 Ir al contenido
Ir al contenido 
HTTP Keep-Alive reduce los handshakes y mantiene abiertas las conexiones, de modo que varias solicitudes se ejecutan a través del mismo socket y la Carga del servidor disminuye. Con un ajuste específico, controlo los tiempos de espera, los límites y los trabajadores, y reduzco Latencias y aumenta el rendimiento sin necesidad de modificar el código.
Puntos centrales
- Reutilización de la conexión Reduce la sobrecarga de la CPU y los handshakes.
- Corto Tiempos muertos Evita las conexiones inactivas.
- Limpiar Límites para estabilizar la carga de keepalive_requests.
- HTTP/2 y HTTP/3 aún más.
- Realista Pruebas de carga Guardar ajustes.
Cómo funciona HTTP Keep-Alive
En lugar de abrir una nueva conexión TCP para cada recurso, reutilizo una conexión existente y así ahorro Apretones de manos y viajes de ida y vuelta. Esto reduce los tiempos de espera, ya que ni las configuraciones TCP ni TLS tienen que estar en funcionamiento constantemente y el canal responde rápidamente. El cliente reconoce mediante el encabezado que la conexión permanece abierta y envía más solicitudes sucesivamente o con multiplexación (en HTTP/2/3) a través del mismo Zócalo. El servidor gestiona la fase de inactividad mediante un tiempo de espera de mantenimiento de conexión y cierra la línea si no se recibe ninguna solicitud durante demasiado tiempo. Este comportamiento acelera notablemente las páginas con muchos activos y alivia la carga de la CPU, ya que se producen menos establecimientos de conexión.

Reutilización de conexiones: efecto sobre la carga del servidor
Cada nueva conexión evitada ahorra tiempo de CPU para el trabajo del núcleo y TLS, lo que veo en la monitorización como una curva de carga más suave. Los datos muestran que la reutilización de los sockets existentes puede aumentar el rendimiento hasta en un 50 % cuando se producen muchas solicitudes pequeñas. En las pruebas de rendimiento con muchas solicitudes GET, la duración total se reduce a la mitad en algunos casos por un factor de tres, ya que se producen menos handshakes y menos cambios de contexto. La carga de la red también disminuye, ya que los paquetes SYN/ACK son menos frecuentes y el servidor tiene más presupuesto para la lógica de la aplicación propiamente dicha. Esta interacción proporciona respuestas más rápidas y más estables. Tiempos de respuesta bajo carga.
Riesgos: tiempos de espera demasiado largos y conexiones abiertas
Un tiempo de espera de mantenimiento de conexión demasiado generoso deja las conexiones inactivas y bloquea Trabajador o subprocesos, aunque no haya ninguna solicitud pendiente. Cuando el tráfico es elevado, los sockets abiertos aumentan, alcanzan los límites de los descriptores de archivos y elevan el consumo de memoria. Además, los tiempos de espera inadecuados de los clientes generan conexiones „muertas“ que envían solicitudes a sockets ya cerrados y producen mensajes de error. Las puertas de enlace de entrada y NAT pueden cerrar las líneas inactivas antes que el servidor, lo que provoca reinicios esporádicos. Por eso limito deliberadamente los tiempos de inactividad, establezco límites claros y mantengo la contraparte (clientes, proxies) a la vista.

HTTP Keep-Alive frente a TCP Keepalive
Hago una distinción estricta entre HTTP Keep-Alive (conexiones persistentes a nivel de aplicación) y el mecanismo TCP „keepalive“. HTTP Keep-Alive controla si otras solicitudes HTTP se ejecutan a través del mismo socket. TCP Keepalive, por otro lado, envía paquetes de prueba a intervalos largos para detectar terminales „muertos“. Para el ajuste del rendimiento, lo que cuenta principalmente es HTTP Keep-Alive. Utilizo TCP Keepalive específicamente para largos periodos de inactividad (por ejemplo, en conexiones periféricas o en redes empresariales con cortafuegos agresivos), pero establezco los intervalos de forma defensiva para no generar una carga de red innecesaria.
