 Перейти к содержимому
Перейти к содержимому 
Я расставляю приоритеты Приоритет почтовой очереди непосредственно в MTA, чтобы критически важные сообщения доставлялись быстро даже во время пиковых нагрузок. Благодаря отдельным очередям, SMTP-планированию, разумным обратным связям и постоянному мониторингу я поддерживаю высокую пропускную способность и низкий уровень ошибок.
Центральные пункты
- Приоритеты отдельно: Высокая, средняя и низкая очереди для предсказуемого поведения доставки
- SMTP Управление: параллелизм, ограничения скорости, адаптивные отступления
- Параметры Тонкая настройка: задержка_запуска_очереди, время обратного хода, лимиты процессов
- Мониторинг установить: mailq, qshape, журналы, сигналы тревоги
- Масштабирование безопасно: планирование мощностей, кластер, разделение IP-адресов

Почему приоритет почтовой очереди имеет значение
Пики нагрузки возникают внезапно и без четкого Расстановка приоритетов важные письма задерживаются. Счета, коды 2FA и системные предупреждения я отношу к высокоприоритетной очереди, а рассылкам даю более длительные отсрочки. Таким образом я отделяю срочные рассылки от массовых и сокращаю время ответа. Четкий план расстановки приоритетов сокращает количество повторных попыток, защищает репутацию IP-адреса и сокращает цепочку доставки. Чем четче правила, тем меньше административной работы в операциях. Это позволяет сократить количество тайм-аутов и предотвратить блокировки из-за медленных пунктов назначения. Такой продуманный контроль создает надежную Производительность в течение всего дня.
Понимание и использование очередей Postfix
Postfix разделяется на Активный, Отложенная, удерживаемая и входящая; я использую эту логику в качестве основы для своего дизайна. Активная очередь обрабатывает почту немедленно, отложенная очередь буферизует проблемы с доставкой с обратным ходом. Я использую Hold для замораживания сообщений по первому требованию, например, перед плановым обслуживанием. Я определяю, какие письма попадают в ту или иную очередь, и связываю это с ограничениями параллелизма для каждой цели. Параметры повторных попыток, такие как минимальное_время_возврата и максимальное_время_возврата, адаптируются к трафику. При умеренной нагрузке я устанавливаю queue_run_delay на 3-10 секунд; при пиковой нагрузке я намеренно увеличиваю этот интервал. Это позволяет сохранить Нагрузка на сервер контролируемой, пока продолжаются важные поставки.

Приоритеты: высокий, средний, низкий с отдельными очередями
Я создаю три уровня: Высокий для критический Почта, средняя для обычного трафика, низкая для массовой рассылки. Transport_maps и header_checks назначают письма на основе отправителя, тегов темы или групп получателей. При необходимости я разделяю экземпляры, чтобы нагрузка на рассылку никогда не касалась высокого трафика. Я назначаю собственные лимиты параллелизма для каждого уровня и сокращаю обратную связь для высокого уровня, в то время как низкий уровень намеренно ждет дольше. Четкий каталог правил предотвращает неправильную классификацию и позволяет быстро проводить аудит. Для получения более подробных советов по внедрению я использую компактный Руководство по управлению очередью. Таким образом, управление остается понятным, и я добиваюсь последовательного Доставка.
Планирование SMTP: параллелизм, ограничение скорости и адаптивные обратные связи
Я определяю smtp_destination_concurrency_limit для каждого домена, обычно 5-20, чтобы избежать медленных пунктов назначения. переехать. Если сервер достигает 421/451, я динамически увеличиваю время обратного хода и временно снижаю параллелизм. При медленном старте я устанавливаю соединения шаг за шагом и проверяю, что может выдержать другая сторона. Ограничение скорости защищает меня от самоперегрузки и поддерживает репутацию IP-адреса. При повторяющихся пиках я передаю низкоприоритетные объемы на аутсорсинг с временной задержкой. Четкие инструкции можно найти в коротком Руководство по ограничению тарифов, который я использую в качестве контрольного списка. Это помогает Дросселирование последовательным и понятным.

