 Ga naar de inhoud
Ga naar de inhoud 
Database checkpointing in hosting bepaalt hoe snel databases opstarten na crashes, hoe gelijkmatig de schrijfbelasting verloopt en hoeveel schrijfversterking de SSD's belasten. Ik laat je zien hoe je specifieke IO-pieken kunt afvlakken en de kosten kunt verlagen door lagere schrijfvolumes met verstandige checkpoints, slimme loginstellingen en een aangepast datamodel.
Centrale punten
De volgende kernaspecten helpen me om specifiek database checkpointing en schrijfversterking in hosting te controleren.
- Saldo bewust kiezen tussen hersteltijd en schrijfbelasting
- Parameters Fijnafstemming voor logboek, interval en vuile pagina's
- Indices verminderen en bevorderen van schrijven in batches
- Controle actief gebruik voor checkpoints en IO-pieken
- Opslag Selecteren om overeen te komen met werkbelasting
De basis kort uitgelegd
Elke database schrijft uiteindelijk naar Opslag, maar de weg daarheen is via buffers, caches en transactielogs. Ik weet dat niet elke app-schrijfopdracht meteen op de SSD terechtkomt, omdat de buffercache gewijzigde pagina's vasthoudt en pas later synchroniseert. Deze ontkoppeling beschermt IOPS, maar kan geconcentreerde schrijfgolven op het verkeerde moment genereren. Dit is precies waar checkpointing om de hoek komt kijken en bepaalt wanneer vuile pagina's consequent naar de databestanden worden verplaatst. Op bestandssysteemniveau Journaling bestandssystemen in het back-upproces, waarmee ik rekening houd in de planning.
Hoe checkpointing werkt in hosting
A Checkpoint schrijft gewijzigde pagina's op een gecontroleerde manier naar de gegevensdrager en markeert een consistente toestand. Tijdens normale activiteit domineert het schrijven van logs, maar bij het checkpoint slaat de balans voor korte tijd door in het voordeel van gegevensbestanden. Deze fase genereert zichtbare IO-pieken, die vooral op gedeelde en VPS-systemen weerklinken. Ik herken deze golven snel in de metriek en wijs ze toe aan een terugkerend plan. Als de frequentie niet overeenkomt met de werklast, worden prestaties verspild door onnodige schrijfacties en langere reactietijden.

Inzicht in schrijfversterking
Schrijfversterking beschrijft extra Schrijft, die verder gaan dan de eigenlijke app wijziging. Een enkele regelwijziging kan van invloed zijn op het gegevensbestand, het transactielogboek en verschillende indices, waardoor het effectieve schrijfvolume toeneemt. Metadata en journaling worden toegevoegd aan het bestandssysteem en de SSD-controller verergert het plaatje met afvalverzameling en slijtagenivellering. Dus een kleine update groeit snel uit tot een grote IO, die de levensduur en latentie beïnvloedt. Als je dieper op dit fenomeen wilt ingaan, kun je achtergrondinformatie vinden op de website SSD schrijfversterking rechtstreeks in de hostingcontext.
Checkpoints als versterkers van schrijfbelasting
Regelmatig controleposten verkorten de hersteltijd, maar ze bundelen veel vuile pagina's in korte, krachtige schrijfbewerkingen. Dit verhoogt het aantal fysieke schrijfbewerkingen, inclusief de neveneffecten van bestandssysteem journaling en SSD firmware. Als ik checkpoints te agressief plan, nemen de latenties en het totale aantal schrijfacties toe, waardoor de hersteltijd afneemt. Levensduur van de SSD wordt verminderd. Aan de andere kant, als ik ze te onregelmatig inzet, wordt het transactielogboek te groot en wordt de hersteltijd na een crash langer. Daarom balanceer ik het interval, de loggrootte en de duur van de voltooiing zodat belastingspieken vlakker zijn en het systeem soepel draait.

Relevante stelschroeven per database
Ik regel het gedrag via vier HendelLoggrootte, interval, voltooiingsdoel en vuile pagina quota. Veel systemen triggeren checkpoints wanneer het log een gedefinieerde vulgraad bereikt, dus ik vermijd segmenten die te klein zijn. Een duidelijk ingesteld tijdsinterval voorkomt willekeurige pieken, terwijl het voltooiingsdoel de duur rekt en zo IO afvlakt. Tegelijkertijd houd ik de vuile paginasnelheid in de gaten omdat een hoge snelheid geforceerde controlepunten veroorzaakt. De volgende tabel categoriseert typische stelschroeven en hun effect.
