 Passer au contenu
Passer au contenu 
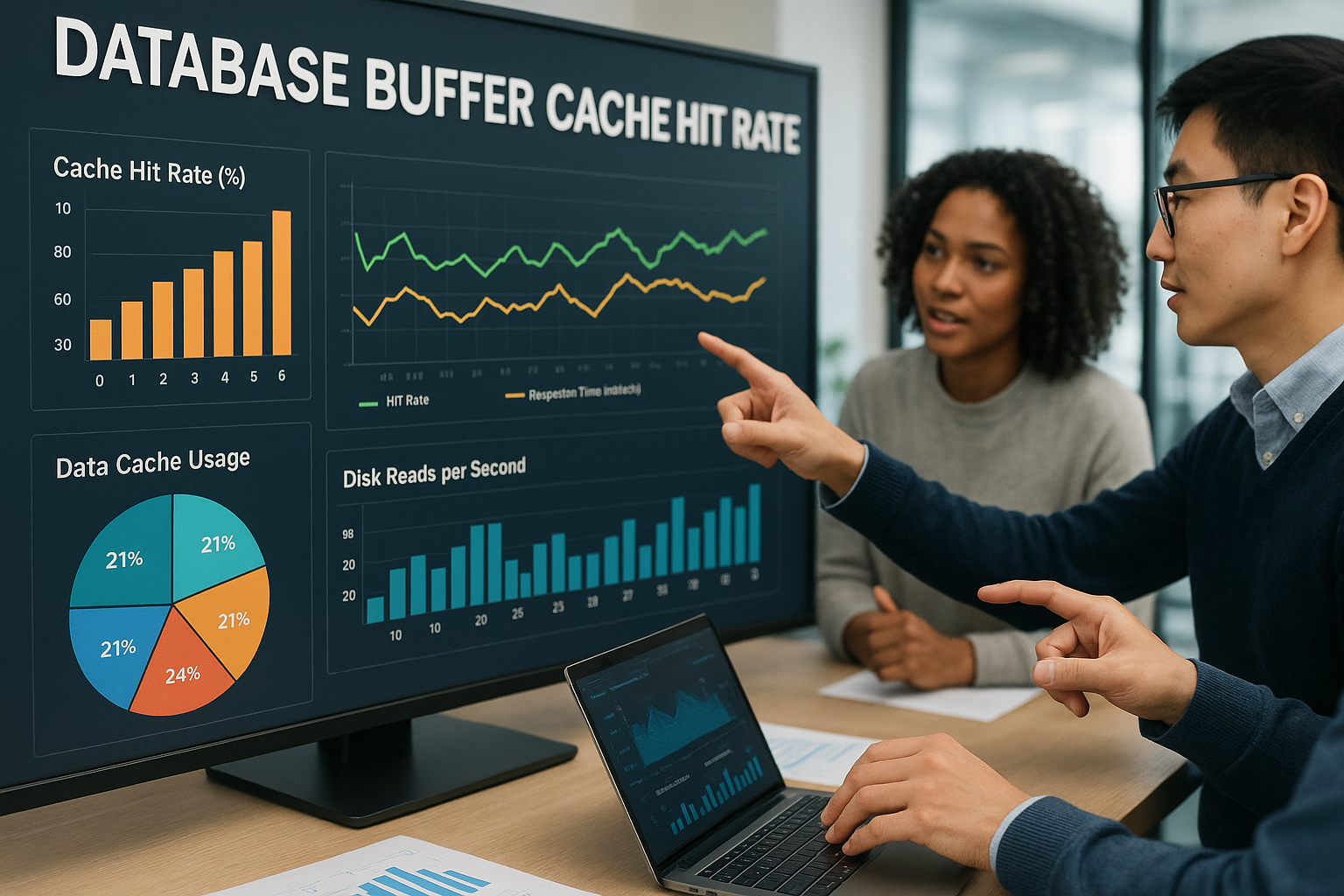
J'explique comment buffer cache hit rate correctement calculé, classé et augmenté de manière ciblée afin que les requêtes avec moins d'E/S physiques réagissent plus rapidement. Je montre ainsi des étapes concrètes pour réduire le taux d'erreur perçu. Performance de manière mesurable - y compris des métriques comme ESTD_PCT_OF_DB_TIME_FOR_READS et des valeurs limites proches de la pratique.
Points centraux
- Classement au lieu de la fixation à 99 % : toujours coupler le hit rate avec la part de temps de lecture
- Mémoire comme levier : augmenter progressivement la taille du cache, éviter le swapping
- Charge de travail-Vue : évaluer l'OLTP différemment du DWH/reporting
- Suivi structurer les données : Requêtes, latences d'E/S, temps de base de données en vue
- MySQL et Oracle : Planifier le buffer pool/cache de manière ciblée

Que signifie réellement le Buffer Cache Hit Rate ?