Настройка параметров: значения, влияние и практические диапазоны
Я выбираю консервативные начальные значения и тестирую при Загрузить, Я держу задержку очереди (queue_run_delay) короткой, пока у процессора и ввода-вывода есть резервы; я постепенно увеличиваю ее в случае перегрузки. минимальное время отката (minimum_backoff_time) контролируется по приоритету, высокий значительно короче низкого. максимальное время отката (maximum_backoff_time) учитывает ограничения приемника, чтобы повторные попытки не были бесполезными. время жизни очереди (bounce_queue_lifetime) поддерживается коротким, чтобы файловая система и журналы были чистыми. лимит_процесса_по_умолчанию выравнивается с доступной оперативной памятью и масштабируется в соответствии с измеренными значениями. Эти параметры взаимодействуют, поэтому я измеряю их влияние после каждого изменения, прежде чем продолжить работу.
| Параметры | Значение | Рекомендуемый диапазон | Практический совет |
|---|---|---|---|
| очередь_запуска | Тестовый интервал Отложено/активно | 3-30 секунд | Приспосабливайтесь к нагрузкам, появляйтесь на пиках |
| минимальное_время_отката | Минимальное время ожидания повторной попытки | 300-900 секунд | С дроссельной заслонкой - гораздо выше. |
| максимальное_время_отката | Максимальное время ожидания повторной попытки | 3600-7200 секунд | Соблюдайте ограничения получателя |
| bounce_queue_lifetime | Время жизни отказов | 2-5 дней | Следите за тем, чтобы катушка и журналы не были изношены |
| default_process_limit | Параллельные процессы | Зависит от оперативной памяти, до ~100 | Тестирование и итерации под нагрузкой |
| smtp_destination_concurrency_limit | Соединения на домен | 5-20 | Строго дросселируйте медленные цели |
Политики предварительной очереди и чистая классификация
Я переношу расстановку приоритетов в конвейер как можно раньше. Предварительные проверки (служба политик, header_checks, milter) отмечают письма до того, как они попадают в активную очередь. Аутентифицированные отправители, внутренние системы и известные учетные записи служб предпочтительно получают высокий уровень, в то время как отправители неизвестных кампаний по умолчанию попадают в низкий. Для надежности я комбинирую несколько сигналов: статус SASL-аута, IP-адрес отправителя, отправитель конверта, List-Id, Приоритет-заголовки и теги темы. Я распознаю автоответчики через Автоматическая отправка и изменить приоритеты, чтобы они не занимали критический путь. Важно, чтобы решение оставалось детерминированным: Если правила и модели расходятся, побеждает консервативное правило.
Я регистрирую назначение в явном виде в заголовке X-Priority или X-Queue. Это облегчает аудит и последующие исправления. Я могу отфильтровать и переобучить неправильные классификации, чтобы они не затерялись в шуме. В случае возникновения проблем я заставляю сообщения приостановиться с помощью Hold, проверяю причины в заголовке и затем позволяю им переместиться в соответствующую очередь.
Расположение нескольких экземпляров и переопределение на каждом уровне
Для жесткого разделения я люблю использовать Зеркальные экземпляры для каждого приоритета: отдельный раздел master.cf с различными переопределениями -o. Таким образом, высокие, средние и низкие потоки получают разные лимиты smtp_*, обратную связь и профили TLS, не мешая друг другу. Я делаю конфигурацию для каждого уровня как можно короче и ссылаюсь на общие значения по умолчанию; я задаю только те отклонения, которые действительно должны быть дифференцированы. Таким образом, работа становится понятной, а изменения глобальных параметров имеют последовательный эффект.
При очень больших объемах перевозок я также разделяю их по клиентам: Один клиент, одна очередь или один транспортный маршрут. Сайт Справедливость Я использую бюджеты для каждого клиента и приоритеты, чтобы никто не использовал все ресурсы незаметно. Если клиент превышает лимиты или попадает в списки блокировки, разделение экземпляров изолирует эти эффекты от всех остальных.
Настройка спула, хранилища и операционной системы
Производительность очереди в значительной степени зависит от Хранение и параметры ОС. Я размещаю спул на быстрых SSD и отделяю журнал/метаданные от пользовательских данных, если файловая система от этого выигрывает. Многие маленькие файлы требуют много инодов - я планирую их щедро, чтобы не попасть в искусственные ограничения. Опции монтирования, такие как noatime, уменьшают количество ненужных обращений к записи. Для активной очереди важны низкие задержки; отложенная, с другой стороны, может быть несколько медленнее, если пропускная способность соответствует требованиям.
Я слежу за iowait, глубиной очереди на уровне блоков и фрагментацией ФС. Если активный спул регулярно перегревается, помогает минимизация числа процессов и небольшое увеличение обратных связей. Это помогает бороться с блокировкой головной линии в хранилище. В виртуализированных средах я обращаю внимание на ограничения cgroup и настройки планировщика справедливого ввода-вывода, чтобы фазы серийной обработки не голодали на гипервизоре. Я делаю инкрементные резервные копии спула и последовательный (короткое замораживание), чтобы не зацепить полузаконченные файлы.

