 Passer au contenu
Passer au contenu 
A Serveur de pagination en mémoire peut perdre beaucoup de temps de réponse et de débit lorsqu'il est chargé et que trop de pages passent de la RAM au swap. Dans cet article, je présente les causes, les valeurs mesurées et les leviers concrets qui me permettent d'accélérer la pagination et d'augmenter sensiblement les performances du serveur.
Points centraux
Pour une orientation claire, je résume brièvement les messages clés et montre où se situent les goulets d'étranglement typiques et comment je les résous. Des taux de pagination élevés coûtent cher Performance, parce que les accès aux disques sont beaucoup plus lents que la RAM. Les mesures telles que les Mo disponibles, les octets sauvegardés et les pages/seconde me fournissent des informations fiables. Signaux pour un thrashing imminent. La virtualisation aggrave les effets d'externalisation par le ballooning et le swap d'hyperviseur lorsque les hôtes sont surbookés. Je réduis les erreurs de page avec une mise à niveau de la RAM, THP/Huge Pages, NUMA-Tuning et des modèles d'allocation propres. Un monitoring régulier maintient Risques faible et permet de calculer les pics de charge.
- Swap vs RAM: nanosecondes en RAM vs. micro/millisecondes sur les supports de données
- ThrashingPlus de transferts de pages que de travail utile, les latences explosent
- Fragmentation: Les grandes allocations échouent malgré le stockage „libre
- Indicateurs: Mo disponibles, Octets sécurisés, Pages/Sec.
- Tuning: THP/Huge Pages, vm.min_free_kbytes, NUMA, RAM

Comment fonctionne la radiomessagerie sur les serveurs
Je sépare la mémoire virtuelle et la mémoire physique en pages fixes, typiquement 4 Ko, ce qui MMU par des tables de pages. Si la RAM vient à manquer, le système d'exploitation déplace les pages inactives vers des zones d'échange ou de pagination. Chaque défaut de page oblige le noyau à aller chercher des données sur le disque et coûte un temps précieux. Temps. Les grandes pages comme les Transparent Huge Pages (THP) réduisent la charge administrative et les échecs TLB. Pour les débutants, il vaut la peine de jeter un coup d'œil sur mémoire virtuelle, Les utilisateurs peuvent également utiliser le logiciel de gestion de contenu pour mieux comprendre les relations entre les processus, les cadres de page et le swap.
Swap vs RAM : latence et thrashing
