 Перейти к содержимому
Перейти к содержимому 
A Сервер подкачки памяти может значительно сократить время отклика и пропускную способность под нагрузкой, если слишком много страниц перемещается из оперативной памяти в своп. В этой статье я расскажу вам о причинах, измеренных значениях и конкретных настройках, которые можно сделать, чтобы замедлить подкачку и заметно увеличить производительность сервера.
Центральные пункты
Чтобы четко сориентироваться, я кратко изложу основные идеи и покажу, где находятся типичные "узкие места" и как их устранить. Высокая скорость пейджинга обходится дорого Производительность, поскольку доступ к носителю данных происходит гораздо медленнее, чем к оперативной памяти. Такие измеряемые величины, как доступные мегабайты, доступные байты и страницы в секунду, обеспечивают мне надежную информацию. Сигналы для неминуемого разрушения. Виртуализация усугубляет эффект подкачки за счет раздувания и подкачки гипервизора, когда хосты перегружены. Я уменьшаю количество ошибок страниц с помощью обновления оперативной памяти, THP/огромных страниц, настройки NUMA и чистых шаблонов распределения. Регулярный мониторинг позволяет Риски и позволяет рассчитать пики нагрузки.
- Своп против оперативной памятиНаносекунды в оперативной памяти против микро-/миллисекунд на носителях данных
- Thrashing: Передачи страниц больше, чем полезной работы, задержки растут
- Фрагментация: Большие выделения не работают, несмотря на „свободную“ память
- ИндикаторыДоступные мегабайты, доступные байты, страницы/сек.
- ТюнингTHP/Huge Pages, vm.min_free_kbytes, NUMA, RAM

Как работает пейджинг на серверах
Я разделяю виртуальную и физическую память на фиксированные страницы, обычно по 4 КБ, что является MMU с помощью таблиц страниц. Если оперативной памяти становится мало, операционная система перемещает неактивные страницы в область подкачки или своп. Каждый сбой страницы заставляет ядро извлекать данные из носителя информации и расходует ценную оперативную память. Время. Большие страницы, такие как Transparent Huge Pages (THP), уменьшают усилия по администрированию и минимизируют пропуски TLB. Новичкам стоит обратить внимание на виртуальная память, чтобы лучше понять взаимоотношения между процессами, фреймами страниц и подкачкой.
Swap против RAM: задержки и треш
