 Перейти к содержимому
Перейти к содержимому 
HTTP Keep-Alive сокращает количество рукопожатий и поддерживает открытые соединения, чтобы несколько запросов проходили через один и тот же сокет, а Нагрузка на сервер снижается. С помощью целенаправленной настройки я контролирую таймауты, лимиты и рабочие процессы, снижаю Задержки и увеличьте производительность без изменения кода.
Центральные пункты
- Повторное использование соединения снижает нагрузку на ЦП и количество рукопожатий.
- Короткие Тайм-ауты предотвращают пустые соединения.
- Чистый Лимиты для keepalive_requests стабилизировать нагрузку.
- HTTP/2 и HTTP/3 объединяются еще сильнее.
- Реалистичные Нагрузочные испытания Сохраните настройки.
Как работает HTTP Keep-Alive
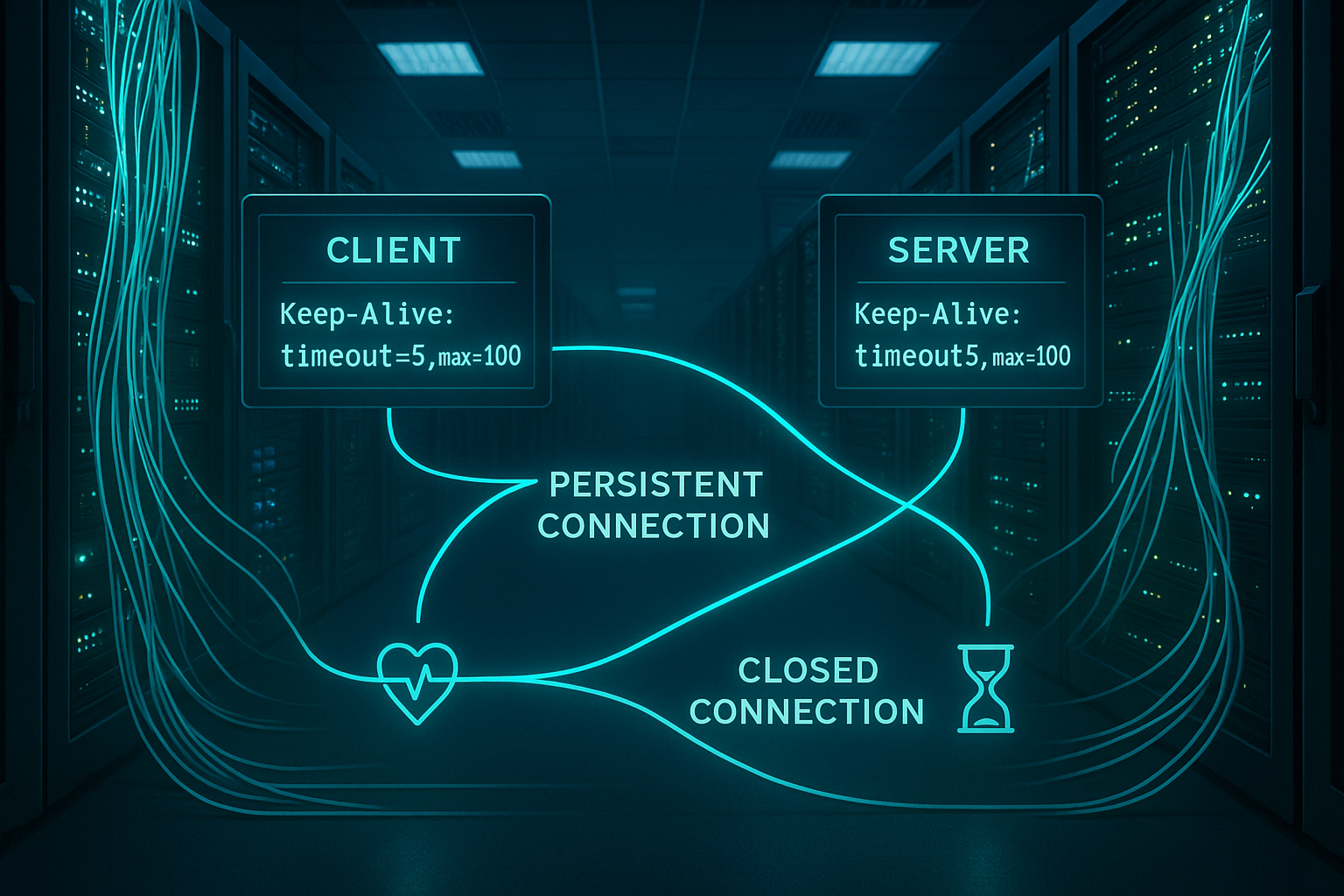
Вместо того, чтобы открывать новое TCP-соединение для каждого ресурса, я повторно использую существующее соединение и таким образом экономлю Рукопожатия и обратные запросы. Это сокращает время ожидания, поскольку ни TCP, ни TLS не должны постоянно работать, а канал быстро отвечает. Клиент распознает по заголовку, что соединение остается открытым, и отправляет последующие запросы последовательно или с мультиплексированием (в HTTP/2/3) через тот же розетка. Сервер управляет фазой простоя с помощью таймаута Keep-Alive и завершает соединение, если в течение длительного времени не поступает запросов. Такое поведение заметно ускоряет работу страниц с большим количеством ресурсов и снижает нагрузку на ЦП, поскольку требуется меньше подключений.

Повторное использование соединения: влияние на нагрузку сервера
Каждое предотвращенное новое соединение экономит время процессора для работы ядра и TLS, что я вижу в мониторинге в виде более ровной кривой нагрузки. Данные показывают, что повторное использование существующих сокетов может увеличить пропускную способность до 50 процентов, если поступает