
Le débogage actif oblige WordPress à effectuer des écritures supplémentaires à chaque appel, ce qui TTFB et augmente sensiblement la charge du serveur. Dès que des centaines de notes, d'avertissements et d'avis deprecated arrivent par requête, la charge de travail augmente. debug.log rapide et le site réagit avec lenteur.
Points centraux
- Charge d'écriture grandit : chaque erreur atterrit dans debug.log et génère un overhead I/O.
- E_ALL actif : les notices et les avis deprecated gonflent le logging.
- Productif risqué : la vitesse baisse, des informations sensibles se retrouvent dans le fichier journal.
- Mise en cache limité : l'overhead est généré par requête, le cache n'aide pas beaucoup.
- Rotation nécessaire : les logs volumineux ralentissent et consomment de la mémoire.
Pourquoi le débogage actif ralentit WordPress
Chaque requête déclenche, si l'option wordpress debug logging trois tâches à effectuer : Saisir les erreurs, formater les messages et les écrire sur le disque dur. Cette chaîne prend du temps, car PHP doit d'abord générer le contenu du message, puis l'enregistrer de manière synchrone dans le fichier de données. debug.log doit être stockée. En particulier avec de nombreux plugins, les notes s'accumulent, ce qui fait que chaque page génère soudain des centaines d'écritures. Le fichier augmente rapidement de plusieurs dizaines de mégaoctets par jour, ce qui ralentit les accès aux fichiers. Je vois alors le TTFB et le temps de chargement total augmenter, bien que rien n'ait été modifié au niveau du thème ou du cache.

Comprendre les niveaux d'erreur : E_ALL, Notices et Deprecated
Avec WP_DEBUG sur true, WordPress augmente le rapport d'erreur à E_ALL, ce qui fait que même les notes inoffensives se retrouvent dans le journal. Ce sont justement ces notices et avertissements deprecated qui semblent inoffensifs, mais qui augmentent énormément la fréquence des logs. Chaque message déclenche un accès en écriture et coûte de la latence. Si vous voulez savoir quels niveaux d'erreur entraînent quelle charge, vous trouverez des informations sur les points suivants Niveaux d'erreur PHP et performance. Je réduis donc temporairement le volume, filtre les bruits inutiles et raccourcis ainsi la durée de l'enregistrement. Intensité d'écriture par requête.
Taille des fichiers, TTFB et charge du serveur : l'effet domino
Dès que debug.log atteint plusieurs centaines de mégaoctets, l'agilité du système de fichiers diminue. PHP vérifie, ouvre, écrit et ferme le fichier sans arrêt, ce qui augmente le TTFB et le temps de réaction du backend. De plus, le CPU formate les messages, ce qui pèse lourd en cas de trafic élevé. Les E/S deviennent un goulot d'étranglement car de nombreuses petites écritures de sync Latence dominent les autres. Sur les hébergements partagés, cela fait grimper le load-average jusqu'à ce que même le backend paraisse inerte.
Déclencheurs typiques : plugins, WooCommerce et trafic élevé
Les boutiques et les magazines avec beaucoup d'extensions produisent rapidement de très nombreuses Avis. Une configuration WooCommerce avec 20 extensions peut déclencher des dizaines de milliers d'entrées par jour, ce qui fait gonfler le fichier journal en peu de temps. Si le trafic augmente, le flux de messages augmente au même rythme. Chaque appel de page réécrit, même si la sortie frontale est mise en cache, car la journalisation a lieu avant la sortie du cache. Dans de tels cas, je vois des pics de temps de chargement et des tâches cron qui s'effondrent, car E/S disque bloqué en permanence.
les environnements de production : perte de vitesse et fuite d'informations
Sur les systèmes live, je suis coincé Débogage immédiatement dès que l'analyse des erreurs se termine. Les journaux de débogage révèlent les chemins d'accès aux fichiers, les détails des requêtes et donc des informations potentiellement sensibles. De plus, le temps de réaction diminue sensiblement, car chaque visiteur réel déclenche à nouveau des lignes de log. Si l'on veut procéder de manière approfondie, il faut examiner les alternatives et les directives pour le Mode de débogage en production. Je m'en tiens à des fenêtres d'analyse courtes, j'efface les anciens journaux et je protège le fichier contre toute utilisation non autorisée. Accès.
