 Saltar para o conteúdo
Saltar para o conteúdo 
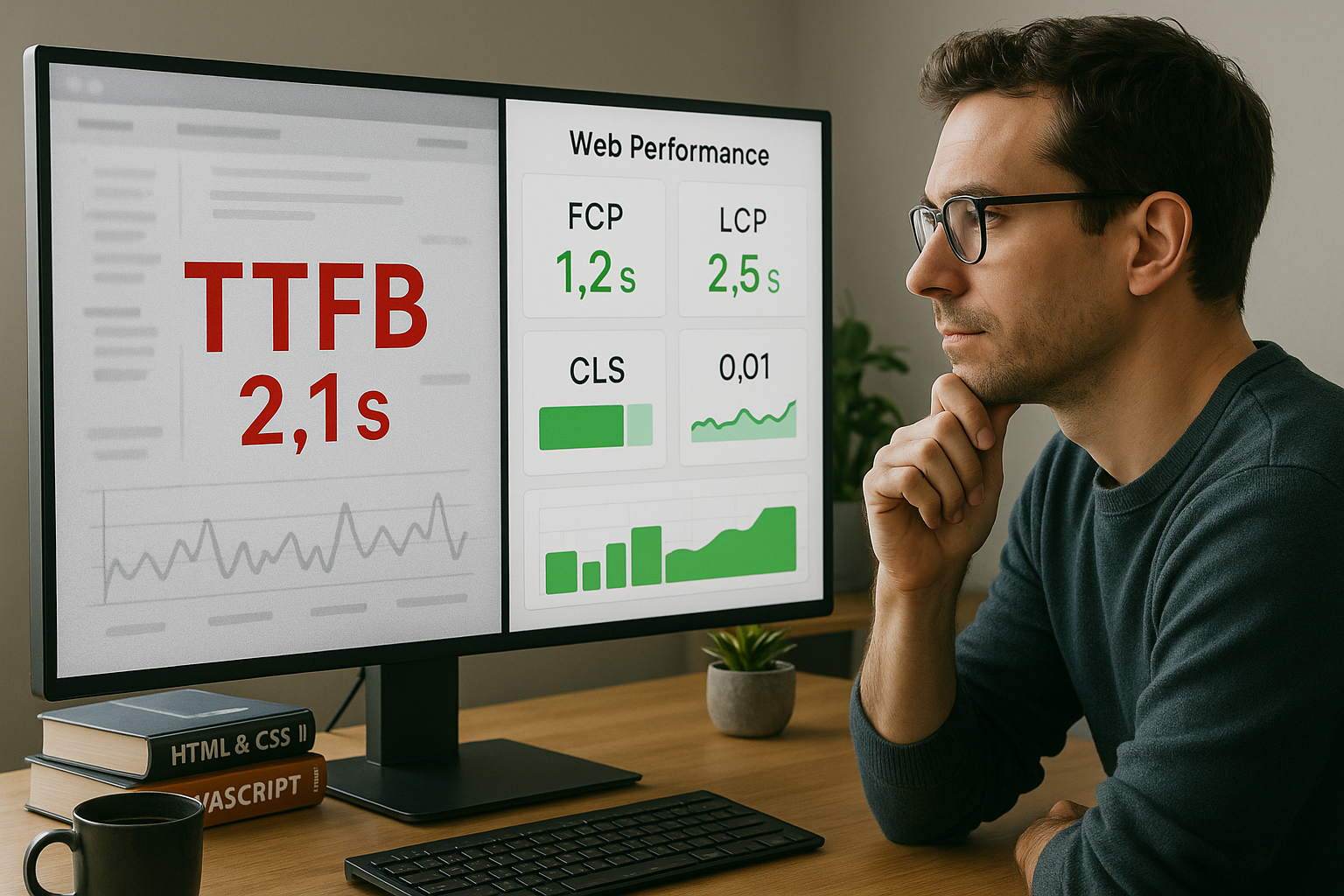
Uma análise TTFB bem fundamentada mostra por que razão o carimbo de data/hora do primeiro byte é frequentemente mal interpretado e como combino as medições com as métricas do utilizador de uma forma significativa. Explico especificamente onde ocorrem as interpretações erradas, como recolho dados consistentes e quais as optimizações que o Perceção aumentar efetivamente a velocidade.