Le Buffer Cache conserve les blocs de données fréquemment utilisés dans la RAM, ce qui permet d'effectuer des requêtes lors d'un Hit sans accès lent au disque. Chaque requête vérifie d'abord le cache ; seul un Miss oblige à utiliser des E/S physiques. Le hit rate résulte de (lectures logiques - lectures physiques) / lectures logiques et décrit la répartition entre les accès à la mémoire et au disque. L'expérience montre qu'une valeur élevée réduit le nombre d'E/S, mais n'explique pas automatiquement des temps de réponse courts. J'évalue donc toujours cet indicateur dans le contexte d'autres Métriques, Il s'agit d'un processus qui permet de prendre des décisions en toute connaissance de cause.
Je précise le calcul en fonction de la plateforme : dans Oracle, la formule usuelle est 1 - physical reads / (consistent gets + db block gets). Ainsi, je prends en compte aussi bien les lectures consistantes (MVCC) que les accès actuels aux blocs. Dans MySQL avec InnoDB, j'utilise 1 - Innodb_buffer_pool_reads / Innodb_buffer_pool_read_requests. Je m'explique toujours les différences entre les compteurs et les stratégies de mise en cache avant de comparer les systèmes - sinon je tire facilement des conclusions erronées.
Les limites des indicateurs et ce qui compte vraiment
Une très grande Taux de succès ne peut pas sauver les requêtes lentes si les index manquent, si les jointures sont inefficaces ou si les verrous freinent. Inversement, un taux de réussite modéré suffit si les sous-systèmes de mémoire et d'E/S fonctionnent plus rapidement ou si la charge de travail utilise de longs balayages séquentiels. J'associe donc le hit rate à la part de l'ensemble des Temps DB pour les lectures physiques, par exemple via ESTD_PCT_OF_DB_TIME_FOR_READS [1]. Dans la pratique, de bonnes Plans d'exécution des indications claires pour savoir si l'optimisation de la conception SQL apporte plus que davantage de cache. Ainsi, je fixe des priorités en fonction des données et j'évite de prendre des décisions erronées et coûteuses.
Les cas particuliers fréquents dans Oracle sont Lecture directe du chemin: Les grands scans full table ou les requêtes parallèles peuvent délibérément contourner le buffer cache. Le hit rate diminue alors visiblement, sans que cela ne constitue un véritable problème - car ces E/S sont volontaires et efficaces. C'est pourquoi j'évalue toujours le type de lectures physiques (par ex. direct path vs. buffer cache reads) avant de prendre une décision de mise à niveau à partir d'un faible taux de réussite.

Calculer et interpréter correctement le hit rate
Je calcule les Taux de succès proprement sur les compteurs connus pour les accès de lecture logiques et physiques et je compare le résultat avec les temps de réponse réels. Un échantillon à court terme peut être trompeur, c'est pourquoi je considère des fenêtres de charge typiques et des profils journaliers. Ce qui est déterminant, c'est l'ampleur des lectures physiques sur l'ensemble de la période. Temps de lecture Souvent, une légère réduction de ce pourcentage a plus d'impact qu'un point de pourcentage de taux de lecture supplémentaire. Je m'en tiens aux objectifs de charge de travail : faible part de temps de lecture à un chiffre pour OLTP, jusqu'à environ 15-20 % pour DWH [1]. Ce classement m'évite de viser 99 % alors que le système perd du temps à un tout autre endroit.
Un petit exemple de calcul illustre mon approche : si le hit rate passe de 94 à 96 %, les lectures physiques diminuent d'un bon tiers en valeur relative (de 6 à 4 % des lectures logiques). Mais si les temps de réponse ne réagissent guère, le goulot d'étranglement n'est probablement pas dû aux E/S - par exemple, le débordement de l'unité centrale par des ports coûteux ou des blocages par des verrous. En revanche, si je vois la part du temps de lecture dans le temps de la base de données passer de 18 à 11 % pour la même modification, l'effet sur l'expérience utilisateur est presque toujours perceptible.
Oracle : utiliser habilement V$DB_CACHE_ADVICE
Avec V$DB_CACHE_ADVICE, j'évalue l'impact de différents types d'erreurs. Tailles des caches sur la part du temps de la BD consacrée aux lectures [1]. J'augmente progressivement le cache et j'observe si la part estimée du temps de lecture diminue de manière régulière. Si la part reste trop élevée, même avec un cache nettement plus grand, l'actuelle Mémoire disponible est tout simplement trop juste - je prévois alors un saut plus important. Cette méthode m'évite de deviner à l'aveuglette et montre quand la mémoire est plus efficace que le réglage fin des requêtes. La mise à l'échelle pilotée par les données permet d'économiser des efforts et d'adresser les goulets d'étranglement là où ils sont mesurables.