La RAM répond en nanosecondes, alors que les SSD/HDD répondent en microsecondes ou en millisecondes, ce qui représente des ordres de grandeur différents. plus lent sont en cours. Si la charge dépasse la mémoire de travail physique, le taux de pagination augmente et le CPU attend les entrées/sorties. Cet effet conduit facilement au thrashing, où plus de temps est consacré aux paginations qu'à la production. Travail est en baisse. L'interactivité et les sessions à distance se détériorent particulièrement avec une charge de 80-90%. Je vérifie les Utilisation du swap étroitement et fixe des limites avant que le système ne bascule.

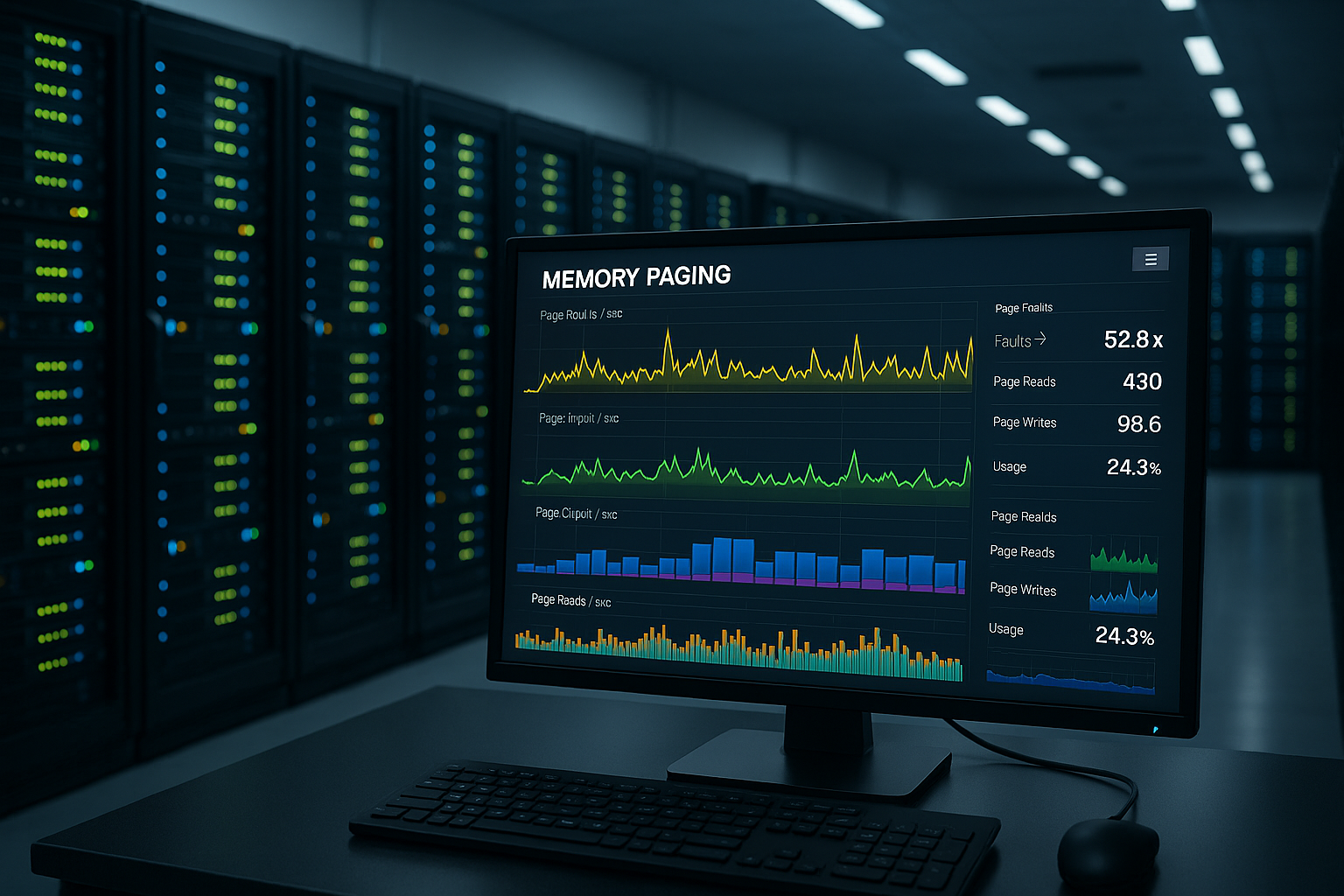
Indicateurs et seuils
Des valeurs de mesure propres rendent les décisions RAM et le réglage. Sous Windows, je surveille les Mo disponibles, %Octets sauvegardés, Pages/Seconde et Pool paged/nonpaged Bytes. Côté Linux, je vérifie vmstat, free, sar, ps meminfo et dmesg pour les événements de sortie de mémoire. Des sorties de pages croissantes alors que le nombre de Mo libres diminue indiquent des goulots d'étranglement imminents. Je planifie les seuils critiques de manière conservatrice afin d'éviter les pics de charge sans Intrusion d'intercepter.
| Indicateur de performance | Healthy | avertissement | Critique |
|---|---|---|---|
| \Memory\Pool paged octets / nonpaged octets | 0-50% | 60-80% | 80-100% |
| Mégaoctets disponibles | >10% ou 4 Go | <10% | <1% ou <500 Mo |
| % Octets garantis | 0-50% | 60-80% | 80-100% |
Linux : Swappiness, Zswap/ZRAM et paramètres de writeback
En plus de THP/Huge Pages, je diminue sensiblement le paging en contrôlant l'agressivité de l'externalisation et du writeback. vm.swappiness détermine à quel moment le noyau pousse les pages dans le swap. Sur les serveurs avec beaucoup de RAM, je vais généralement de 1 à 10 pour que le cache de pages reste grand et que les tas inactifs ne se déplacent pas trop vite. Sur les systèmes très limités, une valeur légèrement plus élevée peut sauver l'interactivité, car le cache ne s'assèche pas complètement - la mesure sous charge réelle est décisive.
Avec Zswap (swap compressé dans la RAM), je réduis la pression I/O lorsqu'il y a beaucoup de pages froides pendant une courte période. Cela coûte des cycles de CPU, mais reste souvent moins cher que les E/S en bloc. Pour les systèmes Edge ou Lab, j'utilise en partie ZRAM comme swap primaire pour rendre les petits hôtes plus robustes ; en production, je l'utilise de manière ciblée lorsque l'espace d'accueil du processeur est disponible.