Pontos centrais
- TTFB descreve o arranque do servidor, não a velocidade global.
- Contexto em vez de um valor único: Ler LCP, FCP, INP.
- Localização e a rede caracterizam os valores medidos.
- Armazenamento em cache e a CDN reduzem a latência.
- Recursos e a configuração têm um efeito direto.

Breve explicação da TTFB: Compreender a cadeia de medição
O TTFB mapeia o tempo desde o pedido até ao primeiro byte devolvido e compreende várias etapas, a que chamo Cadeia de medição deve ser considerado. Isto inclui a resolução de DNS, o aperto de mão TCP, a negociação TLS, o processamento do servidor e o envio do primeiro byte. Cada secção pode criar estrangulamentos, o que altera significativamente o tempo total. Uma ferramenta mostra um único valor aqui, mas as causas estão em vários níveis. Por conseguinte, separo a latência do transporte, a resposta do servidor e a lógica da aplicação, a fim de Fontes de erro claramente atribuíveis.
Otimizar o caminho da rede: DNS para TLS
Vou começar pelo nome: Os resolvedores de DNS, as cadeias CNAME e os TTLs influenciam a rapidez com que um anfitrião é resolvido. Demasiados redireccionamentos ou um resolvedor com uma latência elevada acrescentam milissegundos perceptíveis. Depois, a ligação conta: Reduzo as viagens de ida e volta com estratégias do tipo keep-alive, TCP fast-open e partilha rápida de portas. Com o TLS, verifico a cadeia de certificados, o agrafamento OCSP e o reinício da sessão. Uma cadeia de certificados curta e o agrafamento ativado poupam os apertos de mão, enquanto os protocolos modernos, como o HTTP/2 e o HTTP/3, multiplexam vários pedidos de forma eficiente numa só ligação.
Registo também o caminho: O IPv6 pode ter vantagens em redes bem conectadas, mas rotas de peering fracas aumentam o jitter e a perda de pacotes. Nas redes móveis, cada viagem de ida e volta desempenha um papel mais importante, razão pela qual sou a favor de mecanismos 0-RTT, ALPN e versões rápidas de TLS. O que é importante para mim é que a otimização do transporte não só acelera o TTFB, mas também estabiliza a variação. Um intervalo de medição estável torna as minhas optimizações mais reprodutíveis e as decisões mais fiáveis.
As 3 interpretações erradas mais comuns
1) TTFB significa a velocidade total
Um TTFB baixo diz pouco sobre a renderização, a entrega de imagens ou a execução de JavaScript, ou seja, sobre o que as pessoas podem fazer diretamente. Ver. Uma página pode enviar um primeiro byte logo no início, mas depois falhar devido ao maior conteúdo (LCP). Observo frequentemente primeiros bytes rápidos com uma interatividade lenta. A velocidade percebida só ocorre quando o conteúdo relevante aparece e reage. É por isso que uma vista fixa TTFB associa o Realidade de utilização a partir do valor medido.
2) Baixo TTFB = boa experiência do utilizador e SEO
Posso aumentar artificialmente o TTFB, por exemplo, utilizando cabeçalhos antecipados, sem fornecer conteúdo útil, que é o que a verdadeira Valor de utilidade não aumenta. Os motores de busca e as pessoas valorizam mais a visibilidade e a facilidade de utilização do que o primeiro byte. Métricas como o LCP e o INP reflectem melhor a sensação da página. Um enfoque puramente TTFB ignora as etapas críticas de renderização e interatividade. Por isso, faço medições adicionais para que as decisões possam ser baseadas em Dados com relevância.