Справедливость, защита от голода и бюджеты
Я также хотел бы расставить приоритеты Голодание избегайте: Высокий приоритет никогда не должен блокировать все. Я работаю с легкими окнами квот (например, 80/15/5 для высокого/среднего/низкого) и запускаю доли со всех уровней в каждом цикле. Если высокий приоритет пуст, средний наследует его долю - но никогда не наоборот. Я также справедливо распределяю слоты для каждого целевого домена, чтобы ни один домен не доминировал во всей рассылке. В фазах с обратным давлением я быстро снимаю низкоприоритетные и даю высокоприоритетным короткий бонус, пока показатели задержки не вернутся к целевым.
Я настраиваю "бакеты" токенов на уровне клиента: высокоприоритетные токены пополняются быстрее, низкоприоритетные - медленнее. Избыток токенов истекает, так что старые кредиты не распознаются как Шторм внезапно переполняют очередь. Эта строгая, но простая логика позволяет поддерживать стабильность системы, не требуя от меня постоянного ручного вмешательства.
Разогрев репутации, "зеленые списки" и дефектные цели
Я согреваю новые IP шаг за шагом Сначала только высокий приоритет с несколькими параллельными соединениями на большой целевой домен, затем средний и, наконец, низкий. Таким образом, получатели знакомятся с характеристиками отправителя при добродушной нагрузке. При использовании greylisting я намеренно позволяю низкоприоритетным ждать дольше и не увеличиваю количество повторных попыток - это экономит и ресурсы, и репутацию.
Неисправные пункты назначения я рассматриваю отдельно. Если MX-записи не работают или хосты реагируют очень медленно, я изолирую домен в маршруте с дросселированием и снижаю smtp_destination_concurrency_limit до минимального значения. В то же время я умеренно увеличиваю верхний предел обратного хода, чтобы избежать ненужных попыток соединения. Таким образом, я не позволяю отдельным целевым сетям замедлять общую диспетчеризацию.
Расширенная наблюдаемость: SLI, SLO и диагностические пути
Я определяю четкие SLIs (например, время доставки P50/P95 для каждого приоритета, частота ошибок для целевого домена, среднее количество повторных попыток) и на основе этого определять SLO. Сигналы тревоги основаны не только на пороговых значениях, но и на Переломы трендаЕсли задержки P95 увеличиваются быстрее, чем обычно, я реагирую до того, как нарушаются абсолютные границы. Пути диагностики документированы: От тревоги → qshape → затронутые домены → журналы с расширенными ID-корреляциями → конкретные действия. После исправления я проверяю, вернулись ли метрики в нормальные диапазоны.
Я также отмечаю классы ответов SMTP (2xx/4xx/5xx) для анализа первопричины. по приоритету и домена. Если на маршруте накапливается 421/451, я временно удаляю его из высокого пути, пока пункт назначения снова не заработает должным образом. Такая коррекция, основанная на метрике, позволяет избежать неверных предположений и сразу показывает, работают ли мои ограничения.
Планы обеспечения устойчивости, возобновления работы и чрезвычайных ситуаций
Я планирую повторный запуск после сбоев, как после контролируемого оттаивания: высокоприоритетные получают повышенное внимание на короткое время, низкоприоритетные остаются приглушенными, пока отложенная очередь не сократится до нормального размера. postsuper помогает упорядочить повторную очередь; я выявляю поврежденные записи на ранней стадии и удаляю их с помощью четких правил, чтобы они не попадали в бесконечные циклы.
У меня есть документированная миграция спула, готовая к катастрофам. Она включает свободные иноды и пространство для хранения в месте назначения, синхронизированные конфигурации и пошаговое переключение DNS/транспорта. Я регулярно тестирую этот путь на небольших масштабах, чтобы не было никаких сюрпризов в случае чрезвычайной ситуации. Подготовлены аварийные контакты с крупными получателями (например, адреса злоумышленников/постмастеров) на случай ускорения ошибочной классификации или падения репутации.

Автоматизированные тесты, Canary и безопасное развертывание
Сначала я задаю новые параметры через Канарские экземпляры на. Небольшая, репрезентативная часть трафика показывает, работают ли бэкофф, параллелизм или queue_run_delay так, как планировалось. Синтетические транзакции (тестовые письма с заданными целями) измеряют время выполнения от конца до конца независимо от повседневной работы. Только когда показатели стабильны, я поэтапно внедряю изменения. В случае регресса я быстро возвращаюсь к последним метрикам с помощью заранее протестированного отката. хорошо ценности.