Je contrôle les chemins d'écriture via vm.dirty_*-paramètres. Je préfère travailler avec des octets absolus plutôt qu'avec des pourcentages, afin d'éviter les tempêtes de writeback en cas de grandes capacités de RAM. Le flush d'arrière-plan démarre assez tôt, tandis que dirty_bytes fixe des limites supérieures strictes pour les charges de travail qui ne nécessitent pas d'écriture. Exemples de valeurs que j'utilise comme point de départ :
# swapping retenu
sysctl -w vm.swappiness=10
# Contrôle du writeback (octets au lieu de pourcentage)
sysctl -w vm.dirty_background_bytes=67108864 # 64 Mo
sysctl -w vm.dirty_bytes=268435456 # 256 Mo
# Ne pas rejeter le cache VFS de manière trop agressive
sysctl -w vm.vfs_cache_pressure=50
À l'adresse suivante : Conception de swap je privilégie les périphériques NVMe rapides et j'établis des priorités pour que le noyau utilise en premier le swap le plus rapide. Un périphérique d'échange dédié empêche la fragmentation des fichiers d'échange.
# Vérifier les priorités de swap
swapon --show
# Activer le swap sur un périphérique rapide avec une priorité élevée
swapon -p 100 /dev/nvme0n1p3
Important : j'observe les major/minor faults et la profondeur de la file d'attente d'E/S en parallèle - c'est la seule façon de savoir si la swappiness réduite ou le Zswap lisse les pics de latence réels.
Causes des taux de pagination élevés
En l'absence de mémoire de travail physique, les octets sauvegardés augmentent via la mémoire de travail intégrée. RAM et le système se tourne vers le swap. La mémoire fragmentée rend difficile les grandes allocations, de sorte que les applications se bloquent malgré la RAM „libre“. Des requêtes de mauvaise qualité ou des index manquants gonflent inutilement les accès aux données et augmentent les volumes de travail. Les charges de pointe provenant des sauvegardes, des déploiements, de l'ETL ou des tâches Cron concentrent les besoins en mémoire sur de courtes fenêtres de temps. Les machines virtuelles subissent une pression supplémentaire lorsque les hôtes surchargent la RAM et procèdent secrètement à la permutation de l'hyperviseur. activer.
Virtualisation, ballooning et overcommitment
Dans les environnements virtualisés, l'hyperviseur masque la situation réelle de la RAM et utilise le ballooning ainsi que le swapping à l'intérieur des Invités. Si l'hôte se trouve dans un goulot d'étranglement, les VM perdent simultanément de la puissance, bien que chacune d'entre elles soit „verte“. La radiomessagerie au démarrage masque les démarrages à froid, mais déplace les coûts vers le pipeline d'E/S. Je vérifie les métriques des hôtes et des invités ensemble et je réduis les surréservations avant que les utilisateurs ne remarquent quoi que ce soit. Je donne des détails sur l'effet de l'overcommit dans la section sur les Dépassement de la mémoire, La planification de la capacité doit être fiable.
Conteneurs et Kubernetes : cgroups, limites et évictions
Les conteneurs déplacent les limites de stockage de la VM à cgroups. Ce qui compte, c'est que requests et limits sont fixées de manière réaliste : Des limites trop étroites provoquent des out-of-memory-kills précoces, des requêtes trop généreuses détériorent l'utilisation et font croire à des réserves. Je maintiens les tas de JVM/Node/.NET systématiquement liés aux limites des conteneurs (par ex. heuristiques en pourcentage), afin que le Runtime-GC ne se heurte pas au cgroup.
Dans Kubernetes, je fais attention aux classes de QoS (Guaranteed, Burstable, BestEffort) et Seuils d'éviction au niveau des nœuds. Sous la pression de la mémoire, le Kubelet préfère les pods BestEffort - si l'on veut conserver les SLO, il faut budgétiser proprement les ressources. PSI (Pressure Stall Information) rend visible la pression locale du cgroup ; j'utilise ces signaux pour redimensionner ou replanifier les pods de manière proactive. Pour les charges de travail avec de grandes pages, je définis des requêtes HugePage explicites par pod afin que l'ordonnanceur choisisse des nœuds appropriés.