3) Todos os valores TTFB são comparáveis
O ponto de medição, o peering, a carga e a distância distorcem as comparações que dificilmente poderia fazer sem as mesmas condições de enquadramento. Taxa pode. Um servidor de teste nos EUA mede de forma diferente de um em Frankfurt. As flutuações de carga entre a manhã e a noite também alteram significativamente os resultados. Por isso, utilizo várias execuções, pelo menos em dois locais e em horários diferentes. Apenas esta gama fornece uma sólida Classificação do valor.

Sintético vs. RUM: duas perspectivas sobre a TTFB
Combino testes sintéticos com monitorização de utilizadores reais (RUM) porque ambos respondem a questões diferentes. Os testes sintéticos dão-me referências controladas com estruturas claras, ideais para testes de regressão e comparações. A RUM reflecte a realidade entre dispositivos, redes e regiões e mostra como a TTFB flutua no terreno. Trabalho com percentis em vez de médias para reconhecer os valores anómalos e segmentar por dispositivo (móvel/desktop), país e qualidade da rede. Só quando são encontrados padrões em ambos os mundos é que avalio as causas e as medidas como sólidas.
O que é que realmente influencia a TTFB?
A escolha do ambiente de alojamento tem um grande impacto na latência, na IO e no tempo de computação, o que se reflecte diretamente na TTFB mostra. Os sistemas com excesso de reservas respondem mais lentamente, enquanto os SSD NVMe, as pilhas modernas e os bons caminhos de peering permitem tempos de resposta curtos. A configuração do servidor também conta: definições de PHP inadequadas, opcache fraca ou pouca RAM provocam atrasos. Com as bases de dados, noto consultas lentas em todos os pedidos, especialmente com tabelas não indexadas. Uma CDN reduz a distância e diminui o Latência para conteúdo estático e em cache.
PHP-FPM e otimização do tempo de execução na prática
Verifico o gestor de processos: um número demasiado reduzido de PHP workers gera filas de espera, demasiados deslocam as caches da RAM. Equilibro definições como max_children, pm (dinâmico/ondemand) e limites de pedidos com base em perfis de carga reais. Mantenho a Opcache quente e estável, reduzo a sobrecarga do autoloader (classmaps optimizados), ativo a cache realpath e removo as extensões de depuração em produção. Movo inicializações dispendiosas para bootstraps e coloco os resultados em cache na cache de objectos. Isso reduz o tempo entre a aceitação do socket e o primeiro byte sem ter que sacrificar a funcionalidade.
Como medir corretamente a TTFB
Faço o teste várias vezes, em momentos diferentes, em pelo menos dois locais e formo medianas ou percentis para obter um resultado fiável Base. Verifico também se a cache está quente, porque o primeiro acesso demora frequentemente mais tempo do que todos os acessos subsequentes. Correlaciono o TTFB com LCP, FCP, INP e CLS para que o valor faça sentido no quadro geral. Para o efeito, utilizo execuções dedicadas para HTML, recursos críticos e conteúdos de terceiros. Um bom ponto de partida é a avaliação em torno de Principais dados vitais da Webporque são os Perceção dos utilizadores.