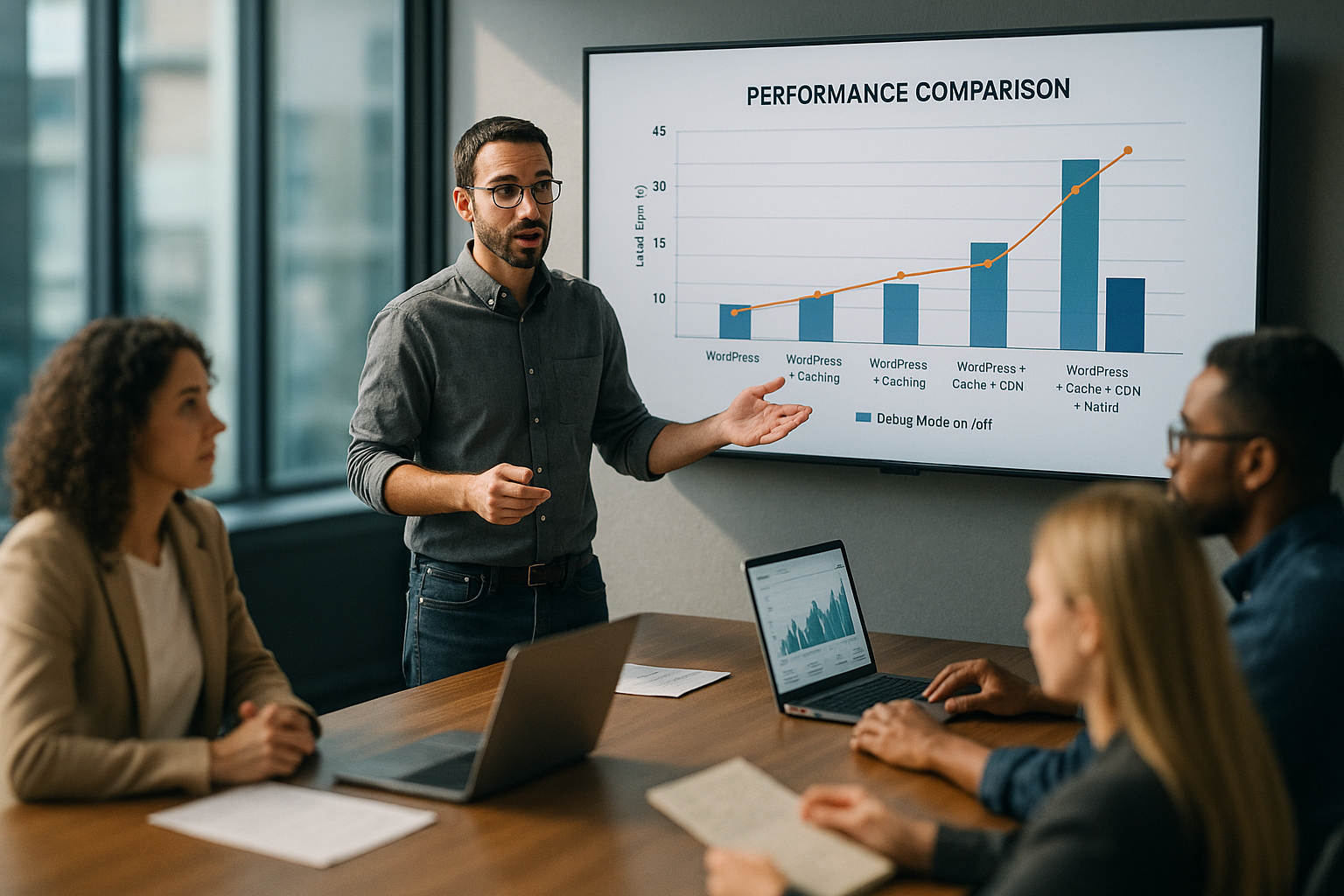
Comparaison des valeurs mesurées : sans vs. avec débogage
Le ralentissement est facile à mesurer, car le TTFB et la charge du serveur se déplacent clairement sous débogage. Sans logging actif, je mesure souvent des temps de réponse courts qui augmentent sensiblement avec le logging. Cela ne concerne pas seulement les vues frontales, mais aussi les actions admin, les appels AJAX et les points de terminaison REST. Même si le contenu est statique et provient du cache, la surcharge de journalisation ralentit la requête. Dans le tableau suivant, je résume les cas typiques Tendances ensemble.