много мелких запросов. В тестах с большим количеством запросов GET общая продолжительность иногда сокращается в три раза, поскольку происходит меньше рукопожатий и меньше смен контекста. Нагрузка на сеть также снижается, поскольку пакеты SYN/ACK появляются реже, и у сервера остается больше ресурсов для фактической логики приложения. Это взаимодействие обеспечивает более быстрые ответы и более стабильную работу. Время реагирования под нагрузкой.
Риски: слишком длительные таймауты и открытые соединения
Слишком большой таймаут Keep-Alive оставляет соединения в режиме ожидания и блокирует их. Рабочий или потоки, хотя запросов нет. При высокой нагрузке количество открытых сокетов растет, достигает пределов файловых дескрипторов и приводит к увеличению потребления памяти. Кроме того, неподходящие тайм-ауты клиента создают „мертвые“ соединения, которые отправляют запросы на уже закрытые сокеты и генерируют сообщения об ошибках. Входные и NAT-шлюзы могут закрывать неактивные линии раньше, чем сервер, что приводит к спорадическим сбросам. Поэтому я сознательно ограничиваю время простоя, устанавливаю четкие лимиты и поддерживаю противоположная сторона (клиенты, прокси) в поле зрения.

HTTP Keep-Alive против TCP Keepalive
Я строго различаю HTTP Keep-Alive (постоянные соединения на уровне приложения) и механизм TCP „keepalive“. HTTP Keep-Alive контролирует, будут ли дальнейшие HTTP-запросы проходить через тот же сокет. TCP Keepalive, напротив, с большими интервалами отправляет пробные пакеты, чтобы обнаружить „мертвые“ удаленные узлы. Для настройки производительности в первую очередь важен HTTP Keep-Alive. Я использую TCP Keepalive специально для длительных периодов простоя (например, при подключениях Edge или в корпоративных сетях с агрессивными брандмауэрами), но устанавливаю интервалы в защитном режиме, чтобы не создавать ненужную нагрузку на сеть.
