 Saltar para o conteúdo
Saltar para o conteúdo 
A Servidor de paginação de memória pode perder significativamente o tempo de resposta e a taxa de transferência sob carga se muitas páginas forem movidas da RAM para a troca. Neste artigo, mostrarei as causas, os valores medidos e os ajustes específicos que posso fazer para diminuir a paginação e aumentar visivelmente o desempenho do servidor.
Pontos centrais
Para uma orientação clara, vou resumir brevemente as mensagens-chave e mostrar-lhe onde se encontram os estrangulamentos típicos e como resolvê-los. Taxas de paginação elevadas custam muito caro Desempenho, porque os acessos ao suporte de dados são muito mais lentos do que à RAM. Os valores medidos, como MBytes disponíveis, Bytes acedidos e Páginas/segundo, fornecem-me dados fiáveis Sinais para a colisão iminente. A virtualização exacerba os efeitos de swapping através do ballooning e do hypervisor swap quando os hosts estão sobrecarregados. Reduzo as falhas de página com actualizações de RAM, THP/páginas enormes, afinação de NUMA e padrões de atribuição limpos. A monitorização regular mantém Riscos e permite calcular os picos de carga.
- Swap vs RAMNanossegundos na RAM vs. micro/milissegundos nos suportes de dados
- Bater: Mais transferências de páginas do que trabalho útil, as latências explodem
- Fragmentação: Grandes alocações falham apesar da memória „livre
- IndicadoresMBytes disponíveis, Bytes acedidos, Páginas/Seg.
- AfinaçãoTHP/Páginas enormes, vm.min_free_kbytes, NUMA, RAM

Como funciona a paginação nos servidores
Eu separo a memória virtual e física em páginas fixas, tipicamente 4 KB, que é a MMU através de tabelas de páginas. Se a RAM se tornar escassa, o sistema operativo move as páginas inactivas para as áreas de troca ou swap. Cada falha de página obriga o kernel a ir buscar dados ao suporte de dados e custa RAM valiosa. Tempo. Páginas grandes, como as Transparent Huge Pages (THP), reduzem o esforço administrativo e minimizam os erros do TLB. Para iniciantes, vale a pena dar uma olhada em memória virtual, para entender melhor as relações entre processos, quadros de páginas e swap.
Swap vs. RAM: Latências e travamentos