| Facteur de performance | Sans débogage | Avec enregistrement de débogage |
|---|---|---|
| TTFB (ms) | ≈ 200 | ≈ 1500+ |
| Charge du serveur | Faible | Haute |
| Taille du journal (par jour) | 0 MO | 50-500 MO |
Ces fourchettes reflètent des observations courantes et montrent comment wp slow debug est créée. Pour ce faire, j'évalue les traces APM, les Page-Timings et les statistiques du serveur. En outre, je consulte le profilage du système de fichiers afin de mettre en évidence les amplitudes d'écriture. Le schéma est clair : plus de messages entraînent une plus grande part d'E/S dans la requête. Au total, la latence augmente, bien que le code PHP lui-même soit soi-disant plus rapide. égal à reste.

Pourquoi la mise en cache n'est pas très utile contre l'overhead
Les caches de pages et d'objets réduisent le travail de PHP, mais le logging fait feu avant et à côté. Chaque notice crée un nouveau Write-que la réponse HTML provienne ou non du cache. Par conséquent, le TTFB et la réponse du backend restent élevés malgré la mise en cache. J'utilise quand même le cache, mais je n'en attends pas de miracle tant que le débogage reste actif. Pour un véritable soulagement, c'est l'arrêt de la source qui compte, pas le masquage par Cache.
Activer en toute sécurité et désactiver encore plus rapidement
J'active la journalisation de manière ciblée, je travaille de manière focalisée et je la désactive immédiatement après l'analyse. Je le place ainsi dans le fichier wp-config.php et je tiens la sortie éloignée du front-end :
define('WP_DEBUG', true) ;
define('WP_DEBUG_LOG', true) ;
define('WP_DEBUG_DISPLAY', false) ;
@ini_set('display_errors', 0) ;
Ensuite, j'examine les pages consultées pertinentes, j'isole la source et je place des WP_DEBUG à nouveau à false. Enfin, je supprime un debug.log gonflé pour que le serveur ne jongle plus avec des données mortes. Cette discipline permet de gagner du temps et de préserver Performance dans la vie quotidienne.

Rotation des logs et soins : petits pas, grands effets
Sans rotation, la croissance debug.log jusqu'à ce que les accès en écriture s'emballent. Je mets donc en place une compression quotidienne et supprime les anciens fichiers après un court délai. Cette étape simple réduit considérablement les E/S, car le fichier journal actif reste petit. En outre, je filtre les Notice-Rauscher typiques à l'aide de Regex afin d'atténuer le flot. Si l'on veut aller plus loin, on peut aussi vérifier les niveaux d'erreur PHP et les gestionnaires d'erreur pour voir s'il y a des erreurs. Granularité.
Lire les erreurs en toute sécurité : Protection contre les regards indiscrets
Les journaux de débogage ne doivent pas être accessibles au public, sinon les chemins d'accès et les clés tombent entre des mains étrangères. Je verrouille le fichier dans le Webroot de manière conséquente, par exemple via .htaccess :
Ordre Allow,Deny
Deny from all
Sur NGINX, je définis des règles équivalentes afin qu'aucun téléchargement direct ne soit possible. En outre, je définis des droits de fichiers restrictifs afin de limiter les accès au strict nécessaire. La sécurité prime sur le confort, car les logs en révèlent souvent plus qu'on ne le pense. Des intervalles de contrôle courts et des journaux bien rangés réduisent la surface d'attaque. petit.

Trouver la source de l'erreur : Outils et procédure
Pour limiter le champ d'action, j'utilise la désactivation progressive des plug-ins et une approche ciblée. Profilage. Pendant ce temps, j'évalue les lignes de logs à l'aide de tail et de filtres afin d'identifier rapidement les messages les plus bruyants. Pour une analyse plus approfondie, j'utilise Pratique de Query Monitor, pour suivre les hooks, les requêtes et les appels HTTP. En parallèle, je mesure le TTFB, le temps PHP et la durée de la base de données, de sorte que je puisse identifier clairement le goulot d'étranglement. Ce n'est qu'une fois la source identifiée que je réactive le plugin ou que j'adapte le code pour qu'il n'y ait pas d'erreur. Bruit reste.
