 Przejdź do treści
Przejdź do treści 
A Serwer stronicowania pamięci może znacznie stracić czas reakcji i przepustowość pod obciążeniem, jeśli zbyt wiele stron przenosi się z pamięci RAM do wymiany. W tym artykule przedstawię przyczyny, zmierzone wartości i konkretne dostosowania, które mogę wprowadzić, aby spowolnić stronicowanie i zauważalnie zwiększyć wydajność serwera.
Punkty centralne
Aby zapewnić jasną orientację, krótko podsumuję kluczowe wiadomości i pokażę, gdzie znajdują się typowe wąskie gardła i jak je rozwiązać. Wysokie wskaźniki stronicowania dużo kosztują Wydajność, ponieważ dostęp do nośników danych jest znacznie wolniejszy niż w przypadku pamięci RAM. Zmierzone wartości, takie jak Dostępne MBajty, Uzyskane Bajty i Strony/Sekundę dostarczają mi wiarygodnych informacji. Sygnały dla zbliżającego się thrashingu. Wirtualizacja zaostrza efekty wymiany poprzez balonowanie i wymianę hiperwizora, gdy hosty są przepełnione. Zmniejszam liczbę błędów stron dzięki aktualizacji pamięci RAM, THP/dużym stronom, dostrajaniu NUMA i czystym wzorcom alokacji. Regularne monitorowanie utrzymuje Ryzyko i umożliwia obliczenie szczytów obciążenia.
- Swap vs RAMNanosekundy w pamięci RAM vs. mikro/milisekundy na nośnikach danych
- ThrashingWięcej transferów stron niż użytecznej pracy, opóźnienia eksplodują
- Fragmentacja: Duże alokacje nie powiodły się pomimo „wolnej“ pamięci
- WskaźnikiDostępne MBajty, Uzyskane Bajty, Strony/Sek.
- StrojenieTHP/Huge Pages, vm.min_free_kbytes, NUMA, RAM

Jak działa stronicowanie na serwerach
Rozdzielam pamięć wirtualną i fizyczną na stałe strony, zazwyczaj 4 KB, co jest MMU poprzez tabele stron. Jeśli pamięci RAM zaczyna brakować, system operacyjny przenosi nieaktywne strony do obszarów swap lub swap. Każdy błąd strony zmusza jądro do pobrania danych z nośnika danych i kosztuje cenną pamięć RAM. Czas. Duże strony, takie jak Transparent Huge Pages (THP), zmniejszają wysiłek administracyjny i minimalizują pominięcia TLB. Dla początkujących warto rzucić okiem na pamięć wirtualna, aby lepiej zrozumieć relacje między procesami, ramkami stron i swapami.
Swap vs RAM: opóźnienia i thrashing
Pamięć RAM reaguje w nanosekundach, podczas gdy dyski SSD/HDD reagują w mikro- lub milisekundach, a zatem są o rzędy wielkości szybsze. wolniejszy są. Jeśli obciążenie przekracza fizyczną pamięć roboczą, szybkość stronicowania wzrasta, a procesor czeka na operacje wejścia/wyjścia. Efekt ten może łatwo prowadzić do thrashingu, w którym więcej czasu spędza się na wymianie niż na produktywnej pracy. Praca jest tracona. Zwłaszcza przy wykorzystaniu 80-90% pogarsza się interaktywność i zdalne sesje. Sprawdzam Wykorzystanie swapów i wyznaczyć granice, zanim system się przewróci.