Casos especiales: Long Polling, SSE y WebSockets
Las transmisiones de larga duración (eventos enviados por el servidor), el sondeo largo o los WebSockets entran en conflicto con los tiempos de espera de inactividad cortos. Separo estos puntos finales de las rutas estándar de API o de activos, les asigno tiempos de espera más largos y grupos de trabajadores dedicados, y limito las transmisiones simultáneas por IP. De este modo, las transmisiones de larga duración no bloquean los recursos para las solicitudes cortas clásicas. Para SSE y WebSockets, es mejor establecer límites claros, tiempos de espera de lectura/escritura y un intervalo de latido o ping/pong limpio que aumentar todos los tiempos de espera de forma global.
Parámetros centrales de Keep Alive en el servidor web
Casi siempre activo Keep-Alive, establezco un tiempo de espera de inactividad breve y limito el número de solicitudes por conexión para ahorrar recursos. reciclar. Además, regulo los grupos de trabajadores/subprocesos para que las conexiones inactivas no ocupen demasiados procesos. La siguiente tabla muestra las directivas típicas, los propósitos y los valores iniciales que utilizo habitualmente en la práctica. Los valores varían según la aplicación y el perfil de latencia, pero proporcionan una base sólida para las primeras pruebas. A continuación, voy ajustando gradualmente los tiempos de espera, los límites y Hilos basándose en datos de medición reales.
| Servidor/Componente | directiva | Propósito | valor inicial |
|---|---|---|---|
| Apache | KeepAlive | Activar conexiones persistentes | En |
| Apache | Tiempo de espera de KeepAlive | Tiempo de inactividad hasta el final de la conexión | 5-15 s |
| Apache | MaxKeepAliveRequests | Solicitudes máximas por conexión | 100-500 |
| Nginx | tiempo de espera de keepalive | Tiempo de inactividad hasta el final de la conexión | 5-15 s |
| Nginx | keepalive_requests | Solicitudes máximas por conexión | 100 |
| HAProxy | opción http-keep-alive | Permitir conexiones persistentes | activo |
| Núcleo/SO | somaxconn, tcp_max_syn_backlog | Colas para conexiones | adaptado al tráfico |
| Núcleo/SO | Límites FD (ulimit -n) | Archivos abiertos/sockets | >= 100k con mucho tráfico |
Apache: valores iniciales, MPM y control de trabajadores
Para sitios muy paralelos, utilizo el MPM en Apache. evento, porque gestiona las conexiones Idle-Keep-Alive de forma más eficiente que el antiguo prefork. En la práctica, suelo elegir entre 5 y 15 segundos para KeepAliveTimeout, de modo que los clientes puedan agrupar recursos sin bloquear a los trabajadores durante mucho tiempo. Con MaxKeepAliveRequests 100-500, fuerzo un reciclaje moderado, lo que evita fugas y suaviza los picos de carga. Reduzco el tiempo de espera general a 120-150 segundos para que las solicitudes atascadas no ocupen procesos. Si profundizas en los hilos y procesos, encontrarás información importante sobre Configuración del grupo de subprocesos para diferentes servidores web.