Оперативная память реагирует на запросы за наносекунды, в то время как SSD/HDD - за микро- и миллисекунды, а значит, на порядки быстрее. медленнее являются. Если нагрузка превышает объем физической рабочей памяти, скорость подкачки увеличивается, и процессор ожидает ввода-вывода. Этот эффект может легко привести к трэшингу, когда на свопинг тратится больше времени, чем на продуктивную работу. Труд теряется. Особенно при использовании 80-90% ухудшается интерактивность и удаленные сессии. Я проверяю Использование свопов и провести границы до того, как система перевернется.

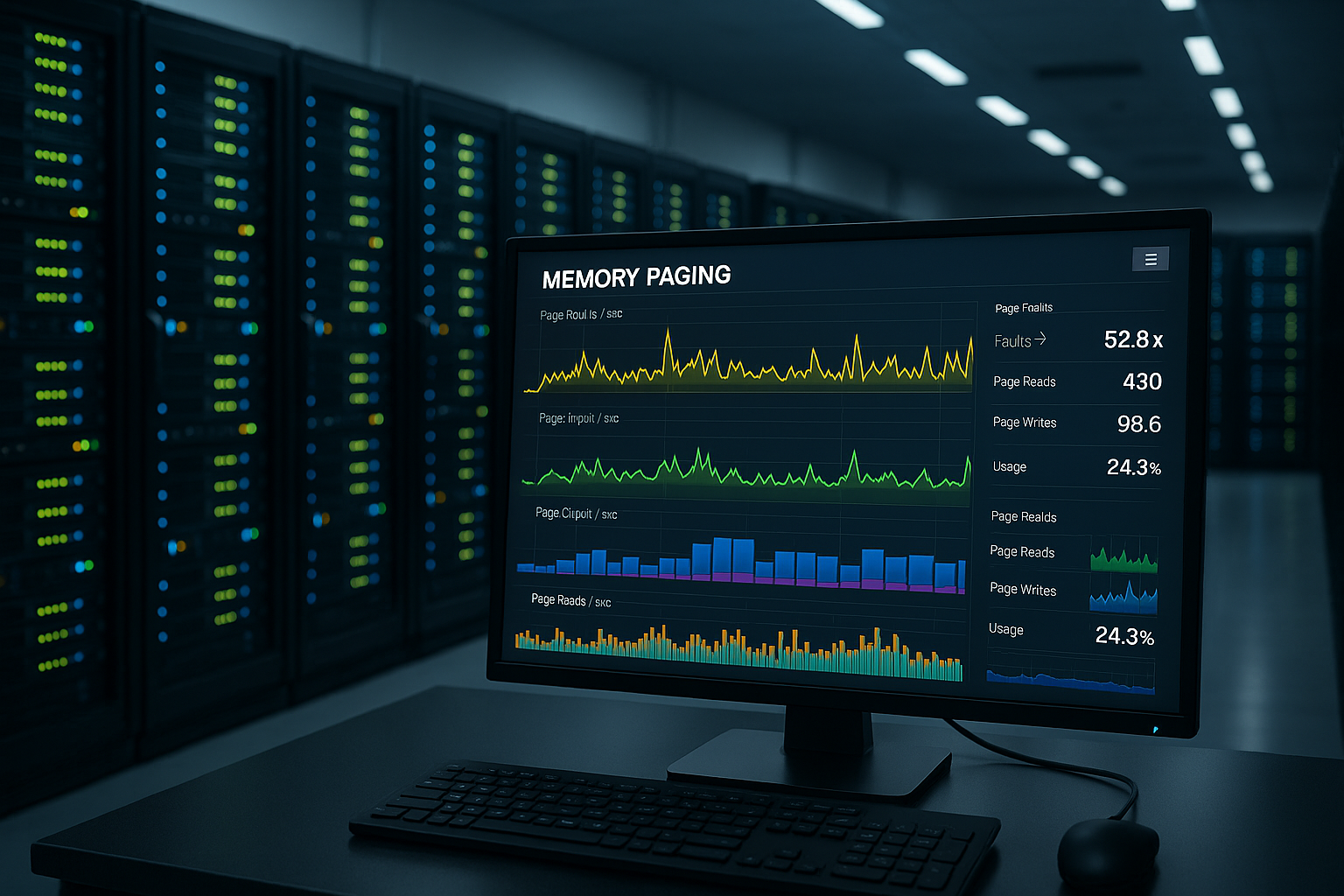
Индикаторы и пороговые значения
Чистые измеренные значения позволяют принимать решения RAM и настройке. В Windows я обращаю внимание на доступные мегабайты, cessed Bytes, Pages/Second и Pool paged/nonpaged bytes. В Linux я проверяю vmstat, free, sar, ps meminfo и dmesg на наличие событий, связанных с нехваткой памяти. Увеличение проблем со страницами при уменьшении свободных мегабайт указывает на приближающиеся узкие места. Я планирую критические пороги консервативно, чтобы избежать пиков нагрузки без Кража со взломом перехватить.
| Показатель эффективности | Здоровый | предупреждение | Критический |
|---|---|---|---|
| \Memory\Pool страничные байты / нестраничные байты | 0-50% | 60-80% | 80-100% |
| Доступные мегабайты | >10% или 4 ГБ | <10% | <1% или <500 МБ |
| % Сохраненные байты | 0-50% | 60-80% | 80-100% |
Linux: своппинг, параметры Zswap/ZRAM и обратная запись
В дополнение к THP/Huge Pages я заметно уменьшаю подкачку, контролируя агрессивность свопинга и обратной записи. vm.swappiness управляет тем, как рано ядро забрасывает страницы в своп. На серверах с большим количеством оперативной памяти я обычно использую 1-10, чтобы кэш страниц оставался большим и неактивные кучи не мигрировали преждевременно. На очень скудных системах чуть большее значение может спасти интерактивность, поскольку кэш не высыхает полностью - решающим фактором является измерение под реальной нагрузкой.
С Zswap (сжатый своп в оперативной памяти), я снижаю нагрузку на ввод-вывод, если в течение короткого времени имеется много холодных страниц. Это стоит циклов процессора, но часто дешевле, чем блочный ввод-вывод. Для периферийных или лабораторных систем я иногда использую ZRAM в качестве основного свопа для повышения надежности небольших хостов; я использую его целенаправленно в производстве, когда есть свободное место для процессора.