stratégies d'optimisation : Matériel et OS
Je commence par la vis de réglage la plus sobre : plus de RAM élimine souvent immédiatement les plus grandes latences. En parallèle, je diminue les paresses de page par THP en mode „on“ ou „madvise“, si les profils de latence le permettent. Les pages massives réservées fournissent une prévisibilité pour les moteurs en mémoire, mais nécessitent une planification précise des capacités. Avec vm.min_free_kbytes, je crée des réserves judicieuses pour faire face aux pics d'allocation sans compensation de compression. Les mises à jour du micrologiciel et du noyau éliminent les erreurs de bord, la gestion de la mémoire NUMA-La santé de l'enfant peut être perturbée.
| Réglage | Objectif | Avantages | Remarque |
|---|---|---|---|
| vm.min_free_kbytes | Réserve pour les pics d'allocation | Moins de OOM/compaction | 5-10% de la RAM |
| THP (sur/madvise) | Utiliser des pages plus grandes | Moins de fragmentation | Observer les latences |
| Pages géantes | Blocs continus | Allocations prévisibles | Réserver une capacité fixe |
Bases de données et charges de travail d'hébergement
Les bases de données souffrent rapidement lorsque le buffer cache se rétrécit et que les requêtes sont effectuées en mode "swap". E/S se noient. Un paramètre de mémoire maximale strictement limité protège SQL/NoSQL d'une éviction mutuelle avec le cache du système de fichiers. Les index, la sargabilité et les stratégies de jointure adaptées réduisent les volumes de travail et donc la pression de la RAM. Dans les configurations d'hébergement, je planifie les index de recherche, les caches et les workers PHP-FPM en cas de pics de manière à ce que les profils de charge n'entrent pas en collision. Le monitoring de l'espérance de vie de la mémoire tampon et de la page m'avertit à temps des problèmes suivants Tendances à la baisse.

Pratique : plan de mesure et feuille de route pour le tuning
Je commence par une ligne de base de 24 à 72 heures, afin que les modèles journaliers et les tâches soient visibles. seront. Ensuite, je définis un profil cible pour la tête de RAM libre, les pages/seconde acceptables et les temps d'attente E/S maximum. Ensuite, je déploie les modifications de manière incrémentielle : d'abord les limites, puis THP/Huge Pages, enfin la capacité. Je mesure chaque modification sur au moins un cycle de charge avec une méthodologie identique. Je planifie à l'avance les interruptions et les annulations afin de pouvoir réagir rapidement en cas d'effets négatifs. à réorienter.
Tests de charge reproductibles et prévisions de capacité
Pour prendre des décisions robustes, je reproduis des ensembles de travail typiques : Caches chauds/froids, fenêtres de traitement par lots, pics de connexion/checkout. Je simule la pression de la mémoire de manière ciblée à l'aide d'outils synthétiques (par exemple stress-ng pour les chemins de mémoire, fio pour les E/S et memcached/Redis-Benchmarks pour les arte-caches). J'effectue des tests en trois variantes : app seule, app + suiveurs (sauvegarde, scan AV), app + pointes I/O. Cela me permet de détecter des interférences qui restent cachées dans les tests d'apps pures.
Pour chaque modification, je collecte des panels de métriques identiques (Memory, PSI, I/O-Wait, CPU-Steal/Ready, Faults). Un déploiement Canary avec 5-10% de trafic permet de détecter les risques à un stade précoce, avant que je ne déploie la configuration à grande échelle. Pour la capacité, je planifie avec des ensembles de travail du pire cas plus une réserve - pas avec des valeurs moyennes lissées.
Dépannage : outils et signatures
Sur Linux, vmstat, sar, iostat, perf et strace me fournissent les principaux Remarques sur les défauts de page, les temps d'attente et les tas. Côté Windows, je mise sur Performance Monitor, Resource Monitor et ETW-Traces. Des messages tels que „compaction stalls“, „kswapd high CPU“ ou des OOM-kills indiquent des goulots d'étranglement importants. Une interactivité fluctuante, de longues pauses GC et des Dirty Pages croissantes confirment les soupçons. Avec les heap dumps et les profils de mémoire, je trouve des fuites et des Allocations.

Pratique spécifique à Windows : Pagefile, Working Set et Paged Pools
Sur les serveurs Windows, je sécurise un système d'exploitation suffisamment dimensionné. Fichier d'échange sur des SSD rapides et évite les configurations „pas de fichier de page“. Des tailles minimales fixes empêchent le système de se rétrécir en période de pointe et de se tronquer de manière inattendue. Si nécessaire, je répartis les fichiers de pages sur plusieurs volumes et j'observe les résultats. Hard Faults/sec ainsi que le taux d'utilisation des pools paged/nonpaged.