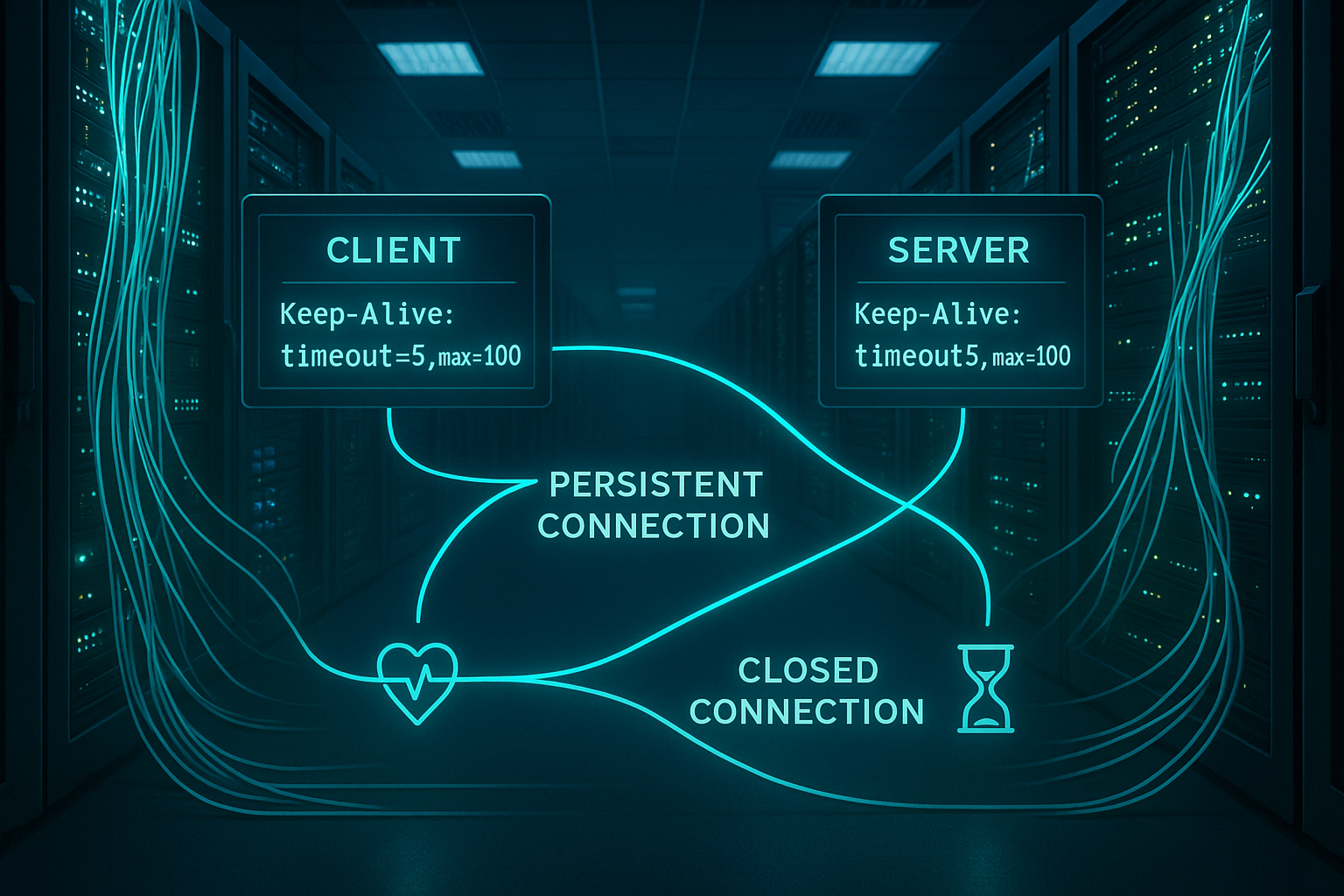
Nginx y HAProxy: patrones prácticos y antipatrones
En los proxies inversos, suelo observar dos errores: o bien se desactiva Keep-Alive de forma global por „motivos de seguridad“ (lo que provoca una carga masiva de handshake), o bien los tiempos de espera de inactividad son elevados, mientras que el tráfico es escaso (lo que consume recursos). Considero que los tiempos de espera del frontend deben ser más cortos que los del backend, para que los proxies puedan permanecer abiertos incluso cuando los clientes cierran la conexión. Además, separo los grupos ascendentes por clases de servicio (activos estáticos frente a API), ya que su secuencia de solicitudes y su tiempo de inactividad dependen del perfil. También es fundamental que sea correcto Longitud del contenido/Codificación de transferencia-Manejo: las indicaciones de longitud erróneas impiden la reutilización de la conexión y provocan „connection: close“, lo que da lugar a nuevas conexiones innecesarias.