Я управляю путями записи через vm.dirty_*-параметры. Вместо процентных значений я предпочитаю работать с абсолютными байтами, чтобы избежать штормов записи при большом объеме оперативной памяти. Фоновая промывка начинается достаточно рано, в то время как грязные_байты устанавливает жесткие верхние границы для ленивых рабочих нагрузок. Примеры значений, которые я использую в качестве отправной точки:
# сдержанный свопинг
sysctl -w vm.swappiness=10
# Проверьте обратную запись (в байтах, а не в процентах)
sysctl -w vm.dirty_background_bytes=67108864 # 64 МБ
sysctl -w vm.dirty_bytes=268435456 # 256 МБ
# Не удаляйте кэш VFS слишком активно
sysctl -w vm.vfs_cache_pressure=50
На сайте Сменный дизайн Я предпочитаю быстрые NVMe-устройства и устанавливаю приоритеты так, чтобы ядро использовало сначала самый быстрый своп. Выделенное устройство подкачки предотвращает фрагментацию файлов подкачки.
# Проверка приоритетов подкачки
swapon --show
Включите своп # на быстром устройстве с высоким приоритетом
swapon -p 100 /dev/nvme0n1p3
Важно: я соблюдаю крупные/мелкие неисправности и глубину очереди ввода-вывода параллельно - только так я могу определить, сглаживает ли уменьшение swappiness или Zswap реальные пики задержки.
Причины высокой скорости пейджинга
Если физическая рабочая память отсутствует, байты доступа увеличиваются за счет встроенной памяти. RAM и система переключается на своп. Фрагментированная память затрудняет выделение больших объемов, поэтому приложения блокируют, несмотря на „свободную“ оперативную память. Плохие запросы или отсутствующие индексы неоправданно увеличивают количество обращений к данным и повышают рабочую нагрузку. Пиковые нагрузки, связанные с резервным копированием, развертыванием, ETL или заданиями cron, приводят к тому, что требования к памяти укладываются в короткие временные окна. Виртуальные машины испытывают дополнительное давление, когда хосты перерасходуют оперативную память и тайно выполняют подмены гипервизора. Активируйте.
Виртуализация, раздувание и чрезмерная нагрузка
В виртуальных средах гипервизор маскирует реальную ситуацию с оперативной памятью и полагается на раздувание и замену внутри Гости. Если хост сталкивается с узкими местами, ВМ одновременно теряют производительность, хотя каждая из них „зеленая“ сама по себе. Умная подкачка страниц при загрузке скрывает холодные старты, но перекладывает затраты на конвейер ввода-вывода. Я проверяю метрики хоста и гостя вместе и уменьшаю перерасход ресурсов до того, как это заметят пользователи. Я подробно рассказываю о влиянии избыточной коммисии в разделе о Избыточное использование памяти, чтобы планирование мощностей оставалось устойчивым.
Контейнеры и Kubernetes: cgroups, ограничения и выселения
Контейнеры переносят ограничения на хранение данных с ВМ на cgroups. Решающим фактором является то, что запросы и ограничения установлены реалистично: Слишком жесткие лимиты приводят к раннему выходу из памяти, слишком щедрые запросы ухудшают утилизацию и создают видимость резервов. Я держу кучи из JVM/Node/.NET последовательно связанными с ограничениями контейнера (например, процентной эвристикой), чтобы runtime GC не сталкивался с cgroup.
В Kubernetes я обращаю внимание на классы QoS (Guaranteed, Burstable, BestEffort) и Пороги выселения на уровне узла. В условиях нехватки памяти Kubelet отдает предпочтение стручкам BestEffort - если вы хотите сохранить SLO, вам нужно правильно распределить ресурсы. PSI (Pressure Stall Information) делает видимым локальное давление cgroup; я использую эти сигналы для упреждающего масштабирования или изменения расписания стручков. Для рабочих нагрузок с большими страницами я определяю явные запросы HugePage для каждого стручка, чтобы планировщик выбирал подходящие узлы.