A RAM responde em nanossegundos, enquanto os SSD/HDD respondem em micro a milissegundos e são, por isso, ordens de grandeza mais rápidos. mais lento são. Se a carga exceder a memória de trabalho física, a taxa de paginação aumenta e a CPU fica à espera de E/S. Este efeito pode facilmente levar ao thrashing, em que se gasta mais tempo na troca do que em trabalho produtivo. Trabalho é perdido. Especialmente com a utilização do 80-90%, a interatividade e as sessões remotas deterioram-se. Verifico o Utilização de swaps e traçar limites antes que o sistema tombe.

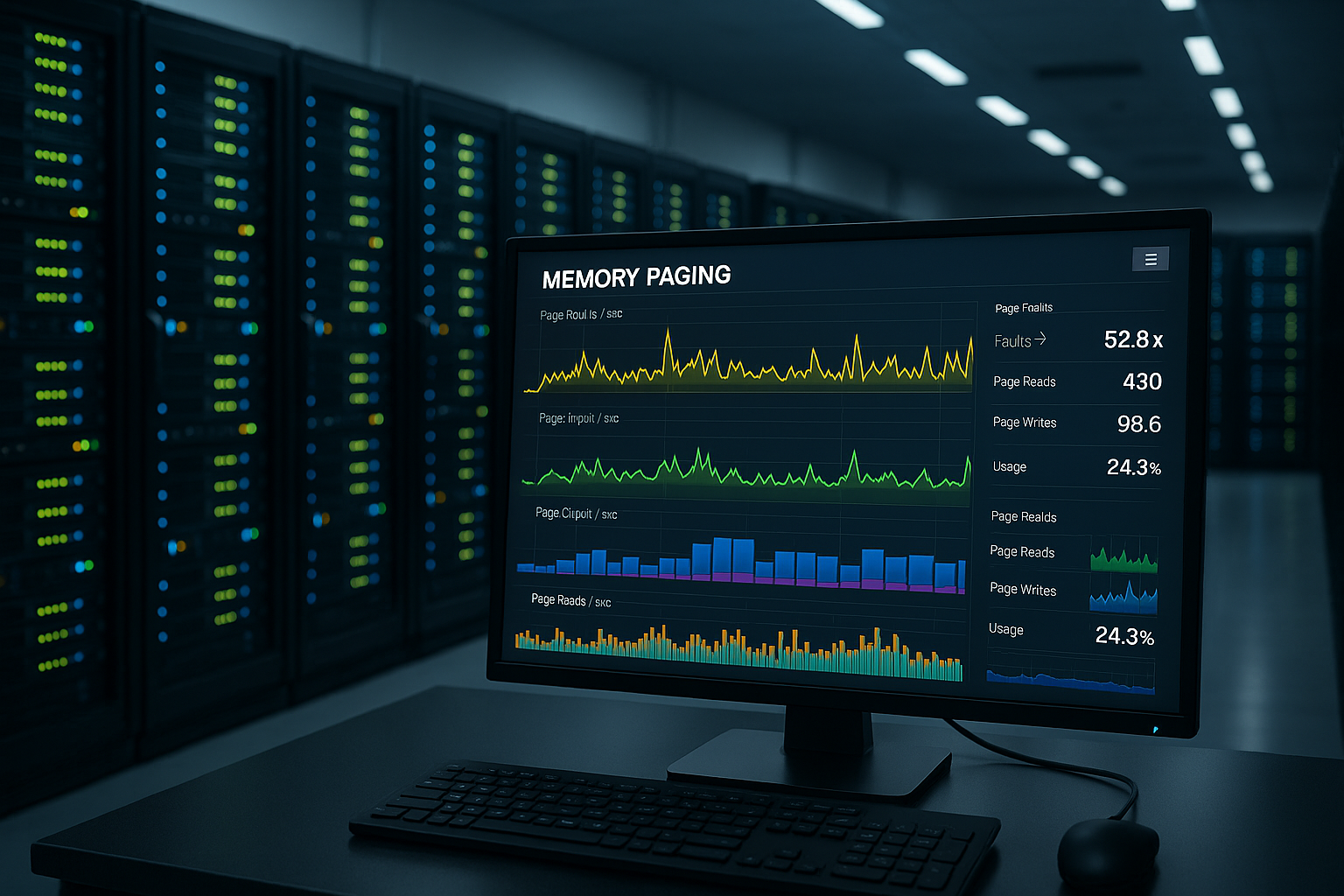
Indicadores e valores limiares
Valores medidos limpos tomam decisões RAM e afinação. No Windows, presto atenção aos MBytes disponíveis, cessed Bytes, Pages/Second e Pool paged/nonpaged bytes. No Linux, eu verifico vmstat, free, sar, ps meminfo e dmesg para eventos de falta de memória. O aumento de problemas de página com a diminuição de MBytes livres indica gargalos iminentes. Eu planeio limiares críticos de forma conservadora para que eu possa evitar picos de carga sem Roubo intercetar.
| Indicador de desempenho | Saudável | Aviso | Crítico |
|---|---|---|---|
| \Memory\Pool bytes paginados / bytes não paginados | 0-50% | 60-80% | 80-100% |
| MBytes disponíveis | >10% ou 4 GB | <10% | <1% ou <500 MB |
| % Bytes guardados | 0-50% | 60-80% | 80-100% |
Linux: Parâmetros de troca, Zswap/ZRAM e writeback
Para além do THP/Huge Pages, reduzo visivelmente a paginação controlando a agressividade da troca e do writeback. vm.swappiness controla o quão cedo o kernel empurra as páginas para a swap. Em servidores com muita RAM, normalmente uso 1-10 para que a cache de páginas permaneça grande e as heaps inactivas não migrem prematuramente. Em sistemas muito escassos, um valor ligeiramente superior pode salvar a interatividade porque a cache não se esgota completamente - o fator decisivo é a medição sob carga real.
Com Zswap (swap comprimido na RAM), reduzo a pressão de E/S se houver muitas páginas frias durante um curto período de tempo. Isso custa ciclos de CPU, mas geralmente é mais barato que a E/S em bloco. Para sistemas de ponta ou de laboratório, eu às vezes uso ZRAM como uma troca primária para tornar os hosts pequenos mais robustos; eu uso-o de uma forma direcionada na produção quando há espaço disponível para a CPU.