Особые случаи: Long Polling, SSE и WebSockets
Долговечные потоки (Server-Sent Events), Long Polling или WebSockets конфликтуют с короткими таймаутами простоя. Я отделяю эти конечные точки от стандартных API- или Asset-маршрутов, назначаю им более высокие таймауты и выделенные пулы рабочих процессов, а также ограничиваю количество одновременных потоков на IP. Таким образом, долговечные потоки не блокируют ресурсы для классических коротких запросов. Для SSE и WebSockets лучше установить четкие ограничения, таймауты чтения/записи и чистый интервал heartbeat или ping/pong, чем глобально увеличить все таймауты.
Основные параметры Keep-Alive на веб-сервере
Я почти всегда активирую Keep-Alive, устанавливаю короткий таймаут простоя и ограничиваю количество запросов на соединение, чтобы сэкономить ресурсы. перерабатывать. Кроме того, я регулирую пулы рабочих процессов/потоков, чтобы неактивные соединения не занимали слишком много процессов. В следующей таблице приведены типичные директивы, цели и начальные значения, которые я регулярно использую на практике. Значения варьируются в зависимости от приложения и профиля задержки, но обеспечивают прочную основу для первых тестов. Затем я постепенно дорабатываю таймауты, ограничения и Темы на основе реальных измерительных данных.
| Сервер/компонент | директива | Назначение | начальное значение |
|---|---|---|---|
| Apache | KeepAlive | Включить постоянные соединения | На |
| Apache | KeepAliveTimeout | Время простоя до окончания соединения | 5–15 с |
| Apache | MaxKeepAliveRequests | Максимальное количество запросов на соединение | 100–500 |
| Nginx | keepalive_timeout | Время простоя до окончания соединения | 5–15 с |
| Nginx | keepalive_requests | Максимальное количество запросов на соединение | 100 |
| HAProxy | опция http-keep-alive | Разрешить постоянные соединения | активно |
| Ядро/ОС | somaxconn, tcp_max_syn_backlog | Очереди на соединения | адаптировано к трафику |
| Ядро/ОС | Ограничения FD (ulimit -n) | Открытые файлы/сокеты | >= 100 тыс. при высокой посещаемости |
Apache: начальные значения, MPM и управление рабочими процессами
Для сайтов с высокой степенью параллелизма я использую MPM в Apache. мероприятие, потому что он более эффективно обрабатывает соединения Idle-Keep-Alive, чем старый prefork. На практике я часто выбираю 5–15 секунд для KeepAliveTimeout, чтобы клиенты могли объединять ресурсы, не блокируя рабочие процессы надолго. С MaxKeepAliveRequests 100–500 я принудительно устанавливаю умеренную переработку, что предотвращает утечки и сглаживает пиковые нагрузки. Я сокращаю общий таймаут до 120–150 секунд, чтобы зависшие запросы не связывали процессы. Те, кто углубляется в потоки и процессы, найдут важную информацию о Настройки пула потоков для различных веб-серверов.
Nginx и HAProxy: практические шаблоны и антипаттерны
В случае обратных прокси я часто наблюдаю две ошибки: либо Keep-Alive отключается глобально „из соображений безопасности“ (что приводит к огромной нагрузке на рукопожатие), либо тайм-ауты простоя высоки, в то время как трафик небольшой (что связывает ресурсы). Я считаю, что тайм-ауты фронт-энда должны быть короче, чем тайм-ауты бэк-энда, чтобы прокси могли оставаться открытыми, даже если клиенты закрывают соединение. Кроме того, я разделяю пулы вверх по потоку по классам сервисов (статические активы против API), потому что последовательность их запросов и простоя зависит от профиля. Также критически важно правильно Длина содержимого/Кодирование передачи-Обработка: неверные данные о длине препятствуют повторному использованию соединения и вызывают „connection: close“ — в результате возникают ненужные новые соединения.