Nginx y HAProxy: cómo utilizar correctamente los grupos ascendentes
Con Nginx, me ahorro muchos handshakes cuando mantengo abiertas las conexiones ascendentes a los backends y utilizo keepalive Ajusto los tamaños de los grupos. Esto reduce las configuraciones TLS en los servidores de aplicaciones y disminuye significativamente la carga de la CPU. Observo el número de sockets ascendentes abiertos, las cuotas de reutilización y las distribuciones de latencia en los registros para aumentar o reducir los tamaños de los grupos de forma específica. En el lado del kernel, aumento los límites de FD y ajusto somaxconn y tcp_max_syn_backlog para evitar que las colas se desborden. De este modo, el proxy sigue siendo receptivo bajo un alto paralelismo y distribuye el tráfico de manera uniforme entre los Backends.
Optimización TLS y QUIC para reducir la sobrecarga
Para que Keep-Alive despliegue todo su potencial, optimizo la capa TLS: TLS 1.3 con reanudación (tickets de sesión) acorta los handshakes, OCSP-Stapling acorta las comprobaciones de certificados y una cadena de certificados optimizada reduce los bytes y la CPU. Solo utilizo 0-RTT para solicitudes idempotentes y con precaución, para evitar riesgos de repetición. Con HTTP/3 (QUIC), esto es tiempo de inactividad Decisivo: si es demasiado alto, el almacenamiento cuesta demasiado; si es demasiado bajo, las transmisiones se interrumpen. También pruebo cómo ventana de congestión inicial y los límites de amplificación afectan a las conexiones frías, especialmente a largas distancias.
Uso específico de HTTP/2, HTTP/3 y multiplexing
HTTP/2 y HTTP/3 agrupan muchas solicitudes en una sola conexión y eliminan Cabecera de líneaBloqueo a nivel de aplicación. Esto beneficia aún más a Keep-Alive, ya que se crean menos conexiones. En mis configuraciones, me aseguro de configurar las prioridades y el control de flujo de manera que los activos críticos se ejecuten primero. También compruebo si la fusión de conexiones tiene sentido, por ejemplo, cuando varios nombres de host utilizan el mismo certificado. Echa un vistazo a HTTP/3 frente a HTTP/2 Ayuda a seleccionar el protocolo adecuado para los perfiles de usuario globales.

Clientes y pilas de aplicaciones: configurar correctamente el agrupamiento
El lado del cliente y de la aplicación también determina la reutilización: en Node.js, activo para HTTP/HTTPS el keepAlive-Agente con un número limitado de sockets por host. En Java, configuro tamaños de pool y tiempos de espera de inactividad razonables en HttpClient/OkHttp; en Go, ajusto MaxIdleConns y MaxIdleConnsPerHost Los clientes gRPC se benefician de conexiones largas, pero yo defino intervalos de ping y tiempos de espera de keepalive para que los proxies no saturen. La consistencia es importante: las reconexiones de clientes demasiado agresivas socavan cualquier optimización del servidor.
Pruebas de carga y estrategia de medición
Girar a ciegas en los tiempos muertos rara vez da resultados estables. Resultados, por lo que realizo mediciones sistemáticas. Simulo rutas de usuario típicas con muchos archivos pequeños, un grado de paralelización realista y una latencia distribuida geográficamente. Mientras tanto, registro las tasas de reutilización, la duración media de la conexión, los códigos de error y la relación entre los sockets abiertos y el número de trabajadores. A continuación, varío KeepAliveTimeout en pequeños pasos y comparo las curvas de los tiempos de respuesta y el consumo de CPU. Solo cuando las métricas se mantienen estables durante varias ejecuciones, transfiero los valores a la Producción.
Observabilidad: ¿qué métricas cuentan?