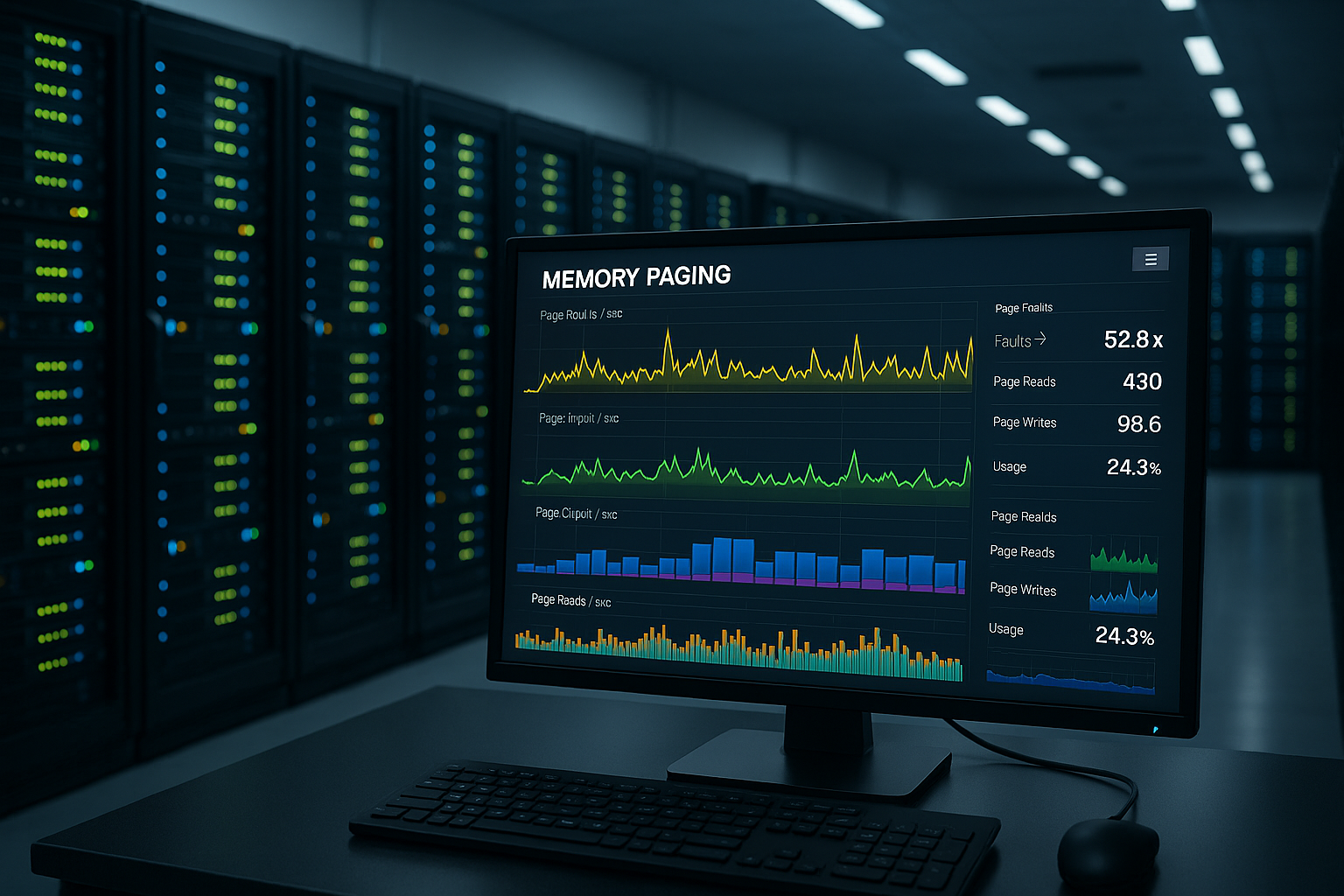
Wskaźniki i wartości progowe
Czyste zmierzone wartości pozwalają podejmować decyzje RAM i strojenie. W systemie Windows zwracam uwagę na dostępne MBajty, cessed Bytes, Pages/Second i Pool paged/nonpaged bytes. Po stronie Linuksa sprawdzam vmstat, free, sar, ps meminfo i dmesg pod kątem zdarzeń związanych z brakiem pamięci. Rosnące problemy ze stronami przy malejących wolnych MB wskazują na zbliżające się wąskie gardła. Krytyczne progi planuję konserwatywnie, aby uniknąć szczytów obciążenia bez Włamanie przechwytywanie.