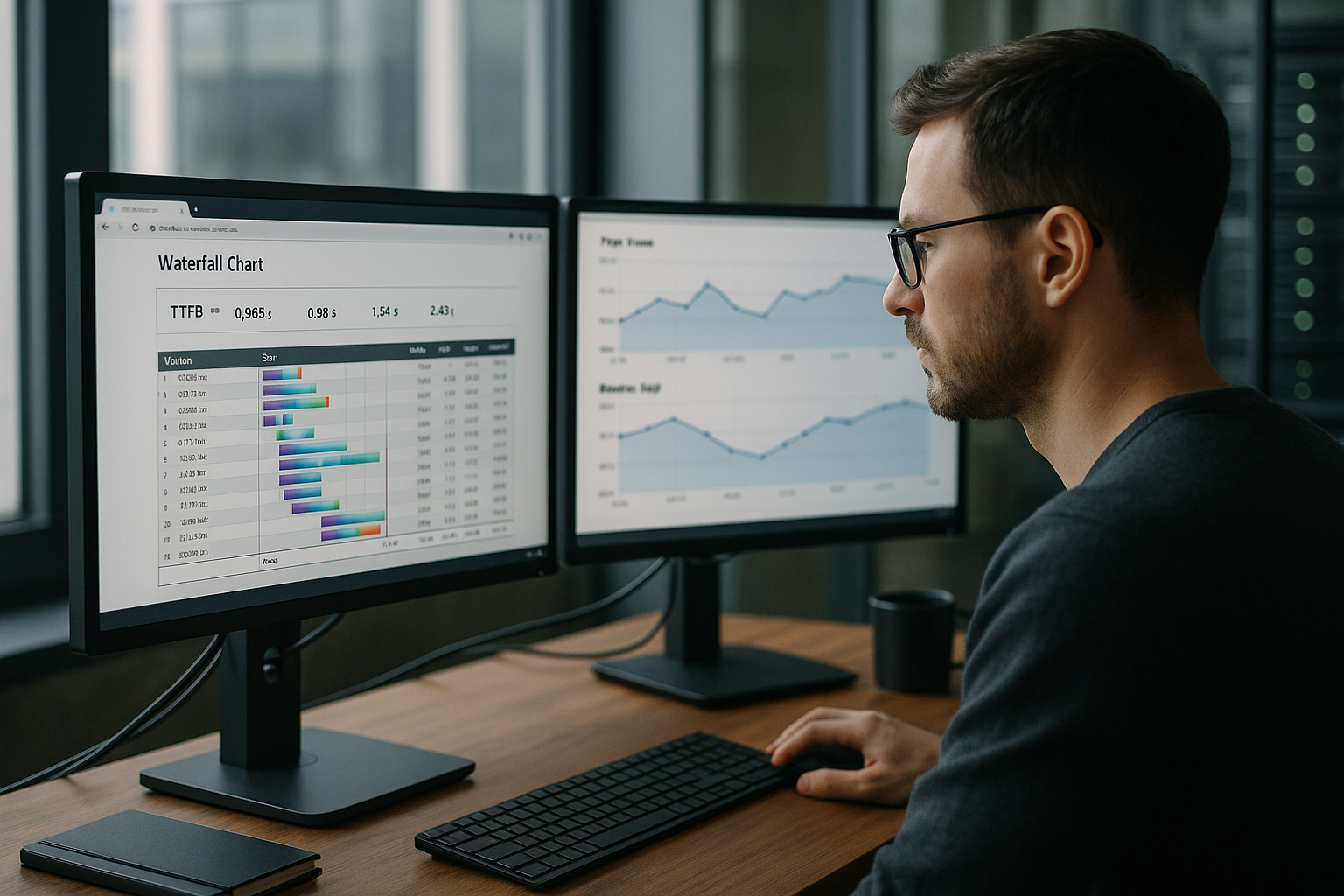
Tempo e rastreabilidade do servidor
Também envio cabeçalhos de tempo do servidor para tornar as partilhas de tempo transparentes: por exemplo, dns, connect, tls, app, db, cache. Adiciono os mesmos marcadores aos registos e forneço pedidos com IDs de rastreio para que possa rastrear execuções individuais através de CDN, Edge e Origin. Essa granularidade evita jogos de adivinhação: Em vez de "TTFB é elevado", posso ver se a base de dados precisa de 180 ms ou se a Origin está presa numa fila durante 120 ms. Com percentis por rota (por exemplo, detalhe do produto vs. pesquisa), defino orçamentos claros e posso parar regressões no IC numa fase inicial.