| stelschroef | Effect | Risico | Praktische opmerking |
|---|---|---|---|
| Log grootte | Beïnvloedt wanneer controlestations starten | Te klein: frequente pieken | Selecteer medium tot groot, houd het herstel in de gaten |
| Checkpoint interval | Definieert de basiscyclus van de spoelingen | Te kort: meer schrijfversterking | Aanpassen aan werklast en back-upvenster |
| Voltooiingsdoel | Verdeelt schrijfacties over de tijd | Te lang: doorspoelen duurt lang in fasen met hoge belasting | Plaats op rustige fasen, meet latenties |
| Vuile pagina quota | Beperkt het risico op plotselinge geforceerde spoelingen | Te laag: onnodige activiteit | Selecteer zodat de buffer productief werkt |
Praktische effecten in alledaagse hosting
Ik zie vaak korte Uitvallers voor websites die precies overeenkomen met checkpointfasen. Formulieren verzenden dan merkbaar langzamer, bestellingen hebben dat ene cruciale moment meer nodig. Als back-ups op hetzelfde moment worden gestart, nemen de latenties twee keer zo veel toe omdat de database en het back-upproces vechten om dezelfde bronnen. Op gedeelde platforms belast een ruisend systeem andere klanten, wat ik duidelijk onderscheid in meetcurves. Pas als deze patronen zichtbaar worden, voer ik gerichte wijzigingen door in parameters en planningen.
Strategieën voor het verminderen van schrijfversterking
Ik begin met de controlepostenIntervallen matig, voltooiingsdoel hoger, logsegmenten niet te klein. Op deze manier verdeel ik schrijfacties zonder het herstel onnodig te verlengen. Vervolgens verminder ik de hoeveelheid gegevens die elke wijziging beïnvloedt door onnodige Indices en de resterende afstemmen op echte queries. Batch operaties bundelen updates, wat resulteert in minder metadata verplaatsing. Archivering verplaatst koude gegevens uit de actieve werkset, waardoor het aantal pagina's per transactie wordt verminderd.
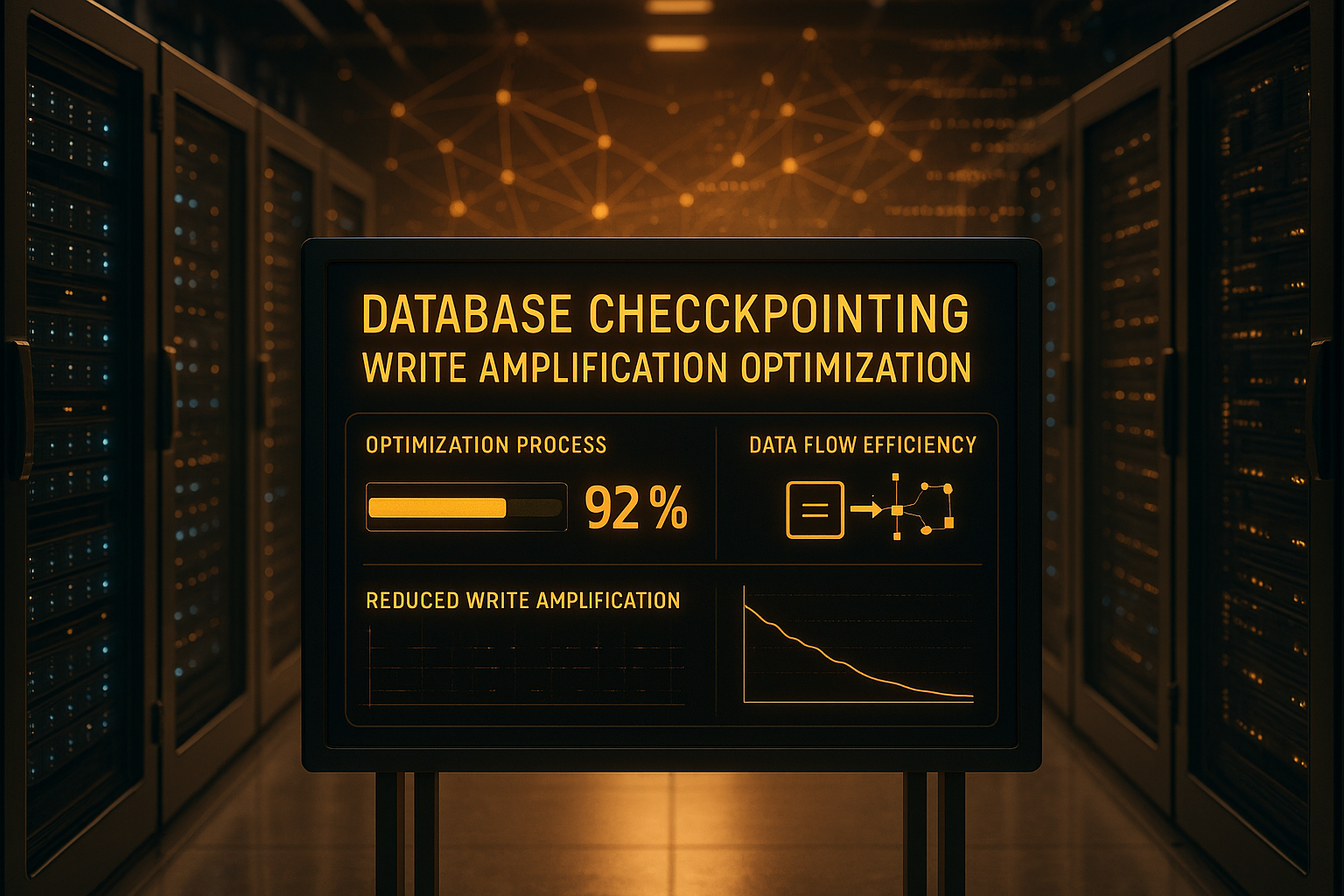
Monitoring zichtbaar maken
Zonder gemeten waarden IO in het donker, dus ik monitor continu IOPS, doorvoer en IO wachttijd. Ik gebruik checkpoint-statistieken: duur, frequentie, aantal geschreven pagina's en of er geforceerde flushes plaatsvinden. De bufferpool hitrate vertelt me of de database te vaak van schijf leest en zo extra storing genereert. Als ik externe metrieken en databaseoverzichten combineer, kan ik snel en betrouwbaar patronen herkennen. Pas dan vertaal ik bevindingen in concrete veranderingen en controleer ik het resultaat opnieuw.
Hosting selectie met IO focus