| Wskaźnik wydajności | Zdrowy | Ostrzeżenie | Krytyczny |
|---|---|---|---|
| \Pamięć\Pula bajtów stronicowanych / bajtów niestronicowanych | 0-50% | 60-80% | 80-100% |
| Dostępne MBajty | >10% lub 4 GB | <10% | <1% lub <500 MB |
| % Zapisane bajty | 0-50% | 60-80% | 80-100% |
Linux: Zamienność, Zswap/ZRAM i parametry zapisu zwrotnego
Oprócz THP/Huge Pages, zauważalnie zmniejszyłem stronicowanie poprzez kontrolowanie agresywności wymiany i zapisu zwrotnego. vm.swappiness kontroluje jak wcześnie jądro wypycha strony do swapu. Na serwerach z dużą ilością pamięci RAM zwykle używam 1-10, aby pamięć podręczna stron pozostała duża, a nieaktywne sterty nie migrowały przedwcześnie. Na bardzo rzadkich systemach nieco wyższa wartość może uratować interaktywność, ponieważ pamięć podręczna nie wysycha całkowicie - decydującym czynnikiem jest pomiar pod rzeczywistym obciążeniem.
Z Zswap (skompresowana wymiana w pamięci RAM), zmniejszam ciśnienie we/wy, jeśli jest dużo zimnych stron przez krótki czas. Kosztuje to cykle procesora, ale często jest tańsze niż blokowe I/O. W przypadku systemów brzegowych lub laboratoryjnych czasami używam ZRAM jako podstawowa zamiana, aby małe hosty były bardziej wytrzymałe; używam go w sposób ukierunkowany w produkcji, gdy dostępny jest zapas procesora.
Ścieżki zapisu kontrolowane są przez vm.dirty_*-parametry. Zamiast wartości procentowych, wolę pracować z bezwzględnymi bajtami, aby uniknąć burz zapisu zwrotnego przy dużych pojemnościach pamięci RAM. Płukanie w tle rozpoczyna się wystarczająco wcześnie, podczas gdy dirty_bytes określa twarde górne limity dla leniwych obciążeń. Przykładowe wartości, których używam jako punktu wyjścia:
Ograniczona wymiana #
sysctl -w vm.swappiness=10
# Sprawdzenie writeback (bajty zamiast procentów)
sysctl -w vm.dirty_background_bytes=67108864 # 64 MB
sysctl -w vm.dirty_bytes=268435456 # 256 MB
# Nie odrzucaj pamięci podręcznej VFS zbyt agresywnie
sysctl -w vm.vfs_cache_pressure=50
Na stronie Projekt wymiany Preferuję szybkie urządzenia NVMe i ustawiam priorytety tak, aby jądro najpierw korzystało z najszybszej wymiany. Dedykowane urządzenie swap zapobiega fragmentacji plików swap.
# Sprawdź priorytety swap
swapon --show
# Aktywacja swapu na szybkim urządzeniu z wysokim priorytetem
swapon -p 100 /dev/nvme0n1p3
Ważne: Przestrzegam Główne/minimalne usterki i głębokość kolejki I/O równolegle - jest to jedyny sposób, w jaki mogę rozpoznać, czy zmniejszona swappiness lub Zswap wygładza rzeczywiste szczyty opóźnień.
Przyczyny wysokiej częstotliwości przywoływania
Jeśli nie ma fizycznej pamięci roboczej, bajty dostępu zwiększają się za pośrednictwem wbudowanej pamięci. RAM i system przełącza się na swap. Fragmentacja pamięci utrudnia duże alokacje, przez co aplikacje blokują się pomimo „wolnej“ pamięci RAM. Słabe zapytania lub brakujące indeksy niepotrzebnie zwiększają dostęp do danych i zwiększają obciążenie. Szczytowe obciążenia z kopii zapasowych, wdrożeń, ETL lub zadań cron łączą wymagania dotyczące pamięci w krótkich oknach czasowych. Maszyny wirtualne znajdują się pod dodatkową presją, gdy hosty przepełniają pamięć RAM i potajemnie wykonują zamiany hiperwizora. Aktywuj.