En outre, j'intègre dans Oracle la répartition par pools (par ex. KEEP/RECYCLE) et je vérifie si les objets „chauds“ vivent dans le bon pool. Je sauvegarde les objets à haut degré de réutilisation dans le pool KEEP, tandis que les grandes analyses rarement réutilisées causent moins de dommages dans le pool RECYCLE. Je stabilise ainsi le taux de réussite pour les objets OLTP critiques, sans laisser les analyses complètes des tâches de reporting polluer excessivement le cache.
Dimensionner correctement la RAM et éviter le swapping
J'agrandis le Cache de mémoire tampon jamais de manière isolée, mais vérifie l'ensemble de la RAM physique du serveur. Si le système d'exploitation se met à swapper, les latences s'effondrent et tout gain obtenu en augmentant la mémoire cache s'évapore immédiatement. Je prévois en outre 10-15 tampons de RAM % pour que les SST ou que le buffer pool a de l'air [1]. Ensuite, je teste en mode normal, je mesure à nouveau et j'évalue les effets sur la part de temps de lecture et les temps de réponse. Cette discipline évite les régressions cycliques et assure une stabilité durable.
Dans la pratique, je fais également attention aux détails du système d'exploitation : topologie NUMA et taille des pages (HugePages pour Oracle), Transparent Huge Pages désactivé pour MySQL ainsi qu'un réglage de swappiness retenu. Dans les environnements virtuels ou conteneurisés, je vérifie les limites de cgroup et les règles d'overcommit afin que la base de données ne soit pas ralentie par des caps de mémoire externes. Ce travail de base permet d'éviter qu'un dimensionnement propre du cache n'échoue en raison d'effets évitables du système d'exploitation.
MySQL : InnoDB Buffer Pool tuning sans risque
Dans MySQL, InnoDB contrôle Pool de mémoire tampon le taux de réussite pour les pages de données et d'index, et donc le nombre de lectures physiques. Je donne la priorité à innodb_buffer_pool_size, j'observe les lectures via le schéma de performance et je contrôle la RAM, le swap et les latences d'E/S. J'effectue les modifications par étapes et je contrôle ensuite les temps de réponse au lieu de seulement les Taux de succès. Outre le pool, je veille à ce que les index soient propres, les JOINs efficaces et les schémas clairs, car moins de lectures signifie aussi moins de besoins en cache. Ceux qui souhaitent approfondir leurs connaissances trouveront sur Pool de tampons MySQL une orientation utile vers des valeurs de départ et des idées de suivi raisonnables.
Pour un réglage plus fin, je tiens compte des listes internes du buffer pool : Les nouvelles pages atterrissent d'abord dans le segment „old“, avant de passer dans le segment „young“ en cas d'accès répété. Grâce à des paramètres tels que innodb_old_blocks_pct et innodb_old_blocks_time, j'évite que les grandes analyses ne prennent la place de la zone „young“. En outre, je mets à l'échelle innodb_buffer_pool_instances en fonction de la taille totale afin de réduire la latch-contention et j'aligne la capacité d'E/S (innodb_io_capacity[_max]) sur les performances réelles du stockage. Une proportion faible et stable de pages sales (par exemple 5-15 %) et des courbes de flush régulières sont pour moi un signe de gestion saine de la mémoire tampon.
Charges de travail : OLTP vs. DWH - valeurs cibles et trade-offs
En fonction de Charge de travail j'interprète les chiffres différemment. De nombreux accès courts et aléatoires dans les systèmes OLTP profitent plus que la moyenne de hit rates élevés, car les E/S aléatoires sont chères. Les scénarios DWH ou de reporting acceptent un pourcentage de temps de lecture plus élevé tant que le débit et les accès séquentiels compensent la latence [1]. Je fixe des objectifs par application plutôt que de créer des seuils globaux partout. Le tableau suivant résume les valeurs indicatives typiques et les conseils pour que les décisions restent transparentes.