Ik let op NVMe of snelle SSD-systemen, omdat lage latencies checkpointpieken beter opvangen. Verzekerde IO-bronnen geven me planningszekerheid, vooral voor winkels en SaaS backends. Configuratievrijheden voor logs, interval en vuile pagina quota zijn veel geld waard voor data-intensieve applicaties. Voor MySQL belastingen speelt de storage-engine een grote rol. InnoDB versus MyISAM duidelijk geëvalueerd. Transparante meetgegevens in het paneel helpen me om knelpunten in een vroeg stadium te herkennen en om afstemmingsstappen precies te timen.

Het gegevensmodel en de app afstemmen
Met het datamodel richt ik me op Schrijfpaden met het hoogste volume en verwijder indexen zonder duidelijk voordeel. Elke extra index vermenigvuldigt inserts en updates, dus ik controleer regelmatig het gebruik en de kardinaliteit. Ik vertrouw op batch inserts en bulk updates omdat ze logoverhead en metadatawerk verminderen. Ik houd sessiegegevens, caches en logs buiten de hoofddatabase en verplaats ze naar systemen die daar beter geschikt voor zijn. Ik kies ook verstandige transactielimieten, omdat extreem grote of heel veel kleine transacties onnodig duur zijn.
Concrete opslagafstemming in hosting
Voor schrijfintensieve projecten scheid ik Logboeken en gegevensbestanden op verschillende volumes om de concurrentie te minimaliseren. Een schone wachtrijdiepte en voldoende IOPS-reserve zorgen ervoor dat checkpoints andere taken niet verdringen. Schrijfcaching kan veel helpen, maar ik overweeg altijd back-up via UPS, controllerbatterij of hostgaranties. Ik organiseer backup- en onderhoudsschema's zo dat ze niet botsen met checkpointfases. Dit houdt IO consistenter en elimineert dure pieken.

Op tijd gebaseerde orkestratie van werklasten
Ik ben van plan Bulkbanen in rustige tijdvensters zodat de controlepunten zich zonder concurrentie kunnen ontvouwen. Ik voer importgolven, herindexering en grotere migraties uit in duidelijke onderhoudsfasen. Als de vensters goed zijn, worden latentiepieken verminderd omdat de opslag genoeg ruimte heeft voor gelijkmatige flushes. Ik synchroniseer ook cron jobs en back-up startpunten om botsingen te voorkomen. Deze eenvoudige orkestratie zorgt vaak voor snelle, meetbare effecten zonder de hardware te veranderen.
Stel realistische hersteldoelen
Realistisch RTO en RPO bepalen hoe nauw ik controlepunten klok. Als ik bijzonder korte hersteltijden wil, verhoog ik de frequentie en log persistentie tot een redelijke mate. Als ik vooral consistente latenties nodig heb, rek ik checkpoints uit en kies ik voor grotere logs. Coördinatie met de back-up strategie en replicatie blijft belangrijk zodat alle tandwielen in elkaar passen. Ik documenteer deze doelen expliciet zodat latere aanpassingen gebaseerd zijn op duidelijke richtlijnen.
