lado del servidor para el HTML, de modo que el servidor pueda entregar respuestas preparadas y el CPU no tiene que recalcular cada solicitud. Una CDN global acerca el contenido a los usuarios y reduce la distancia, el tiempo de DNS y el enrutamiento. Mantengo actualizados PHP, la base de datos y el servidor web, activo Opcache y utilizo HTTP/2 o HTTP/3 para un mejor aprovechamiento de la conexión. Muevo las costosas llamadas a API externas de forma asíncrona o las almaceno en caché para que el primer byte no espere ocioso. La elaboración periódica de perfiles cubre las consultas lentas y Plugins que desactivo o reemplazo.
Estrategias de caché detalladas: TTL, Vary y Microcaching
Hago una distinción estricta entre dinámico y almacenable en caché. El HTML recibe TTLs cortos y microcaching (por ejemplo, 5-30 s) para los picos de carga, mientras que las respuestas API con cabeceras de control de caché y ETags claras pueden vivir más tiempo. Uso Vary de forma selectiva: Sólo cuando el idioma, las cookies o el agente de usuario generan realmente un contenido diferente. Las claves Vary demasiado amplias destruyen el ratio de aciertos. Con stale-while-revalidate entrego inmediatamente y refresco en segundo plano; stale-if-error mantiene la página accesible si el backend se cuelga. Importante: Evite las cookies en el dominio raíz si impiden involuntariamente el almacenamiento en caché.
Para los cambios, planifico una limpieza de la caché mediante parámetros de versión o hashes de contenido. Limito las invalidaciones de HTML a las rutas afectadas en lugar de activar purgas globales. Para las CDN, utilizo calentamientos regionales y un escudo de origen para proteger el servidor de origen. Esto mantiene el TTFB estable incluso durante los picos de tráfico sin tener que sobredimensionar la capacidad.
TTFB frente a experiencia de usuario: métricas importantes
Califico LCP de Mayor Contenido Visible, FCP de Primer Contenido e INP de Respuesta de Entrada porque estas métricas son la experiencia notable hacer. Una página puede tener un TTFB moderado y seguir pareciendo rápida si la renderización importante se produce pronto. Por el contrario, un TTFB pequeño no sirve de mucho si los scripts de bloqueo retrasan la visualización. Yo utilizo el Análisis del faropara comprobar la secuencia de recursos, la ruta de renderizado y las prioridades. Esto me permite ver qué optimización realmente Ayuda a.

Establecer correctamente las prioridades de renderizado
Me aseguro de que los recursos críticos estén por encima de todo lo demás: CSS crítico en línea, fuentes con font-display y precarga/priorización sensible, imágenes en above-the-fold con fetchpriority apropiado. Cargo JavaScript lo más tarde o de forma asíncrona posible y despejo la carga del hilo principal para que el navegador pueda pintar rápidamente. Utilizo sugerencias tempranas para activar precargas antes de la respuesta final. Resultado: Aunque el TTFB no sea perfecto, la página parece mucho más rápida gracias a la visibilidad temprana y la respuesta rápida.
Evitar errores de medición: obstáculos típicos
Una caché caliente distorsiona las comparaciones, por eso diferencio entre peticiones frías y calientes. separar. Una CDN también puede tener bordes obsoletos o no replicados, lo que prolonga la primera recuperación. Compruebo la utilización del servidor en paralelo para que las copias de seguridad o los cron jobs no influyan en la medición. En el lado del cliente, presto atención a la caché del navegador y a la calidad de la conexión para minimizar los efectos locales. Incluso los resolvedores de DNS modifican la latencia, por lo que mantengo el entorno de prueba como constante.