Controlo os caminhos de escrita através de vm.dirty_*-parâmetros. Em vez de valores percentuais, eu prefiro trabalhar com bytes absolutos para evitar tempestades de writeback com grandes capacidades de RAM. A descarga em segundo plano começa cedo o suficiente, enquanto bytes_sujos define limites superiores rígidos para cargas de trabalho preguiçosas. Valores de exemplo que utilizo como ponto de partida:
# restrained swapping
sysctl -w vm.swappiness=10
# Verificar writeback (bytes em vez de por cento)
sysctl -w vm.dirty_background_bytes=67108864 # 64 MB
sysctl -w vm.dirty_bytes=268435456 # 256 MB
# Não descarte o cache VFS de forma muito agressiva
sysctl -w vm.vfs_cache_pressure=50
Em Troca de design Eu prefiro dispositivos NVMe rápidos e defino prioridades para que o kernel use a troca mais rápida primeiro. Um dispositivo de troca dedicado evita a fragmentação dos ficheiros de troca.
# Verificar prioridades de troca
swapon --show
Ativar a troca # no dispositivo rápido com prioridade elevada
swapon -p 100 /dev/nvme0n1p3
Importante: Eu observo as falhas maiores/menores e a profundidade da fila de E/S em paralelo - esta é a única forma de saber se a redução do swappiness ou o Zswap está a suavizar os picos de latência reais.
Causas de taxas de paginação elevadas
Se não existir uma memória de trabalho física, os bytes de acesso aumentam através da memória interna. RAM e o sistema muda para a swap. A memória fragmentada dificulta as grandes atribuições, pelo que as aplicações bloqueiam apesar da RAM „livre“. Consultas pobres ou índices em falta aumentam desnecessariamente os acessos aos dados e aumentam as cargas de trabalho. As cargas de pico de backups, implementações, ETL ou tarefas cron agrupam os requisitos de memória em janelas de tempo curtas. As máquinas virtuais ficam sob pressão adicional quando os hosts sobrecarregam a RAM e realizam secretamente trocas de hipervisor. Ativar.
Virtualização, balonismo e excesso de compromissos
Em ambientes virtualizados, o hipervisor disfarça a situação real da RAM e baseia-se no balão e na troca dentro do Convidados. Se o anfitrião se deparar com estrangulamentos, as VMs perdem desempenho ao mesmo tempo, embora cada uma seja „verde“ por direito próprio. A paginação inteligente durante o arranque oculta os arranques a frio, mas transfere os custos para o pipeline de E/S. Verifico as métricas do anfitrião e do convidado em conjunto e reduzo o excesso de compromisso antes que os utilizadores se apercebam. Eu descrevo detalhes sobre o efeito do overcommit na secção sobre Compromisso excessivo de memória, para que o planeamento da capacidade continue a ser resiliente.
Contentores e Kubernetes: cgroups, limites e despejos
Os contentores transferem os limites de memória da VM para o cgroups. O fator decisivo é que pedidos e limites são definidos de forma realista: Os limites demasiado apertados causam mortes prematuras por falta de memória, os pedidos demasiado generosos pioram a utilização e fingem reservas. Mantenho os heaps da JVM/Node/.NET consistentemente vinculados aos limites do contentor (por exemplo, heurística de percentagem) para que o GC em tempo de execução não se depare com o cgroup.
No Kubernetes, presto atenção às classes de QoS (Guaranteed, Burstable, BestEffort) e Limiares de despejo ao nível do nó. Sob pressão de memória, o Kubelet favorece os pods BestEffort - se quiser manter os SLOs, tem de orçamentar os recursos corretamente. PSI (Pressure Stall Information) torna a pressão local do cgroup visível; eu uso esses sinais para escalar proativamente ou reprogramar pods. Para cargas de trabalho com páginas grandes, defino pedidos HugePage explícitos por pod para que o agendador selecione nós adequados.