Nginx и HAProxy: правильное использование пулов Upstream
С Nginx я экономлю много рукопожатий, когда держу открытыми восходящие соединения с бэкэндами и использую keepalive Настраиваю размеры пула. Это сокращает количество TLS-настроек на серверах приложений и значительно снижает нагрузку на ЦП. Я отслеживаю количество открытых сокетов вверх по потоку, коэффициенты повторного использования и распределение задержек в журналах, чтобы целенаправленно увеличивать или уменьшать размеры пула. На стороне ядра я увеличиваю ограничения FD и настраиваю somaxconn и tcp_max_syn_backlog, чтобы очереди не переполнялись. Таким образом, прокси остается отзывчивым при высокой параллельности и равномерно распределяет трафик по бэкэнды.
Оптимизация TLS и QUIC для уменьшения накладных расходов
Чтобы Keep-Alive проявил свой эффект в полной мере, я оптимизирую уровень TLS: TLS 1.3 с возобновлением (Session Tickets) сокращает время установления соединения, OCSP-Stapling сокращает время проверки сертификатов, а оптимизированная цепочка сертификатов сокращает количество байтов и нагрузку на ЦП. Я использую 0-RTT только для идемпотентных запросов и с осторожностью, чтобы избежать рисков повторного воспроизведения. В HTTP/3 (QUIC) это idle_timeout Решающий фактор: слишком высокая стоимость хранения, слишком низкая стоимость прерывает потоки. Я также тестирую, как начальное окно перегрузки и ограничениями усиления при холодных соединениях, особенно на больших расстояниях.
Целенаправленное использование HTTP/2, HTTP/3 и мультиплексирования
HTTP/2 и HTTP/3 объединяют множество запросов в одно соединение и устраняют Главная страница-Блокировка на уровне приложения. Это еще больше повышает эффективность Keep-Alive, поскольку создается меньше соединений. В своих настройках я уделяю особое внимание конфигурации приоритетов и управления потоком, чтобы критически важные ресурсы работали в первую очередь. Кроме того, я проверяю, эффективно ли работает Connection Coalescing, например, когда несколько хост-имен используют один и тот же сертификат. Взгляните на HTTP/3 против HTTP/2 помогает выбрать подходящий протокол для глобальных профилей пользователей.

Клиенты и стеки приложений: правильная настройка пула
Клиентская сторона и сторона приложения также влияют на повторное использование: в Node.js я активирую для HTTP/HTTPS keepAlive-Agent с ограниченным количеством сокетов на каждый хост. В Java я устанавливаю разумные размеры пула и таймауты простоя для HttpClient/OkHttp; в Go я настраиваю Максимальное количество неактивных соединений и Максимальное количество неактивных подключений на хост . Клиенты gRPC получают выгоду от длительных соединений, но я определяю интервалы пинга и тайм-ауты поддержания связи так, чтобы прокси-серверы не создавали флуд. Важна последовательность: слишком агрессивные повторные подключения клиентов сводят на нет любую оптимизацию сервера.
Нагрузочные испытания и стратегия измерения
Слепое вращение на тайм-аутах редко приводит к стабильным результатам. Результаты, поэтому я провожу систематические измерения. Я моделирую типичные пути пользователей с большим количеством небольших файлов, реалистичным уровнем параллелизации и географически распределенной задержкой. При этом я регистрирую коэффициенты повторного использования, среднюю продолжительность соединения, коды ошибок и соотношение открытых сокетов к количеству рабочих процессов. Затем я постепенно изменяю KeepAliveTimeout и сравниваю кривые времени отклика и потребления ЦП. Только когда метрики остаются стабильными в течение нескольких прогонов, я переношу значения в Производство.