Superviso indicadores concretos: nuevas conexiones por segundo, relación reutilización/reconstrucción, handshakes TLS por segundo, sockets abiertos y su tiempo de permanencia, percentiles 95/99 de latencia, distribución de códigos de estado (incluidos 408/499), así como estados del kernel como TIME_WAIT/FIN_WAIT2. Los picos en los handshakes, el aumento de los 499 y el crecimiento de los buckets TIME_WAIT suelen indicar tiempos de espera de inactividad demasiado cortos o pools demasiado pequeños. Una lógica bien instrumentada hace que el ajuste sea reproducible y evita que las optimizaciones solo proporcionen efectos placebo.

Coordinación del tiempo de espera entre el cliente y el servidor
Los clientes deben cerrar las conexiones inactivas un poco antes que el servidor para evitar que se produzcan „muertos“.“ Enchufes Por lo tanto, en las aplicaciones frontend establezco tiempos de espera de cliente HTTP más bajos que en el servidor web y documento estos requisitos. Lo mismo se aplica a los equilibradores de carga: su tiempo de espera de inactividad no debe ser inferior al del servidor. También vigilo los valores de inactividad de NAT y del cortafuegos para que las conexiones no se pierdan en la ruta de red. Esta interacción limpia evita reinicios esporádicos y estabiliza Retransmisiones.
Resistencia y seguridad bajo carga
Las conexiones persistentes no deben ser una invitación para Slowloris & Co. Establezco tiempos de espera cortos para la lectura de encabezados y cuerpos, limito el tamaño de los encabezados, restrinjo las conexiones simultáneas por IP y me aseguro de que haya contrapresión en los upstreams. En caso de errores de protocolo, cierro las conexiones de forma sistemática (en lugar de mantenerlas abiertas) y evito así el contrabando de solicitudes. Además, defino gracia-Tiempos de cierre, para que el servidor termine correctamente las respuestas abiertas sin que las conexiones permanezcan eternamente en persistente-condiciones.
Factores de alojamiento y arquitectura
CPU potentes, NIC rápidas y suficiente RAM Aceleran los handshakes, los cambios de contexto y el cifrado, lo que permite aprovechar al máximo el ajuste de Keep-Alive. Un proxy inverso delante de la aplicación simplifica la descarga, centraliza los tiempos de espera y aumenta la tasa de reutilización de los backends. Para tener más control sobre TLS, el almacenamiento en caché y el enrutamiento, apuesto por una clara Arquitectura de proxy inverso. Sigue siendo importante eliminar pronto límites como ulimit -n y las colas de aceptación para que la infraestructura pueda soportar un alto grado de paralelismo. Con una observabilidad limpia, puedo detectar los cuellos de botella más rápidamente y puedo Límites Apriételo bien.

Implementaciones, drenaje y sutilezas del sistema operativo
En las implementaciones continuas, dejo que las conexiones Keep-Alive expiren de forma controlada: ya no acepto nuevas solicitudes, pero las existentes pueden atenderse brevemente (drenaje). De este modo, evito interrupciones de conexión y picos 5xx. A nivel del sistema operativo, vigilo el intervalo de puertos efímeros., somaxconn, SYN-Backlog y tcp_fin_timeout, sin utilizar ajustes obsoletos como la reutilización agresiva de TIME_WAIT. SO_REUSEPORT Lo distribuyo entre varios procesos de trabajo para reducir la concurrencia de aceptación. El objetivo es siempre: gestionar de forma estable muchas conexiones de corta duración sin acumularse en las colas del núcleo.
Resumen: El tuning como palanca de rendimiento
El uso sistemático de HTTP Keep-Alive reduce el número de conexiones establecidas y disminuye la Carga de la CPU y respuestas notablemente más rápidas. Los tiempos de espera cortos, los límites claros por conexión y los trabajadores suficientemente dimensionados controlan los sockets inactivos. Con HTTP/2/3, grupos ascendentes y límites del sistema operativo coordinados, escalo la paralelidad sin perder estabilidad. Las pruebas de carga realistas muestran si los ajustes realmente funcionan y dónde se encuentran los siguientes puntos porcentuales. Quien combine estos componentes aumentará el rendimiento, mantendrá bajas las latencias y aprovechará los recursos disponibles. Recursos al máximo.