Estratégias de otimização: Hardware e SO
Começarei pelo parafuso de ajuste mais sóbrio: mais RAM frequentemente elimina as maiores latências imediatamente. Em paralelo, reduzo as falhas de página através do THP em modo „on“ ou „madvise“, se os perfis de latência o permitirem. As páginas enormes reservadas fornecem previsibilidade para os mecanismos na memória, mas exigem um planeamento preciso da capacidade. Com vm.min_free_kbytes eu crio reservas sensatas para lidar com picos de alocação sem compensar a compactação. As actualizações do firmware e do kernel eliminam erros de borda, gestão de memória e NUMA-equilíbrio.
| Definição | Objetivo | Benefício | Nota |
|---|---|---|---|
| vm.min_free_kbytes | Reserva para picos de afetação | Menos OOM/compactação | 5-10% da RAM |
| THP (sobre/aconselhar) | Utilizar páginas maiores | Menos fragmentação | Observar as latências |
| Páginas enormes | Blocos contínuos | Atribuições previsíveis | Reserva firme de capacidade |
Bases de dados e cargas de trabalho de alojamento
As bases de dados sofrem rapidamente quando a cache do buffer diminui e as consultas são executadas devido à troca de E/S afogar. Uma definição de memória máxima limitada protege o SQL/NoSQL da deslocação mútua com a cache do sistema de ficheiros. Índices, sargabilidade e estratégias de junção personalizadas reduzem as cargas de trabalho e, portanto, a pressão da RAM. Nas configurações de alojamento, planeio os índices de pesquisa, as caches e os trabalhadores PHP FPM nas horas de ponta para que os perfis de carga não colidam. A monitorização do buffer e da expetativa de vida da página avisa-me atempadamente de Tendências descendentes.

Prática: Plano de medição e calendário de afinação
Começo com uma linha de base de 24-72 horas para que os padrões diários e os trabalhos sejam visíveis. tornar-se. Em seguida, defino um perfil-alvo para a cabeça livre de RAM, páginas aceitáveis/segundo e tempos máximos de espera de E/S. Em seguida, implemento as alterações de forma incremental: primeiro limites, depois THP/páginas grandes e, finalmente, capacidade. Meço cada alteração durante pelo menos um ciclo de carga, utilizando a mesma metodologia. Planeio antecipadamente os cancelamentos e as desconstruções para poder reagir rapidamente em caso de efeitos negativos. para redirecionar.
Testes de carga reprodutíveis e previsões de capacidade
Para tomar decisões fiáveis, reproduzo conjuntos de trabalho típicos: Caches quentes/frias, janelas de lote, picos de login/checkout. Utilizo ferramentas sintéticas (por exemplo, stress-ng para caminhos de memória, fio para E/S e benchmarks memcached/Redis para tipos de cache) para simular especificamente a pressão da memória. Executo testes em três variantes em cada caso: apenas a aplicação, aplicação + co-realizadores (backup, verificação AV), aplicação + picos de E/S. Isto permite-me reconhecer interferências que permanecem ocultas nos testes apenas com a aplicação.
Recolho painéis de métricas idênticos (memória, PSI, I/O wait, CPU steal/ready, falhas) para cada alteração. Um lançamento canário com tráfego 5-10% revela os riscos logo no início, antes de eu lançar a configuração amplamente. Para a capacidade, planeio com conjuntos de trabalho de pior caso mais reserva - não com médias suavizadas.
Resolução de problemas: Ferramentas e assinaturas
No Linux, o vmstat, o sar, o iostat, o perf e o strace fornecem-me os dados mais importantes Notas para falhas de página, tempos de espera e heaps. No lado do Windows, confio no Monitor de Desempenho, no Monitor de Recursos e nos traços do ETW. Mensagens como „compaction stalls“, „kswapd high CPU“ ou OOM kills indicam estrangulamentos graves. Interatividade flutuante, longas pausas no GC e páginas sujas crescentes confirmam a suspeita. Eu uso dumps de heap e profilers de memória para encontrar vazamentos e Atribuições.

Prática específica do Windows: Pagefile, Working Set e Paged Pools
Nos servidores Windows, asseguro uma Trocar ficheiro em SSDs rápidos e evitar configurações „sem arquivo de página“. Tamanhos mínimos fixos evitam que o sistema diminua e corte inesperadamente em horários de pico. Distribuo ficheiros de página por vários volumes, se necessário, e observo Falhas graves/seg. e a utilização dos pools paginados/não paginados.