Choisir judicieusement les ressources d'hébergement
Sur du matériel de stockage lent, le débogage est particulièrement sensible, car chaque Write-prend plus de temps. Je mise donc sur des E/S rapides, des réserves de CPU suffisantes et des limites appropriées pour les processus. Cela implique une bonne configuration de PHP Worker et une séparation nette entre le staging et le live. Celui qui utilise le staging teste les mises à jour sans pics de charge et peut activer un logging bruyant en toute bonne conscience. Plus de headroom aide certes, mais je résous la cause pour que WordPress puisse fonctionner sans Freins est en cours.
Ajustement fin des paramètres WP et PHP
J'utilise des vis de réglage supplémentaires dans le wp-config.php pour contrôler précisément le volume et minimiser les effets secondaires :
// Replier le chemin d'accès : Log en dehors du webroot
define('WP_DEBUG_LOG', '/var/log/wp/site-debug.log') ;
// Augmenter le volume temporairement seulement, puis le baisser à nouveau
@ini_set('log_errors', 1) ;
@ini_set('error_reporting', E_ALL & ~E_NOTICE & ~E_DEPRECATED & ~E_STRICT) ;
Avec un chemin dédié, je place le fichier journal en dehors du webroot et je le sépare proprement des déploiements. À propos de error_reporting j'atténue volontairement le bruit lorsque je recherche principalement des erreurs graves. Dès que je passe à la staging, je fais à nouveau appel à E_NOTICE et E_DEPRECATED pour traiter les charges héritées du passé.
SAVEQUERIES, SCRIPT_DEBUG et freins cachés
Certains interrupteurs ne déploient un effet de freinage puissant que lorsqu'ils sont associés. SAVEQUERIES consigne chaque requête de base de données dans des structures de mémoire PHP et augmente la charge du CPU et de la RAM. SCRIPT_DEBUG oblige WordPress à charger des assets non minifiés ; bon pour l'analyse, mais pire pour le temps de chargement. Je n'active ces commutateurs que dans des fenêtres de temps très limitées et exclusivement dans des environnements de staging. En outre, je définis WP_ENVIRONMENT_TYPE (par exemple “staging” ou “production”) afin de contrôler de manière conditionnelle le comportement dans le code et d'éviter les configurations erronées.
Facteurs liés au serveur : PHP-FPM, stockage et file locks
Au niveau du serveur, je décide beaucoup de l'impact perceptible : les pools PHP-FPM avec trop peu de travailleurs accumulent les requêtes, tandis que les pools surdimensionnés augmentent la concurrence des E/S. Je place des pools séparés par site ou route critique (par ex. /wp-admin/ et /wp-cron.php) afin de désamorcer les collisions entre la journalisation et le travail de backend. Du côté du stockage, les volumes NVMe locaux sont nettement plus performants que les systèmes de fichiers réseau plus lents, où les blocages de fichiers et la latence multiplient l'effet de la journalisation. Avec le slowlog de PHP-FPM, j'identifie les goulots d'étranglement causés par les fréquents error_log()-Il n'y a pas d'appels ou de temps d'attente de verrouillage.
Déchargement : syslog, journald et remote-shipping
Si je ne peux pas désactiver complètement le logging, je décharge le disque dur en le délestant. PHPs error_log peut envoyer des messages à Syslog, qui sont ensuite mis en mémoire tampon et traités de manière asynchrone. Cela réduit l'amplitude d'écriture des fichiers locaux, mais déplace l'effort sur le sous-système de log. Il est important de limiter le taux, sinon je ne fais qu'échanger le goulot d'étranglement. Pour les tests courts, je préfère les fichiers locaux (meilleur contrôle), pour les analyses plus longues, de courtes phases de déchargement avec une limite de déconnexion claire.