Melhores práticas: Primeiro byte mais rápido
Utilizo o cache do lado do servidor para HTML para que o servidor possa fornecer respostas prontas e o CPU não tem de recalcular todos os pedidos. Uma CDN global aproxima os conteúdos dos utilizadores e reduz a distância, o tempo de DNS e o encaminhamento. Mantenho o PHP, a base de dados e o servidor Web actualizados, ativo a Opcache e utilizo HTTP/2 ou HTTP/3 para uma melhor utilização da ligação. Transporto chamadas API externas dispendiosas de forma assíncrona ou coloco-as em cache para que o primeiro byte não fique à espera. A criação regular de perfis abrange as consultas lentas e Plugins que eu neutralizo ou substituo.
Estratégias de armazenamento em cache em pormenor: TTL, Vary e Microcaching
Faço uma distinção rigorosa entre dinâmico e armazenável em cache. O HTML recebe TTLs curtos e microcaching (por exemplo, 5-30 s) para picos de carga, enquanto as respostas da API com cabeçalhos de controlo de cache claros e ETags podem viver mais tempo. Utilizo o Vary de forma selectiva: Apenas quando o idioma, os cookies ou o agente do utilizador geram realmente conteúdos diferentes. Chaves Vary demasiado amplas destroem a taxa de acerto. Com stale-while-revalidate entrego imediatamente e actualizo em segundo plano; stale-if-error mantém a página acessível se o backend parar. Importante: Evite cookies no domínio raiz se eles impedirem involuntariamente o armazenamento em cache.
Para as alterações, planeio uma limpeza da cache através de parâmetros de versão ou hashes de conteúdo. Limito as invalidações de HTML às rotas afectadas em vez de desencadear purgas globais. Para CDNs, uso warmups regionais e um escudo de origem para proteger o servidor de origem. Isto mantém o TTFB estável mesmo durante picos de tráfego sem ter de sobredimensionar a capacidade.
TTFB vs. experiência do utilizador: métricas importantes
Classifico LCP para Largest Visible Content (maior conteúdo visível), FCP para First Content (primeiro conteúdo) e INP para Input Response (resposta de entrada) porque estas métricas são a experiência percetível fazer. Uma página pode ter um TTFB moderado e ainda assim parecer rápida se a renderização importante ocorrer mais cedo. Por outro lado, um TTFB pequeno tem pouca utilidade se os scripts de bloqueio atrasarem a apresentação. Eu uso o Análise do farolpara verificar a sequência de recursos, o caminho de renderização e as prioridades. Isto permite-me ver qual a otimização que realmente Ajudas.

Definir corretamente as prioridades de renderização
Certifico-me de que os recursos críticos vêm antes de tudo o resto: CSS crítico em linha, fontes com exibição de fonte e pré-carregamento/priorização sensata, imagens acima da dobra com prioridade de busca apropriada. Carrego o JavaScript o mais tarde possível ou de forma assíncrona e limpo a carga da thread principal para que o browser possa pintar rapidamente. Utilizo early hints para acionar pré-carregamentos antes da resposta final. Resultado: Mesmo que o TTFB não seja perfeito, a página parece muito mais rápida devido à visibilidade antecipada e à resposta rápida.
Evitar erros de medição: obstáculos típicos
Uma cache quente distorce as comparações e é por isso que faço a distinção entre pedidos frios e quentes. separado. Uma CDN também pode ter extremidades desactualizadas ou não replicadas, o que prolonga a primeira recuperação. Verifico a utilização do servidor em paralelo para que as cópias de segurança ou as tarefas cron não influenciem a medição. Do lado do cliente, presto atenção à cache do browser e à qualidade da ligação para minimizar os efeitos locais. Até os resolvedores de DNS alteram a latência, por isso mantenho o ambiente de teste como constante.