| Charge de travail | Accès typiques | Objectifs approximatifs de taux de réussite | Part du temps de la BD pour les reads | Remarque |
|---|---|---|---|---|
| OLTP | Accès courts et aléatoires | Élevé (>= 95 % est souvent utile) | Faible taux à un chiffre [1] | Indices vérifier, garder l'enregistrement actif en RAM |
| DWH/Reporting | Scans longs et séquentiels | Moyen à élevé, selon la proportion de balayage | Jusqu'à environ 15-20 % [1] | Débit et latence d'E/S critique, le cache se déplace plus rapidement |
| Mixte | Combinaison d'OLTP et de rapports | Équilibre selon le profil de charge | Entre OLTP et DWH | Disques de temps évaluer séparément, isoler les pics de charge |

Monitoring, KPIs et alertes
Je saisis régulièrement Taux de succès, les lectures physiques, les latences d'E/S et les temps de réponse des principales requêtes. Pour Oracle, j'intègre ESTD_PCT_OF_DB_TIME_FOR_READS et j'utilise des rapports internes [1]. Pour MySQL, j'évalue le schéma de performance et les variables d'état afin d'identifier les tendances. Je documente les modifications des paramètres de stockage ainsi que le moment où elles ont eu lieu, afin de pouvoir comparer proprement les causes et les effets. Je garde les alertes automatisées au plus juste et je donne la priorité aux métriques qui sont vraiment importantes. Effet sur les utilisateurs montrer.
Dans la pratique, j'ai trouvé des limites d'alerte claires et peu nombreuses : si le temps de lecture estimé dans OLTP augmente de plus de ~10 % sur plusieurs fenêtres de charge, je recherche activement des requêtes motrices. Dans MySQL, si le quotient Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests devient stable, je le corrèle avec la latence P95 des top reads et les événements I/O wait. Dans Oracle, je distingue si les lectures physiques croissantes proviennent de lectures de chemin direct - dans ce cas, la mesure est rarement „plus de cache“, mais plutôt un réglage fin SQL ou de la charge de travail.
Interaction entre la mémoire, le CPU et le stockage
Un grand Cache atteindra ses limites si les cœurs du CPU sont surchargés ou si le stockage ne fournit pas assez d'IOPS. Je vérifie donc les noyaux, la cadence et la parallélisation en même temps que le sous-système d'E/S. Les mémoires NVMe ou SSD à faible latence empêchent que les lectures physiques inévitables ne deviennent un frein. Parallèlement, je mise sur l'optimisation SQL pour que les cycles du processeur ne se transforment pas en travail inutile. Cette vision globale préserve des fausses solutions coûteuses et renforce la Balance du système.
J'accorde également une attention particulière au comportement des rafales : Des pics de courte durée dans le flux d'écriture ou lors de scans parallèles peuvent surcharger le cache de manière disproportionnée. Dans de tels cas, je lisse les charges de travail (égalisation temporelle, fenêtres de traitement par lots) ou j'isole les rapports lourds sur des instances en réplique/en lecture seule. L'objectif est de maintenir le „jeu de travail chaud“ des transactions OLTP stable dans la RAM.

Règles de décision pratiques : Quand agrandir ?
J'agrandis le Cache de mémoire tampon, Le temps de lecture de la base de données reste élevé (p. ex. > 20 % dans OLTP) ou les mêmes blocs de données sont constamment rechargés. Les corrélations avec les rapports ou les tâches par lots montrent en outre si les grandes analyses prennent le pas sur la mémoire cache. Dans ces cas-là, la RAM supplémentaire est vite rentabilisée tant que le système d'exploitation Swap tombe [1]. Pour des compléments au-delà de la mémoire principale, je jette un coup d'œil sur les Stratégies de mise en cache, J'essaie de désengorger les sentiers battus. Je documente les étapes, mesure à nouveau et enregistre les effets - la courbe d'apprentissage reste ainsi raide.
Je planifie des augmentations de cache par étapes bien mesurables (par exemple +10-20 %) et j'évalue si la part du temps de lecture diminue de manière approximativement proportionnelle. Si l'effet n'est pas au rendez-vous, je réoriente l'analyse : des index manquants, des séquences de jointure inappropriées, des lignes trop larges, des lookups de clés étrangères en cascade ou des modèles de sous-sélection sont des causes classiques qui ralentissent tout taux de réussite. Ce n'est que lorsque ces chantiers ont été abordés de manière ciblée qu'une nouvelle étape de RAM vaut la peine.
Les erreurs d'interprétation les plus fréquentes et comment les éviter
J'évite de faire une fixation sur une Nombre comme „99 % Hit Rate“, car elle induit en erreur hors contexte. Un pic à court terme ne signifie pas grand-chose ; des valeurs cohérentes sur des phases de charge typiques sont plus significatives. En outre, je veille à ne pas masquer les améliorations apportées aux requêtes par davantage de cache. Si la proportion de temps de lecture ne diminue guère malgré un cache plus important, je recherche de manière ciblée les requêtes avec une mauvaise qualité. Plan d'accès ou des index manquants. Ce n'est qu'une fois que ces chantiers ont été traités qu'il vaut la peine de faire un pas supplémentaire en ce qui concerne la taille du cache.