Стратегии оптимизации: Аппаратное обеспечение и ОС
Начну с самого трезвого винта регулировки: больше RAM часто сразу же устраняет самые большие задержки. Параллельно я уменьшаю количество ошибок страниц с помощью THP в режиме „on“ или „madvise“, если это позволяют профили задержек. Зарезервированные огромные страницы обеспечивают предсказуемость для движков in-memory, но требуют точного планирования емкости. С помощью vm.min_free_kbytes я создаю разумные резервы, чтобы справиться с пиками выделения без компенсирующего уплотнения. Обновления прошивки и ядра устраняют ошибки на границах, управление памятью и NUMA-Баланс.
| Настройка | Цель | Выгода | Подсказка |
|---|---|---|---|
| vm.min_free_kbytes | Резерв для пиков распределения | Меньше OOM/уплотнений | 5-10% оперативной памяти |
| ТГП (на/советуйте) | Используйте большие страницы | Меньше фрагментации | Наблюдайте за задержками |
| Огромные страницы | Непрерывные блоки | Предсказуемое распределение | Твердое резервирование мощностей |
Базы данных и хостинг рабочих нагрузок
Базы данных быстро страдают, когда буферный кэш уменьшается, а запросы выполняются из-за подкачки в ВВОД/ВЫВОД утонуть. Жестко ограниченное значение максимальной памяти защищает SQL/NoSQL от взаимного вытеснения с кэшем файловой системы. Индексы, sargability и настраиваемые стратегии join снижают рабочую нагрузку и, соответственно, давление на оперативную память. В хостинговых системах я планирую поисковые индексы, кэши и рабочие PHP FPM в пиковые моменты, чтобы профили нагрузки не сталкивались. Мониторинг буфера и продолжительности жизни страниц предупреждает меня о том, что Тенденции к снижению.

Практика: План измерений и график настройки
Я начинаю с базовой линии в 24-72 часа, чтобы были видны ежедневные паттерны и работа. стать. Затем я устанавливаю целевой профиль для свободного объема оперативной памяти, допустимого количества страниц в секунду и максимального времени ожидания ввода-вывода. Затем я постепенно ввожу изменения: сначала лимиты, затем THP/огромные страницы, наконец, емкость. Я измеряю каждое изменение в течение как минимум одного цикла нагрузки, используя ту же методологию. Я заранее планирую отмены и деконструкции, чтобы иметь возможность быстро отреагировать в случае негативных последствий. перенаправить.
Воспроизводимые испытания на нагрузку и прогнозы производительности
Для получения надежных решений я воспроизвожу типичные рабочие наборы: теплые/холодные кэши, пакетные окна, пики входа/выхода. Я использую синтетические инструменты (например, stress-ng для путей памяти, fio для ввода-вывода и memcached/Redis benchmarks для типов кэша), чтобы специально смоделировать нагрузку на память. В каждом случае я провожу тесты в трех вариантах: только приложение, приложение+сопроводительные программы (резервное копирование, AV-сканирование), приложение+пики ввода-вывода. Это позволяет выявить помехи, которые остаются скрытыми в тестах только для приложений.
Я собираю идентичные панели метрик (память, PSI, ожидание ввода/вывода, кража/готовность процессора, сбои) для каждого изменения. Канареечное развертывание с трафиком 5-10% позволяет выявить риски на ранней стадии, прежде чем я широко разверну конфигурацию. Что касается пропускной способности, я планирую рабочие наборы для наихудшего случая плюс резерв - а не сглаженные средние значения.
Устранение неполадок: инструменты и подписи
В Linux vmstat, sar, iostat, perf и strace предоставляют мне наиболее важные данные. Примечания для обнаружения ошибок страниц, времени ожидания и кучи. На стороне Windows я полагаюсь на Performance Monitor, Resource Monitor и трассировки ETW. Такие сообщения, как „compaction stalls“, „kswapd high CPU“ или OOM kills, указывают на серьезные узкие места. Колебания интерактивности, длительные паузы GC и растущие грязные страницы подтверждают подозрения. Я использую дампы кучи и профилировщики памяти, чтобы найти утечки и неуместные Распределение.

Практика, специфичная для Windows: Pagefile, Working Set и Paged Pools
На серверах Windows я обеспечиваю достаточный размер Файл подкачки на быстрых SSD и избегайте настроек „без страничного файла“. Фиксированные минимальные размеры предотвращают неожиданное сжатие и обрезание системы в пиковые моменты. При необходимости я распределяю файлы страниц по нескольким томам и соблюдаю Неисправности/сек и использование пулов paged/nonpaged.