Considerar CDN, WAF y capas de seguridad
Los sistemas intermediarios como WAF, filtros bot y protección DDoS pueden aumentar el TTFB sin que el origen sea culpable. Compruebo si la terminación TLS tiene lugar en el borde, si hay un escudo activo y cómo las reglas activan comprobaciones complejas. Los límites de velocidad, el geofencing o los retos de JavaScript suelen ser útiles, pero no deberían desplazar los valores medios sin que se note. Por lo tanto, mido por separado los aciertos en el borde y los fallos en el origen y tengo listas reglas de excepción para pruebas sintéticas con el fin de distinguir los problemas reales de los mecanismos de protección.
Decisiones de alojamiento rentables
Rápidas unidades SSD NVMe, suficiente RAM y modernas CPU proporcionan al backend potencia suficiente. Actuaciónpara que las respuestas comiencen rápidamente. Escalo los PHP workers para adaptarlos al tráfico, de modo que las peticiones no se pongan en cola. El impacto de este cuello de botella a menudo sólo se hace evidente bajo carga, por lo que planifico la capacidad de forma realista. Para una planificación práctica, la guía de Planificar correctamente a los trabajadores de PHP. La proximidad al mercado objetivo y un buen peering también mantienen el Latencia bajo.

Procesos de implantación y calidad
Trato el rendimiento como una característica de calidad en la entrega: defino presupuestos para TTFB, LCP e INP en la canalización CI/CD y bloqueo las versiones con regresiones claras. Las versiones Canary y los indicadores de características me ayudan a dosificar los riesgos y medirlos paso a paso. Antes de introducir cambios importantes, realizo pruebas de carga para identificar los límites de los trabajadores, los límites de conexión y los bloqueos de las bases de datos. Con pruebas de humo recurrentes en rutas representativas, reconozco los deterioros inmediatamente, no sólo cuando llega el pico. Esto me permite mantener la mejora medida a largo plazo.
Tabla práctica: Escenarios de medición y medidas
A continuación se describen situaciones típicas y se relacionan los TTFB observados con otras cifras clave y tangibles. Pasos. Las utilizo para acotar más rápidamente las causas y derivar medidas con claridad. Sigue siendo importante comprobar los valores varias veces y leer las métricas contextuales. Así evito tomar decisiones que sólo actúan sobre los síntomas y no mejoran la percepción. La tabla me ayuda a planificar y analizar las pruebas. Prioridades para fijar.
| Escenario | Observación (TTFB) | Métricas complementarias | Posible causa | Medida concreta |
|---|---|---|---|---|
| Primera llamada de la mañana | Alta | LCP ok, FCP ok | Caché en frío, DB wakeup | Precalentar la caché del servidor, mantener las conexiones a la base de datos |
| Pico de tráfico | Aumenta a pasos agigantados | El INP se deterioró | Demasiados pocos trabajadores PHP | Aumentar los trabajadores, externalizar las tareas largas |
| Acceso global EE.UU. | Significativamente superior | LCP fluctúa | Distancia, peering | Activar CDN, utilizar edge cache |
| Muchas páginas de productos | Inestable | FCP bien, LCP mal | Imágenes grandes, sin pistas tempranas | Optimizar las imágenes, dar prioridad a la precarga |
| API de terceros | Cambiable | INP ok | Tiempo de espera para la API | Respuestas en caché, procesamiento asíncrono |
| Actualización del backend CMS | Más alto que antes | CLS sin cambios | Un nuevo plugin pone freno | Perfilar, sustituir o parchear plug-ins |
Resumen: Clasificar correctamente TTFB en su contexto
Un único valor TTFB rara vez explica cómo se siente una página, así que lo relaciono con LCP, FCP, INP y real Usuarios. Mido varias veces, sincronizo ubicaciones y compruebo la carga para obtener resultados coherentes. Para un lanzamiento rápido, utilizo caché, CDN, software actualizado y consultas ajustadas. Al mismo tiempo, doy prioridad a la renderización de contenidos visibles porque una visibilidad temprana mejora claramente la percepción. Así es como mi análisis TTFB conduce a decisiones que optimizan la Experiencia de los visitantes.