Pour les services nécessitant beaucoup de mémoire, j'active de manière ciblée Verrouiller des pages en mémoire (par ex. pour le serveur SQL), afin que le noyau ne pousse pas les quantités de travail hors de l'ensemble de travail. En même temps, je délimite proprement les caches d'applications pour éviter que le système ne s'assèche d'une autre manière. J'identifie les fuites de pilotes ou de pools avec PoolMon/RAMMap ; en cas de panne, une réduction contrôlée de la liste de veille aide à rétablir l'interactivité à court terme - uniquement comme diagnostic, pas comme solution permanente.
Également important : plans d'économie d'énergie sur „performance maximale“, pilotes NIC/stockage et firmware actuels. Les quirks d'ordonnancement ou les pilotes de filtrage obsolètes entraînent étonnamment souvent des pics de mémoire et d'E/S que je pourrais interpréter à tort comme une simple pénurie de RAM.
Utiliser intelligemment le THP, le NUMA et les tailles de page
Les Transparent Huge Pages réduisent la pression TLB, mais les promotions sporadiques peuvent entraîner des pics de latence. produire. Pour les charges de travail avec des SLO stricts, je mise donc souvent sur des „madvise“ ou des Huge Pages fixes. L'équilibrage NUMA est payant sur les systèmes multi-sockets lorsque les threads et la mémoire restent locaux. J'épingle les services aux nœuds NUMA et observe les taux d'échec locaux. Les grandes pages augmentent le débit, mais je vérifie la fragmentation interne afin de ne pas offre.
Cache du système de fichiers, mmap et chemins d'E/S
Une grande partie de la mémoire „libre“ se trouve dans le Cache de la page. Je décide consciemment si un moteur utilise le cache de l'OS (Buffered I/O) ou s'il le met lui-même en cache (Direct I/O). Les doubles caches gaspillent de la RAM ; si le cache du système d'exploitation n'est pas utilisé, la RAM augmente. readahead-les latences de la mémoire. Pour les charges de travail en flux, j'augmente éventuellement le Readahead par périphérique, les bases de données à charge aléatoire se comportent mieux avec Direct I/O.
# Exemple : augmenter le readahead à 256 secteurs
blockdev --setra 256 /dev/nvme0n1
E/S mappées en mémoire (mmap) préserve les copies, mais déplace la pression sur le cache de la page. Dans des cas exceptionnels, j'épingle les pages critiques avec mlock (ou memlock ulimits), afin d'éviter la gigue due au reclaim - toujours en tenant compte des réserves du système.
Mesures d'urgence rapides en cas de compression de la mémoire
- Identifier les principaux consommateurs (ps/top/procdump) et, le cas échéant, les redémarrer ou les réenregistrer.
- Ralentir temporairement la concourance (workers/threads) afin de réduire le taux de fail et le writeback.
- Abaisser les limites de dirty à court terme pour que le writeback intervienne plus tôt et libère des réserves.
- En cas d'overcommit de conteneur, évacuer les pods de manière ciblée ; dans les VM, augmenter temporairement les ressources ou assouplir le ballooning.
- Vérifier la stratégie OOM : activer systemd-oomd/earlyoom et cgroup-Les processus peuvent être réglés de manière à ce que les „bons“ processus partent en premier.
Planification des capacités et coûts
La RAM coûte de l'argent, mais les pannes répétées coûtent du chiffre d'affaires et Appel. Pour les serveurs web et de base de données, je calcule généralement 20-30% de réserve pour couvrir les rares pics. Un module supplémentaire de 64 Go pour 180-280 € est souvent amorti plus rapidement que le firefighting permanent. Dans les environnements de cloud computing, j'évite la surréservation et je réserve les tampons par étapes en fonction des modèles de charge. Les calculs sobres du coût total de possession battent les beaux diagrammes, car ils tiennent compte des dommages causés par la latence et du temps de l'opérateur. inclure.

En bref
A Serveur de pagination en mémoire bénéficie le plus de suffisamment de RAM, d'une configuration THP/Huge-Page propre et d'un overcommit réaliste. Je me fie à des indicateurs clairs tels que les Mo disponibles, les octets garantis et les pages/seconde. Je vérifie deux fois les environnements virtualisés pour m'assurer que le ballooning et le host swap ne volent pas les performances de manière cachée. Je tiens les bases de données à l'écart du swap grâce à des caches et des limites définies. En appliquant ces étapes de manière conséquente, on réduit les temps de latence, on évite le thrashing et on maintient la performance. Performance stable sur les pics de charge.