Un autre classique : les comparaisons entre des systèmes ayant des tailles de page totalement différentes, une compression de blocs ou différentes Lecture des actualités. Je normalise les indicateurs (par ex. les lectures par requête et les quantiles de temps de réponse) avant d'interpréter. Et je n'oublie jamais que les valeurs de cache sont „froides“ après un redémarrage ou des fenêtres de migration - c'est pourquoi j'établis des phases de mise en température définies et ne mesure qu'ensuite.

Oracle : pools Keep/Recycle, lectures directes de chemins et tailles de blocs
Dans Oracle, j'utilise également la stratégie de pool : les petites tables et les blocs d'indexation à chaud utilisés fréquemment sont parqués dans le pool KEEP, tandis que les objets volumineux et rarement réutilisés sont placés dans le pool RECYCLE, ce qui réduit la pression sur le cache par défaut. Je fais également attention à la taille des blocs (DB_BLOCK_SIZE) : les blocs plus grands peuvent favoriser les analyses DWH, les blocs plus petits aident les accès OLTP avec une sélection de points élevée. Je n'évalue pas ce choix de manière isolée, mais en tenant compte des profils d'E/S et du budget mémoire.
Je considère les Direct Path Reads comme une fonctionnalité et non comme une anomalie : si des scans complets parallèles contournent le cache, je laisse délibérément „tomber“ le hit rate tant que la part du temps de la BD reste dans les limites. Dans les modèles AWR/ASH, je reconnais si les lectures directes de chemin augmentent le débit ou si des paramètres/plans déclenchent involontairement de grands scans. Ce n'est que dans le deuxième cas que j'interviens, généralement par le biais de la conception SQL plutôt que par une mise en cache encore plus importante.
Stratégies de modèle de données et SQL pour réduire les lectures
La manière la plus efficace d'augmenter la performance perçue est d'utiliser le Besoin de Reads :
- Indices ciblés : Contrôler en permanence les indices de couverture pour les lookups critiques, la cardinalité et la sélectivité.
- Lignes plus étroitesLire uniquement les colonnes nécessaires, externaliser le TEXT/BLOB lorsque cela est pertinent.
- Partitionnement: le pruning réduit drastiquement les blocs scannés.
- Chemins d'agrégation: Structures pré-agrégées et matérialisation pour les rapports fréquents.
- Forme de la requête: prédicats sargables, ordre de jointure stable, pas de préfixes joker.
Chaque lecture évitée augmente le taux de réussite „effectif“ sans augmenter la RAM - et améliore immédiatement le temps de réponse.
Pratique : De la mesure à la décision
Ma démarche pragmatique est la suivante :
- Ligne de base créer : Hit Rate, lectures physiques, latences d'E/S, parts de temps de la BD, Top-Queries.
- Hypothèse formuler la question : Cache trop petit, plan SQL erroné, stockage limité - qu'est-ce qui est le plus probable ?
- Test ciblé: petit saut de cache ou correction de requête ; définir une fenêtre de mesure (par ex. 24-72h) et l'évaluer de manière isolée.
- Évaluer: les quantiles de temps de réponse et la proportion de temps de lecture sont mes signaux primaires, le hit rate est secondaire.
- Décider: mise à l'échelle, retour en arrière ou déplacement du focus sur SQL/Index - documenté et reproductible.
Ainsi, les optimisations restent compréhensibles et j'évite que des modifications insidieuses (par exemple de nouveaux rapports) ne déplacent l'ensemble des travaux sans que l'on s'en aperçoive.
En bref
J'évalue les Cache de mémoire tampon Ne jamais isoler le hit rate, mais le coupler avec la part de temps de la base de données pour les lectures physiques, les temps de réponse et les latences E/S. Les objectifs appropriés dépendent de la charge de travail : OLTP vise une part de temps de lecture très faible, DWH reste souvent dans la zone verte jusqu'à 15-20 % [1]. Des étapes itératives pour la taille du cache, une réserve de RAM suffisante et un monitoring propre fournissent des résultats fiables. Dans MySQL, je me concentre sur le buffer pool InnoDB et sur des index solides ; dans Oracle, j'utilise V$DB_CACHE_ADVICE pour obtenir des données fiables. Prévisions. En respectant ces règles, on réduit sensiblement les lectures physiques et on accélère les applications sans jouer aux devinettes.