Fenêtre de débogage ciblée par plug-in MU
Je limite le débogage à moi-même ou à une plage horaire pour éviter le bruit des utilisateurs productifs. Un petit plugin MU active le débogage uniquement pour les administrateurs d'une IP spécifique ou d'un cookie :
<?php
// wp-content/mu-plugins/targeted-debug.php
if (php_sapi_name() !== 'cli') {
$allow = isset($_COOKIE['dbg']) || ($_SERVER['REMOTE_ADDR'] ? ? '') === '203.0.113.10' ;
if ($allow) {
define('WP_DEBUG', true) ;
define('WP_DEBUG_LOG', '/var/log/wp/site-debug.log') ;
define('WP_DEBUG_DISPLAY', false) ;
@ini_set('log_errors', 1) ;
@ini_set('error_reporting', E_ALL) ;
}
}
Ainsi, je ne consigne que mes propres reproductions et j'épargne le reste des visiteurs. Une fois terminé, je supprime le plugin ou le cookie.
La rotation dans la pratique : robuste et sûre
Je fais tourner les logs avec des règles compactes et je veille à ce que les descripteurs de fichiers soient ouverts. copytruncate est pratique si le processus ne rouvre pas le fichier ; sinon, j'utilise create et des signaux à PHP-FPM pour que de nouvelles entrées affluent dans le fichier frais. Exemple :
/var/log/wp/site-debug.log {
daily
rotate 7
compress
missingok
notifempty
create 0640 www-data www-data
postrotate
/usr/sbin/service php8.2-fpm reload >/dev/null 2>&1 || true
endscript
}
De plus, je garde le fichier journal actif petit (<10-50 Mo), car les recherches courtes, les greps et les tails s'exécutent sensiblement plus vite et génèrent moins de cascades d'échecs de cache dans le système de fichiers.
WooCommerce et journalisation spécifique au plugin
Certains plugins ont leurs propres loggers (par ex. WooCommerce). J'y règle les seuils sur “error” ou “critical” et désactive les canaux “debug” en production. Cela réduit double journalisation (WordPress et plugin) et préserve les E/S. Si je soupçonne une erreur dans le plugin, j'augmente le niveau de manière ciblée et le réinitialise ensuite immédiatement.
Multisite, staging et conteneurs
Dans les configurations multi-sites, WordPress regroupe par défaut les messages dans une page commune. debug.log. Je les répartis volontairement par site (chemin d'accès propre à chaque ID de blog), afin que certains sites “bruyants” ne ralentissent pas les autres. Dans les environnements de conteneurs, j'écris temporairement après /tmp (rapide), j'archive de manière ciblée et je rejette les contenus lors de la reconstruction. Important : même si le système de fichiers est rapide, la charge CPU du formatage persiste - je continue donc à éliminer la cause.
Stratégie de test : mesurer proprement au lieu de se perdre en conjectures
Je compare des requêtes identiques avec et sans logging dans des conditions stabilisées : même échauffement du cache, mêmes workers PHP-FPM, charge identique. Ensuite, je mesure le TTFB, le temps PHP, le temps DB et le temps d'attente I/O. En outre, je fais tourner des tests de charge pendant 1 à 5 minutes, car l'effet des grands logs et de la concurrence des locks n'est visible que sous écriture continue. Ce n'est que lorsque les mesures sont cohérentes que j'en déduis des mesures.
Protection des données et conservation
Les logs contiennent rapidement des données personnelles (p. ex. paramètres de requête, adresses e-mail dans les requêtes). Je les conserve au minimum, les anonymise lorsque c'est possible et les supprime systématiquement une fois terminés. Pour les équipes, je documente l'heure de début et de fin de la fenêtre de débogage afin que personne n'oublie de retirer le logging. Je limite ainsi les risques, les besoins de stockage et les frais généraux.
En bref
Actif Journalisation de débogage ralentit WordPress parce que chaque requête déclenche des écritures et des mises en forme qui augmentent le TTFB et la charge du serveur. J'active la journalisation de manière ciblée, je filtre les messages, je fais tourner le fichier journal et je bloque debug.log contre les accès. Dans les environnements productifs, la journalisation reste l'exception, tandis que la staging est la règle. La mise en cache atténue les symptômes, mais n'élimine pas l'overhead par requête. En éliminant systématiquement les causes, on assure la vitesse, on économise des ressources et on maintient la performance wordpress durablement élevé.