Я автоматизирую конфигурацию с помощью контроля версий и проверяемых наборов изменений. Каждому внедрению дается краткая гипотеза („Ожидаемое снижение P95 на 10 % при высоком уровне“) и период измерения. Таким образом, команда постоянно учится, а я избегаю дублирования или противоречивых шагов по настройке.
Оптимизация сети: избегайте DNS, таймаутов и головной линии.
Я использую местные Резольвер чтобы ускорить поиск MX и A и увеличить количество просмотров кэша. smtp_per_record_deadline ограничивает время ожидания для каждой записи DNS и не позволяет медленному хосту замедлять всю очередь. Я выбираю консервативные таймауты для connect, helo и data, чтобы рабочие не застревали. Я проверяю рукопожатия TLS на задержки и сокращаю ненужные расходы на шифр. Я слежу за сетевыми путями с помощью метрик MTR и задержек, чтобы выявить узкие места на ранней стадии. Отдельные IP-адреса для каждого уровня приоритета помогают четко разделить репутацию и изолировать эффекты greylisting. Это позволяет поддерживать низкие задержки и Пропускная способность планируемый.
Последовательность операций: замораживание/оттаивание, плавный отскок и контролируемое обслуживание
Для обслуживания окон я переключаю мягкий_прыжок замораживать низкоприоритетные и сокращать высокоприоритетные. Я использую постсупер специально для удержания/освобождения, не нарушая продуктивных потоков. Перед вмешательством я снижаю параллелизм, освобождаю критические очереди и планирую фиксированное время оттаивания. Последующая работа включает просмотр журналов, сравнение qshape до/после мероприятия и установление новых ограничений. Я могу на короткое время увеличить queue_run_delay, чтобы смягчить последствия спешки после оттепели. Это позволяет держать обслуживание под контролем, а уровни обслуживания - измерять. Я документирую каждый шаг, чтобы впоследствии аудиторы могли проанализировать Решения понимать.
Масштабирование и планирование мощностей в хостинге
Я рассчитываю размер спула исходя из ожидаемого количества пиковых писем в минуту. Время ожидания плюс буфер. Для пиков, обусловленных кампаниями, я разделяю очереди по группам клиентов, чтобы критический трафик никогда не блокировался. Кластеры с отдельными приоритетными IP-адресами повышают надежность и развязывают репутацию. Горизонтальное масштабирование работает лучше, если я поддерживаю единые правила для каждого уровня. Я планирую пропускную способность поэтапно, измеряю и расширяю только после того, как измеренные значения становятся стабильными. Я перемещаю рассылки в непиковое время или на внешние каналы, чтобы обеспечить резерв для высокого приоритета. Таким образом, доставка становится предсказуемой, а Наличие высокий.
Категоризация с поддержкой искусственного интеллекта: автоматическая расстановка приоритетов экономит время
Я оставляю модели отправителя, маркеры темы и характеристики содержимого. анализировать и автоматически назначать приоритеты. Правила по-прежнему действуют, но ИИ сокращает время сортировки в повседневной работе. Я собираю ошибочные классификации и переобучаюсь до тех пор, пока точность и отзыв не станут правильными. В целях безопасности я маскирую конфиденциальный контент перед его оценкой. Конвейер записывает причины в заголовки или журналы, чтобы я мог проверить решения. В случае всплеска ошибок система возвращается к консервативным правилам. Таким образом, расстановка приоритетов остается объяснимой, а я экономлю драгоценное время. минут запасной.
Соответствие нормативным требованиям, защита данных и протоколирование
I журнал Как можно больше, как можно меньше. Идентификаторы сообщений, идентификаторы очередей, целевой домен и статус обычно достаточны для диагностики проблем. Я маскирую личные данные, если они не требуются для работы. Я поддерживаю короткое время хранения, дифференцированное в соответствии с приоритетами и требованиями законодательства. Экспортированные метрики не содержат никакого содержимого и хранятся отдельно от необработанных журналов. Для аудита я документирую, как создаются правила приоритизации и какие исключения Это создает доверие и ускоряет процесс утверждения.