Wirtualizacja, balonowanie i nadmierne zaangażowanie
W środowiskach zwirtualizowanych hiperwizor ukrywa rzeczywistą ilość pamięci RAM i polega na balonowaniu i wymianie w obrębie pamięci RAM. Goście. Jeśli host napotka wąskie gardła, maszyny wirtualne tracą wydajność w tym samym czasie, chociaż każda z nich jest „zielona“ sama w sobie. Inteligentne stronicowanie podczas uruchamiania ukrywa zimne starty, ale przenosi koszty na potok I/O. Sprawdzam metryki hosta i gościa razem i redukuję nadmierne zaangażowanie, zanim użytkownicy to zauważą. Szczegóły na temat efektu overcommit opisałem w sekcji poświęconej Nadmierne zaangażowanie pamięci, aby planowanie wydajności pozostało elastyczne.
Kontenery i Kubernetes: cgroups, limity i eksmisje
Kontenery przenoszą limity pamięci z maszyny wirtualnej na cgroups. Decydującym czynnikiem jest to, że żądania oraz limity są ustawione realistycznie: Limity, które są zbyt ciasne, powodują wczesne zabijanie poza pamięcią, żądania, które są zbyt hojne, pogarszają wykorzystanie i udają rezerwy. Utrzymuję sterty z JVM/Node/.NET konsekwentnie związane z limitami kontenera (np. heurystyka procentowa), aby GC w czasie wykonywania nie napotykał na cgroup.
W Kubernetes zwracam uwagę na klasy QoS (Guaranteed, Burstable, BestEffort) i Progi eksmisji na poziomie węzła. Pod presją pamięci Kubelet faworyzuje pody BestEffort - jeśli chcesz utrzymać SLO, musisz odpowiednio budżetować zasoby. PSI (Pressure Stall Information) sprawia, że lokalna presja cgroup jest widoczna; używam tych sygnałów do proaktywnego skalowania lub zmiany harmonogramu podów. W przypadku obciążeń z dużymi stronami definiuję jawne żądania HugePage na pod, aby program planujący wybrał odpowiednie węzły.
Strategie optymalizacji: Sprzęt i system operacyjny
Zacznę od najbardziej trzeźwej śruby regulacyjnej: więcej RAM często natychmiast eliminuje największe opóźnienia. Równolegle redukuję błędy stron poprzez THP w trybie „on“ lub „madvise“, jeśli profile opóźnień na to pozwalają. Zarezerwowane ogromne strony zapewniają przewidywalność dla silników w pamięci, ale wymagają precyzyjnego planowania pojemności. Dzięki vm.min_free_kbytes tworzę rozsądne rezerwy, aby poradzić sobie ze szczytami alokacji bez kompensowania zagęszczania. Aktualizacje oprogramowania układowego i jądra eliminują błędy krawędziowe, zarządzanie pamięcią i NUMA-równowaga.
| Ustawienie | Cel | Korzyści | Wskazówka |
|---|---|---|---|
| vm.min_free_kbytes | Rezerwa na szczyty alokacji | Mniej OOM/zagęszczeń | 5-10% pamięci RAM |
| THP (włączony/zalecany) | Używaj większych stron | Mniejsza fragmentacja | Obserwowanie opóźnień |
| Ogromne strony | Bloki ciągłe | Przewidywalne alokacje | Mocna rezerwa mocy |
Bazy danych i hosting obciążeń
Bazy danych szybko cierpią, gdy pamięć podręczna bufora kurczy się, a zapytania są wykonywane z powodu wymiany w I/O drown. Twarde ograniczenie maksymalnej ilości pamięci chroni SQL/NoSQL przed wzajemnym wypieraniem z pamięci podręcznej systemu plików. Indeksy, sargability i niestandardowe strategie łączenia zmniejszają obciążenie, a tym samym presję na pamięć RAM. W konfiguracjach hostingowych planuję indeksy wyszukiwania, pamięci podręczne i pracowników PHP FPM w godzinach szczytu, aby profile obciążenia nie kolidowały ze sobą. Monitorowanie bufora i długości życia strony ostrzega mnie wcześnie przed Trendy spadkowe.