Для служб, требующих много памяти, я специально активирую Блокировка страниц в памяти (например, для SQL-серверов), чтобы ядро не вытесняло рабочие нагрузки из рабочего набора. В то же время я четко ограничиваю кэши приложений, чтобы система не пересыхала другими способами. Я выявляю утечки драйверов или пулов с помощью PoolMon/RAMMap; в случае неполадок контролируемое сокращение резервного списка помогает восстановить интерактивность в краткосрочной перспективе - только как диагностика, а не как постоянное решение.
Также важны: планы энергосбережения, установленные на „максимальную производительность“, актуальные драйверы и прошивки сетевой карты/хранилища. Причуды планировщика или устаревшие драйверы фильтров удивительно часто приводят к пикам памяти и ввода-вывода, которые я могу неверно истолковать как чистую нехватку оперативной памяти.
Разумно используйте THP, NUMA и размеры страниц
Прозрачные огромные страницы уменьшают нагрузку на TLB, но спорадическое продвижение может вызвать скачки задержки производить. Поэтому для рабочих нагрузок с жесткими SLO я часто полагаюсь на „madvise“ или фиксированные огромные страницы. Балансировка NUMA оправдывает себя в многосокетных системах, если потоки и память остаются локальными. Я прикрепляю сервисы к узлам NUMA и отслеживаю локальные пропуски. Огромные страницы увеличивают пропускную способность, но я проверяю внутреннюю фрагментацию, чтобы не допустить отдавать.
Кэш файловой системы, mmap и пути ввода/вывода
Большая часть „свободной“ памяти находится в Кэш страниц. Я принимаю осознанное решение о том, использует ли движок кэш ОС (буферизованный ввод/вывод) или кэширует сам (прямой ввод/вывод). Двойной кэш тратит оперативную память; если кэш ОС отсутствует readahead-латентности. Для потоковых рабочих нагрузок я могу увеличить readahead для каждого устройства; базы данных со случайными нагрузками лучше работают с прямым вводом-выводом.
# Пример: Увеличение объема чтения до 256 секторов
blockdev --setra 256 /dev/nvme0n1
Ввод/вывод с привязкой к памяти (mmap) сохраняет копии, но перекладывает нагрузку на кэш страниц. В исключительных случаях я закрепляю критические страницы с помощью mlock (или memlock ulimits), чтобы избежать дребезжания из-за возврата - всегда с учетом системных резервов.
Быстрые экстренные меры при давлении на память
- Определите основные потребители (ps/top/procdump) и при необходимости перезапустите или перенесите.
- Временно ограничьте параллелизм (рабочие/потоки), чтобы снизить частоту отказов и обратную запись.
- Сократите грязные лимиты в краткосрочной перспективе, чтобы списание наступило раньше и резервы были высвобождены.
- При избыточном коммитировании контейнеров эвакуируйте определенные подсистемы; временно увеличьте ресурсы на виртуальных машинах или ослабьте вздутие.
- Проверьте стратегию OOM: активируйте systemd-oomd/earlyoom и cgroup-запускается так, чтобы „правильные“ процессы шли первыми.
Планирование мощностей и затраты
Оперативная память стоит денег, но повторяющиеся сбои приносят убытки и Репутация. Для веб-серверов и серверов баз данных я обычно рассчитываю резерв в 20-30% для покрытия редких пиков. Дополнительный модуль на 64 ГБ за 180-280 евро зачастую амортизируется быстрее, чем постоянное пожаротушение. В облачных средах я избегаю избыточного резервирования и бронирую буферы поэтапно, в соответствии с графиком нагрузки. Трезвые расчеты TCO выигрывают у красивых графиков, поскольку учитывают ущерб от задержек и время оператора. цена в.

Краткое резюме
A Сервер подкачки памяти больше всего выигрывает от достаточного количества оперативной памяти, чистой настройки THP/huge page и реалистичного overcommit. Я полагаюсь на четкие показатели, такие как доступные мегабайты, доступные байты и страницы/секунду. Я дважды проверяю виртуализованные среды, чтобы сдувание и своп хоста не украли скрытую производительность. Я держу базы данных подальше от свопа, используя определенные кэши и ограничения. Если вы будете последовательно выполнять эти шаги, вы уменьшите задержки, предотвратите трешинг и сохраните Производительность стабильность при пиковых нагрузках.