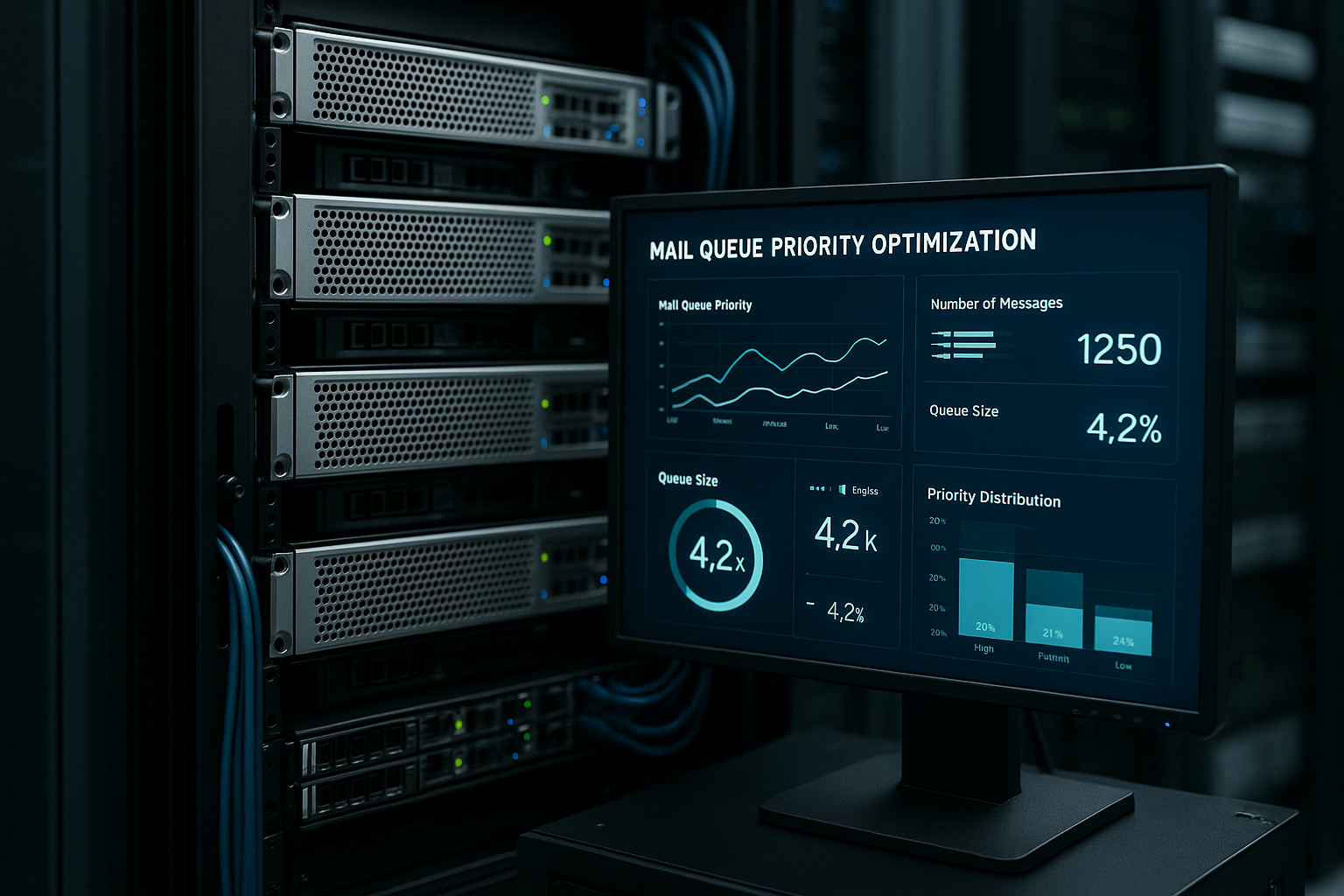
Безопасность, репутация и обработка отказов в повседневной жизни
Я защищаю IP-репутация со строгими ограничениями на новые целевые домены и осторожным параллелизмом. SPF, DKIM и DMARC работают для того, чтобы получатели могли доверять друг другу. Я делаю четкое различие между отскоками: жесткие отскоки я завершаю быстро, мягкие отскоки откладываются с возвратом. Я регулярно очищаю очередь отказов, чтобы поддерживать файловую систему в рабочем состоянии. Я анализирую контуры обратной связи и быстро корректирую списки. Я устанавливаю ограничения по скорости для каждого домена-получателя отдельно в соответствии с приоритетом. Это позволяет мне найти баланс между скоростью доставки и Репутациязащита.
Ключевые идеи для повседневной работы
Эффективный Почтовая очередь Приоритет отделяет срочное от несрочного и дает высокоприоритетным задачам четкий путь. Я сочетаю приоритетные очереди, разумные отступления, ограничения по параллельности и тщательный мониторинг. Я итеративно адаптирую параметры к измеренным значениям, а не к интуиции. Настройка сети и DNS предотвращает блокировку голов и снижает задержки. ИИ быстрее классифицирует потоки, а правила устанавливают четкие ограждения. Сервер остается надежным благодаря чистому рабочему процессу обслуживания, отказов и очистки. Именно так я обеспечиваю быструю доставку важных писем и поддерживаю систему в рабочем состоянии. эффективный.