Praktyka: Plan pomiarów i harmonogram strojenia
Zaczynam od linii bazowej 24-72 godzin, aby widoczne były codzienne wzorce i zadania. stać się. Następnie ustawiam docelowy profil dla wolnej pamięci RAM, akceptowalnych stron/sekundę i maksymalnych czasów oczekiwania I/O. Następnie wprowadzam zmiany stopniowo: najpierw limity, potem THP/duże strony, a na końcu wydajność. Mierzę każdą zmianę w co najmniej jednym cyklu obciążenia przy użyciu tej samej metodologii. Planuję anulacje i dekonstrukcje z wyprzedzeniem, aby móc szybko reagować w przypadku negatywnych skutków. przekierować.
Powtarzalne testy obciążenia i prognozy wydajności
Aby uzyskać wiarygodne decyzje, odtwarzam typowe zestawy robocze: Cache ciepły/zimny, okna wsadowe, szczyty logowania/kasowania. Używam narzędzi syntetycznych (np. stress-ng dla ścieżek pamięci, fio dla I/O i benchmarków memcached/Redis dla typów pamięci podręcznej), aby specjalnie symulować presję pamięci. W każdym przypadku przeprowadzam testy w trzech wariantach: tylko aplikacja, aplikacja + współbieżne (kopia zapasowa, skanowanie AV), aplikacja + szczyty I / O. Pozwala mi to rozpoznać zakłócenia, które pozostają ukryte w testach tylko aplikacji.
Zbieram identyczne panele metryczne (pamięć, PSI, I/O wait, CPU steal/ready, błędy) dla każdej zmiany. Wdrożenie kanarkowe z ruchem 5-10% ujawnia ryzyko na wczesnym etapie, zanim wprowadzę konfigurację na szeroką skalę. Jeśli chodzi o przepustowość, planuję z najgorszymi zestawami roboczymi plus rezerwą - nie z wygładzonymi średnimi.
Rozwiązywanie problemów: narzędzia i podpisy
W Linuksie vmstat, sar, iostat, perf i strace dostarczają mi najważniejszych informacji. Uwagi dla błędów stron, czasów oczekiwania i sterty. Po stronie Windows polegam na Monitorze wydajności, Monitorze zasobów i śladach ETW. Komunikaty takie jak „compaction stalls“, „kswapd high CPU“ lub OOM kills wskazują na poważne wąskie gardła. Wahania interaktywności, długie pauzy GC i rosnące brudne strony potwierdzają podejrzenia. Używam zrzutów sterty i profilerów pamięci, aby znaleźć wycieki i niewłaściwe Przydziały.

Praktyka specyficzna dla systemu Windows: Pagefile, Working Set i Paged Pools
Na serwerach Windows zapewniam wystarczająco zwymiarowane Plik wymiany na szybkich dyskach SSD i unikać konfiguracji „bez pliku stronicowania“. Stałe minimalne rozmiary zapobiegają nieoczekiwanemu kurczeniu się i przycinaniu systemu w godzinach szczytu. W razie potrzeby rozdzielam pliki stron na kilka woluminów i obserwuję Usterki twarde/sek oraz wykorzystanie pul stronicowanych/niestronicowanych.
W przypadku usług intensywnie korzystających z pamięci, specjalnie aktywuję Blokowanie stron w pamięci (np. dla serwerów SQL), aby jądro nie wypychało obciążeń z zestawu roboczego. Jednocześnie czysto ograniczam pamięć podręczną aplikacji, aby system nie wysychał w inny sposób. Identyfikuję wycieki sterowników lub puli za pomocą PoolMon/RAMMap; w przypadku błędów kontrolowane przycięcie listy rezerwowej pomaga przywrócić interaktywność w krótkim okresie - tylko jako diagnoza, a nie jako trwałe rozwiązanie.
Ważne są również: plany oszczędzania energii ustawione na „maksymalną wydajność“, aktualne sterowniki NIC / pamięci masowej i oprogramowanie układowe. Dziwactwa harmonogramu lub przestarzałe sterowniki filtrów zaskakująco często prowadzą do szczytów pamięci i I/O, które mogę błędnie zinterpretować jako czysty niedobór pamięci RAM.