Considerar CDN, WAF e camadas de segurança
Sistemas intermediários como WAF, filtros de bots e proteção DDoS podem aumentar o TTFB sem que a origem seja culpada. Verifico se a terminação TLS ocorre no limite, se um escudo está ativo e como as regras desencadeiam verificações complexas. Limites de taxa, geofencing ou desafios JavaScript são muitas vezes úteis, mas não devem alterar os valores medianos sem serem notados. Por isso, meço separadamente os acertos no limite e as falhas na origem e tenho regras de exceção para testes sintéticos prontos a distinguir os problemas reais dos mecanismos de proteção.
Decisões de acolhimento que compensam
SSDs NVMe rápidos, RAM suficiente e CPUs modernas fornecem o backend com potência suficiente. Desempenhopara que as respostas comecem rapidamente. Dimensiono os trabalhadores PHP para corresponder ao tráfego, de modo a que os pedidos não fiquem em fila de espera. O impacto desse gargalo geralmente só se torna aparente sob carga, e é por isso que planejo a capacidade de forma realista. Para um planeamento prático, o guia para Planear corretamente os trabalhadores PHP. A proximidade do mercado-alvo e um bom peering também mantêm a Latência baixo.

Processos de implementação e qualidade
Trato o desempenho como uma caraterística de qualidade na entrega: defino orçamentos para TTFB, LCP e INP no pipeline CI/CD e bloqueio lançamentos com regressões claras. As versões canário e os sinalizadores de funcionalidades ajudam-me a dosear os riscos e a medi-los passo a passo. Antes de grandes alterações, executo testes de carga para identificar limites de trabalho, limites de ligação e bloqueios de bases de dados. Com testes de fumaça recorrentes em rotas representativas, reconheço deteriorações imediatamente - e não apenas quando chega o pico. Isto permite-me manter a melhoria medida a longo prazo.
Quadro prático: Cenários de medição e medidas
A panorâmica que se segue classifica as situações típicas e associa a TTFB observada a outros números-chave e elementos tangíveis Passos. Utilizo-as para identificar mais rapidamente as causas e derivar claramente as medidas. Continua a ser importante verificar os valores várias vezes e ler as métricas de contexto. Isto impede-me de tomar decisões que apenas actuam sobre os sintomas e não melhoram a perceção. A tabela ajuda-me a planear e a analisar os testes. Prioridades para definir.
| Cenário | Observação (TTFB) | Métricas de acompanhamento | Causa possível | Medida concreta |
|---|---|---|---|---|
| Primeira chamada da manhã | Elevado | LCP ok, FCP ok | Cache fria, despertar de BD | Pré-aquecer a cache do servidor, manter as ligações à base de dados |
| Pico de tráfego | Aumenta a passos largos | O INP deteriorou-se | Demasiado poucos trabalhadores PHP | Aumentar o número de trabalhadores, externalizar tarefas longas |
| Acesso global EUA | Significativamente mais elevado | LCP flutua | Distância, peering | Ativar CDN, utilizar cache de borda |
| Muitas páginas de produtos | Instável | FCP bom, LCP mau | Imagens de grandes dimensões, sem sugestões iniciais | Otimizar imagens, dar prioridade ao pré-carregamento |
| APIs de terceiros | Mutável | INP ok | Tempo de espera para a API | Respostas em cache, processadas de forma assíncrona |
| Atualização do backend do CMS | Mais alto do que antes | CLS inalterado | Novo plugin trava o funcionamento | Criação de perfis, substituição ou correção de plug-ins |
Resumo: Categorizar corretamente a TTFB no contexto
Um único valor TTFB raramente explica a sensação de uma página, pelo que o relaciono com LCP, FCP, INP e real Utilizadores. Meço várias vezes, sincronizo localizações e verifico a carga para obter resultados consistentes. Para lançamentos rápidos, utilizo cache, CDN, software atualizado e consultas simples. Ao mesmo tempo, dou prioridade à apresentação de conteúdos visíveis, porque uma visibilidade precoce melhora claramente a perceção. É assim que a minha análise TTFB conduz a decisões que optimizam a Experiência dos visitantes.