Motorspecifieke stelschroeven in het dagelijks leven
Veel basisprincipes zijn universeel, maar de details verschillen per motor. Daarom pas ik de hendels specifiek aan:
- PostgreSQL: checkpoint_timeout en max_wal_grootte bepalen hoe snel WAL-niveaus controlepunten activeren. Met controlepunt_voltooiing_doel Ik verdeel flushes over een groter deel van de tijd. Een te klein WAL-budget genereert frequente, korte pieken; een te groot budget vergroot het herstelpad en het opslagverbruik. De bgwriter (Background Writer) vlakt ook af, op voorwaarde dat de limieten niet te conservatief worden ingesteld.
- MySQL/InnoDB: Ik let op innodb_log_file_size of de totale grootte van het opnieuw uitvoeren, innodb_io_capaciteit(_max) voor het spoeltempo en innodb_max_dirty_pages_pct(_lazy) om de vuilsnelheid te regelen. innodb_flush_log_at_trx_commit beïnvloedt duurzaamheid vs. latentie - ik kies mildere instellingen met voorzichtigheid en alleen met schone stroombeveiliging.
- SQL Server: Indirecte checkpoints (target hersteltijd) vlakken flushes af in vergelijking met het klassieke herstelinterval. Ik stel conservatieve doelen voor databases met een hoog aandeel OLTP en controleer of TempDB en logvolume afzonderlijk voldoende prestaties bieden zodat checkpoints niet in de weg zitten.
Ze hebben allemaal één ding gemeen: Ik definieer een verstandige loggrootte, beperk vuile pagina's en verscherp de throttle (doorspoelsnelheden) zodat latencies stabiel blijven onder normale en piekbelastingen.
Replicatie, PITR en back-ups in interactie
Replicatiepaden en back-ups veranderen de vergelijking. Loggebaseerde replicatie (WAL/Binlog/Redo) heeft baat bij grotere logsegmenten en zelfs flushes omdat er minder fragmentatie en overruns zijn. Snapshot backups via de opslaglaag zijn praktisch, maar creëren korte-termijn druk op caches en metadata; ik plaats ze in rustige fases en vermijd overlappingen met grote checkpoints. Als u PITR gebruikt, plan dan bewust de retentie van logs - een te korte retentieperiode verlaagt de kosten, maar kan hersteldoelen doorkruisen. Indien nodig, smoor ik checkpoints op replicas om prioriteit te geven aan het lezen van applicaties zonder de vertragingen te vergroten.
Bestandssysteem en OS tuning met gevoel voor verhoudingen
Onder de database beslist ook het besturingssysteem. Ik controleer I/O schedulers, mount opties en kernel dirty instellingen:
- Een moderne scheduler met lage latency (bijvoorbeeld MQ-gebaseerde varianten) helpt om flush waves af te vlakken.
- Monteer opties zoals noatime het schrijven van metadata te verminderen; ik selecteer journaling modi op zo'n manier dat consistentie en prestaties in balans blijven.
- Kernelparameters (vuile_achtergrond_verhouding, vuile_ratio) mag de eigen regels van de database niet doorkruisen. Ik voorkom globale geforceerde flushes door ze gematigd in te stellen.
- Ik gebruik Cgroups/IO-quota in containers om luidruchtige buren te isoleren en voorspelbare latenties te garanderen.
Ik test elke wijziging onder echte belasting, omdat al te agressieve systeemaanpassingen snel neveneffecten kunnen hebben op het herstel van crashs en de duurzaamheid van gegevens.

Diagnostisch draaiboek en typische foutpatronen
Wanneer latenties toenemen, werk ik op een gestructureerde manier:
- Metriek correleren: Checkpoint duur, aantal pagina's geschreven, log vulniveaus, IOPS, wachtrij diepte, CPU wachttijden. Pieken die beginnen met een toenemende vervuilingssnelheid en eindigen met grote spoelreeksen duiden op te smalle intervallen of te kleine logs.
- Foutmeldingen: Frequente geforceerde checkpoints duiden op harde dirty limieten of overvolle logs. Toenemende hersteltijden na herstarten duiden op checkpoints die te zeldzaam zijn of logsegmenten die te groot zijn zonder geschikte voltooiingsdoelen.
- Index ballast detecteren: Hoge redo schrijfsnelheid voor eigenlijk kleine app wijzigingen toont onnodige secundaire indexen of regels die te breed zijn.