Rozsądne korzystanie z THP, NUMA i rozmiarów stron
Transparent Huge Pages zmniejszają obciążenie TLB, ale sporadyczne promocje mogą powodować skoki opóźnień. wytwarzać. Dlatego w przypadku obciążeń o ścisłych SLO często polegam na „madvise“ lub stałych ogromnych stronach. Równoważenie NUMA opłaca się w systemach wielogniazdowych, jeśli wątki i pamięć pozostają lokalne. Przypinam usługi do węzłów NUMA i monitoruję lokalne współczynniki pominięć. Ogromne strony zwiększają przepustowość, ale sprawdzam wewnętrzną fragmentację, aby nie mieć rozdawać.
Pamięć podręczna systemu plików, mmap i ścieżki we/wy
Duża część „wolnej“ pamięci znajduje się w Pamięć podręczna stron. Podejmuję świadomą decyzję co do tego, czy silnik korzysta z pamięci podręcznej systemu operacyjnego (buforowane wejścia/wyjścia), czy z samej pamięci podręcznej (bezpośrednie wejścia/wyjścia). Podwójne pamięci podręczne marnują pamięć RAM; jeśli brakuje pamięci podręcznej systemu operacyjnego readahead-opóźnienia. W przypadku obciążeń strumieniowych mogę zwiększyć readahead na urządzenie; losowe bazy danych działają lepiej z bezpośrednim I / O.
Przykład #: Zwiększenie readahead do 256 sektorów
blockdev --setra 256 /dev/nvme0n1
Wejścia/wyjścia mapowane w pamięci (mmap) oszczędza kopie, ale przenosi nacisk na pamięć podręczną strony. W wyjątkowych przypadkach przypinam krytyczne strony za pomocą mlock (lub limitów memlock), aby uniknąć zakłóceń spowodowanych odzyskiwaniem - zawsze z uwzględnieniem rezerw systemowych.
Szybkie środki awaryjne w przypadku nadciśnienia
- Zidentyfikuj głównych konsumentów (ps/top/procdump) i uruchom ponownie lub zmień harmonogram, jeśli to konieczne.
- Tymczasowe ograniczenie współbieżności (pracowników/wątków) w celu zmniejszenia liczby błędów i zapisów zwrotnych.
- Zmniejszenie brudnych limitów w krótkim okresie, tak aby odpisy zaczęły obowiązywać wcześniej, a rezerwy zostały uwolnione.
- W przypadku nadmiernego zaangażowania kontenera, ewakuuj określone pods; tymczasowo zwiększ zasoby w maszynach wirtualnych lub rozluźnij balonowanie.
- Sprawdź strategię OOM: aktywuj systemd-oomd/earlyoom i cgroup-runs, aby „właściwe“ procesy były uruchamiane jako pierwsze.
Planowanie wydajności i koszty
Pamięć RAM kosztuje, ale powtarzające się awarie kosztują przychody i Reputacja. W przypadku serwerów WWW i baz danych zwykle obliczam rezerwę 20-30% na pokrycie rzadkich szczytów. Dodatkowy moduł 64 GB za 180-280 euro często amortyzuje się szybciej niż ciągłe gaszenie pożarów. W środowiskach chmurowych unikam nadmiernej rezerwacji i rezerwuję bufory etapami, które odpowiadają wzorcom obciążenia. Trzeźwe kalkulacje TCO przebijają ładne wykresy, ponieważ biorą pod uwagę szkody związane z opóźnieniami i czas operatora. cena w.

Krótkie podsumowanie
A Serwer stronicowania pamięci czerpie największe korzyści z wystarczającej ilości pamięci RAM, czystej konfiguracji THP/dużych stron i realistycznego overcommit. Polegam na jasnych wskaźnikach, takich jak dostępne bajty, dostępne bajty i strony/sekundę. Podwójnie sprawdzam zwirtualizowane środowiska, aby balonowanie i wymiana hosta nie kradły ukrytej wydajności. Trzymam bazy danych z dala od swapów ze zdefiniowanymi cache'ami i limitami. Jeśli wdrożysz te kroki konsekwentnie, zmniejszysz opóźnienia, zapobiegniesz awariom i utrzymasz Wydajność stabilny przy szczytach obciążenia.