Para serviços com uso intensivo de memória, ativo especificamente Bloquear páginas na memória (e.g. para servidores SQL) para que o kernel não empurre as cargas de trabalho para fora do conjunto de trabalho. Ao mesmo tempo, limito de forma limpa as caches de aplicações para que o sistema não se esgote de outras formas. Identifico fugas de controladores ou de pool com o PoolMon/RAMMap; em caso de falhas, um corte controlado da lista de espera ajuda a restaurar a interatividade a curto prazo - apenas como diagnóstico, não como solução permanente.
Também importante: planos de poupança de energia definidos para „desempenho máximo“, controladores e firmware de NIC/armazenamento actualizados. As peculiaridades do agendador ou os controladores de filtro desactualizados conduzem, surpreendentemente, a picos de memória e de E/S, que eu poderia interpretar erradamente como uma pura falta de RAM.
Utilizar sabiamente THP, NUMA e tamanhos de página
As Transparent Huge Pages reduzem a pressão da TLB, mas as promoções esporádicas podem causar picos de latência produzir. Para cargas de trabalho com SLOs rigorosos, confio frequentemente em „madvise“ ou páginas enormes fixas. O balanceamento NUMA compensa em sistemas multi-socket se as threads e a memória permanecerem locais. Eu coloco serviços em nós NUMA e monitoro as taxas de falha locais. Páginas enormes aumentam a taxa de transferência, mas eu verifico a fragmentação interna para que eu não tenha oferecer.
Cache do sistema de ficheiros, mmap e caminhos de E/S
Uma grande parte da memória „livre“ está no Cache de página. Eu tomo uma decisão consciente sobre se um motor utiliza a cache do SO (E/S com buffer) ou se faz a sua própria cache (E/S direta). As caches duplas desperdiçam RAM; se a cache do SO estiver em falta antecipar-latências. Para cargas de trabalho de stream, posso aumentar o readahead por dispositivo; as bases de dados aleatórias e pesadas funcionam melhor com E/S direta.
# Exemplo: Aumentar o readahead para 256 sectores
blockdev --setra 256 /dev/nvme0n1
E/S mapeadas na memória (mapa) poupa cópias, mas transfere a pressão para a cache de páginas. Em casos excepcionais, eu fixo páginas críticas com mlock (ou ulimites de memlock) para evitar a instabilidade devida à recuperação - tendo sempre em atenção as reservas do sistema.
Medidas de emergência rápidas para a pressão da memória
- Identificar os principais consumidores (ps/top/procdump) e reiniciar ou reprogramar, se necessário.
- Acelerar temporariamente a concorrência (trabalhadores/threads) para reduzir a taxa de falhas e o writeback.
- Reduzir os limites de sujidade a curto prazo, de modo a que a redução de valor produza efeitos mais cedo e as reservas sejam libertadas.
- Para o sobrecomprometimento de contentores, evacuar pods específicos; aumentar temporariamente os recursos em VMs ou relaxar o balonismo.
- Verificar a estratégia OOM: ativar systemd-oomd/earlyoom e cgroup-para que os processos „certos“ sejam executados primeiro.
Planeamento da capacidade e custos
A RAM custa dinheiro, mas as falhas repetidas custam receitas e Reputação. Para servidores Web e de bases de dados, costumo calcular uma reserva de 20-30% para cobrir picos raros. Um módulo adicional de 64 GB por 180-280 euros é frequentemente amortizado mais rapidamente do que o combate constante a incêndios. Em ambientes de nuvem, evito o overbooking e reservo os buffers em fases que correspondam aos padrões de carga. Os cálculos sóbrios do TCO superam os gráficos bonitos porque têm em conta os danos causados pela latência e o tempo do operador. preço em.

Brevemente resumido
A Servidor de paginação de memória beneficia mais de RAM suficiente, uma configuração limpa de THP/páginas grandes e um overcommit realista. Confio em indicadores claros, como MBytes disponíveis, Bytes acedidos e Páginas/segundo. Verifico novamente os ambientes virtualizados para que o ballooning e o swap do host não roubem o desempenho oculto. Mantenho as bases de dados longe da swap com caches e limites definidos. Se implementar estes passos de forma consistente, reduzirá as latências, evitará o thrashing e manterá o Desempenho estável durante os picos de carga.