- Storende opslag: Als back-ups, compressie of herindexeren dezelfde volumes belasten, spreek ik van botsende bronnen - ik los dit op in termen van tijd of door ze te scheiden.
Pas als de oorzaak duidelijk is, verander ik de parameters. Op deze manier voorkom ik dat symptomen verschuiven in plaats van ze op te lossen.
Test- en uitrolstrategie voor controlepuntafstemming
Ik verander nooit blindelings kritieke stelschroeven. In plaats daarvan:
- Kanariebenadering: Een replica of stagingomgeving ontvangt de nieuwe waarden als eerste.
- Belastingsprofielen: Ik voer realistische verkeerspatronen in (pieken, batchvensters, achtergrondtaken) om het gedrag van de controlestations over een hele cyclus te zien.
- Stapsgewijze aanpassing: Kleine stappen in loggrootte, interval en voltooiingsdoel geven duidelijke voor/na-signalen.
- Terugdraaiplan: ik houd originele waarden bij de hand en documenteer de effecten zodat het team reproduceerbaar kan optimaliseren.
Container- en multi-tenantomgevingen
In containeroperaties en op gedeelde hosts besteed ik speciale aandacht aan isolatie. Cgroup limieten voor IOPS/doorvoer voorkomen dat individuele diensten checkpoints van anderen verdringen. In orkestraties plan ik opslagklassen en volumes zodat logs en gegevens verdeeld worden over geschikte profielen (lage latency vs. hoge doorvoer). Leesreplica's verlichten gemengde werklasten als hun checkpoints niet op hetzelfde moment draaien als die van het primaire systeem. In multi-tenant scenario's stel ik harde limieten in voor vuile pagina's per instantie zodat geen enkele klant overmatig gebruik maakt van het schrijfbudget.
Gerichte werking van werklastprofielen
OLTP-systemen reageren gevoelig op latentiepieken. Hier rek ik checkpoints aanzienlijk uit en houd ik logs groot genoeg zodat sporadische belastingspieken niet meteen een flush triggeren. In OLAP/batch scenario's kan ik agressiever spoelen als piekmomenten gepland kunnen worden. Event ingestion heeft baat bij batch-schrijvingen en een gematigde versoepeling van de duurzaamheidsparameters als de infrastructuur en UPS dit toelaten. Ik scheid gemengde werklasten - logisch via wachtrijen en fysiek via volumes - zodat hun checkpoints elkaar niet overlappen.
Pragmatische beoordeling van kosten en SSD-duurzaamheid
Ik bereken de schrijfversterking tegen het TBW/DWPD-budget van de SSD's. Als de dagelijkse schrijfsnelheid met een paar procentpunten daalt, wordt de levensduur vaak merkbaar verlengd. Ik volg:
- App schrijft vs. fysieke schrijft (afgeleid van OS/controller statistieken)
- Aandeel van schrijven naar controlestations in de totale schrijfsnelheid
- Capaciteitsgroei van logbestanden en gegevensbestanden in de loop der tijd
Door checkpoints af te vlakken, indices te stroomlijnen en batchpaden aan te leggen, bespaar je niet alleen IOPS, maar ook echte hardwarekosten - zonder aan functies in te boeten.
Runbooks en alarmen
Ik stel duidelijke grenzen voor wanneer maatregelen van kracht worden:
- Checkpoint duur overschrijdt regelmatig een bepaald deel van het interval (bijv. 60%)
- Vuile paginasnelheid schommelt dicht bij de geforceerde trigger
- IO-Wait of P99 latentie neemt toe in temporele nabijheid van checkpoints
- Logniveaus bereiken herhaaldelijk drempels die ongewenste spoelingen activeren
Ik koppel alarmen aan runbookstappen: belasting gelijk maken, back-ups verplaatsen, parameters tijdelijk verhogen totdat de werkelijke correctie (loggrootte, voltooiingsdoel, index opschonen) is doorgevoerd.
Kort samengevat
Ik optimaliseer database checkpointing, door interval, voltooiingsdoel, loggrootte en quota voor vuile pagina's te balanceren. Tegelijkertijd verminder ik schrijfversterking met minder indices, batch-schrijvingen, uitbestede sessies en duidelijke schema's. Monitoring maakt checkpoints, IO-pieken en buffergedrag zichtbaar, zodat ik gericht kan bijsturen. De keuze voor hosting met een snelle NVMe basis, gegarandeerde IO resources en verstandige parameters dicht de gaten. Hierdoor realiseer ik kortere reactietijden, snel herstel en lagere kosten dankzij minder onnodige schrijfacties.