Наблюдаемость: какие показатели имеют значение
Я отслеживаю конкретные показатели: количество новых соединений в секунду, соотношение повторного использования/перестроения, количество TLS-рукопожатий в секунду, открытые сокеты и время их пребывания, 95/99-й процентиль задержки, распределение кодов состояния (включая 408/499), а также состояния ядра, такие как TIME_WAIT/FIN_WAIT2. Пики в рукопожатиях, рост 499 и увеличение TIME_WAIT-бакетов часто указывают на слишком короткие таймауты простоя или слишком маленькие пулы. Четко инструментированная логика делает настройку воспроизводимой и предотвращает ситуацию, когда оптимизации дают лишь эффект плацебо.

Согласование таймаута между клиентом и сервером
Клиенты должны закрывать неактивные соединения немного раньше, чем сервер, чтобы не было „мертвых“ Розетки возникают. Поэтому в приложениях фронт-энда я устанавливаю более низкие тайм-ауты HTTP-клиента, чем на веб-сервере, и документирую эти настройки. То же самое относится к балансировщикам нагрузки: их тайм-аут простоя не должен быть меньше, чем у сервера. Я также слежу за значениями простоя NAT и брандмауэра, чтобы соединения не исчезали в сетевом пути. Такое четкое взаимодействие предотвращает спорадические сбросы и стабилизирует Ретрансляции.
Устойчивость и безопасность под нагрузкой
Постоянные соединения не должны привлекать Slowloris & Co. Я устанавливаю короткие таймауты чтения заголовков/тела, ограничиваю размер заголовков, ограничиваю количество одновременных соединений на IP и обеспечиваю обратное давление в восходящих потоках. При ошибках протокола я последовательно закрываю соединения (вместо того, чтобы оставлять их открытыми), тем самым предотвращая Request Smuggling. Кроме того, я определяю разумные grace-Время при закрытии, чтобы сервер корректно завершал открытые ответы, не оставляя соединения в бесконечном режиме ожидания. затягивающийся-состояния.
Факторы хостинга и архитектура
Мощные процессоры, быстрые сетевые карты и достаточное количество RAM ускоряют рукопожатия, смену контекста и шифрование, что позволяет в полной мере использовать настройку Keep-Alive. Обратный прокси перед приложением упрощает разгрузку, централизует таймауты и увеличивает коэффициент повторного использования бэкэндов. Для большего контроля над TLS, кэшированием и маршрутизацией я полагаюсь на четкую Архитектура обратного прокси. Важно своевременно снимать ограничения, такие как ulimit -n и accept-Queues, чтобы инфраструктура могла выдерживать высокую степень параллелизма. Благодаря четкой наблюдаемости я быстрее обнаруживаю узкие места и могу Лимиты надежно затянуть.

Развертывание, дренаж и тонкости ОС
При постепенном развертывании я контролируемо прекращаю поддержание соединений: я больше не принимаю новые запросы, а существующие могут быть краткосрочно обслужены (Drain). Таким образом я избегаю обрывов соединений и пиков 5xx. На уровне ОС я слежу за диапазоном эфемерических портов, somaxconn, SYN-Backlog и tcp_fin_timeout, без использования устаревших настроек, таких как агрессивное повторное использование TIME_WAIT. SO_REUSEPORT Я распределяю их между несколькими рабочими процессами, чтобы снизить конкуренцию Accept. Цель всегда одна: стабильно обрабатывать большое количество кратковременных соединений, не создавая заторов в очереди ядра.
Резюме: Тюнинг как рычаг повышения производительности
Последовательное использование HTTP Keep-Alive приводит к уменьшению количества устанавливаемых соединений, снижению Загрузка процессора и заметно более быстрые ответы. Короткие таймауты простоя, четкие ограничения на каждое соединение и достаточное количество рабочих процессов позволяют устранить простаивающие сокеты. С помощью HTTP/2/3, пулов восходящего потока и согласованных ограничений ОС я масштабирую параллелизм без потери стабильности. Реалистичные нагрузочные тесты показывают, действительно ли настройки работают и где находятся следующие процентные пункты. Комбинируя эти компоненты, можно увеличить пропускную способность, снизить задержки и использовать имеющиеся Ресурсы максимально.


