 Перейти к содержимому
Перейти к содержимому 
Обоснованный анализ TTFB показывает, почему временная метка первого байта часто интерпретируется неверно, и как я объединяю измерения с пользовательскими метриками в осмысленном виде. Я объясняю, где именно возникают ошибки в интерпретации, как я собираю последовательные данные и какие оптимизации Восприятие действительно увеличивают скорость.
Центральные пункты
- TTFB описывает запуск сервера, а не общую скорость.
- Контекст вместо одного значения: считывание LCP, FCP, INP.
- Расположение и сеть характеризуют измеренные значения.
- Кэширование и CDN сокращают время ожидания.
- Ресурсы и конфигурация оказывают непосредственное влияние.

Краткое описание TTFB: понимание измерительной цепи
TTFB сопоставляет время от запроса до первого возвращенного байта и состоит из нескольких шагов, которые я называю Измерительная цепь должны быть учтены. Сюда входят разрешение DNS, рукопожатие TCP, согласование TLS, обработка сервера и отправка первого байта. Каждый раздел может создавать узкие места, что существенно меняет общее время. Инструмент показывает здесь одно значение, но причины лежат на нескольких уровнях. Поэтому я разделяю транспортную задержку, ответ сервера и логику приложения, чтобы Источники ошибок однозначно подлежат переуступке.
Оптимизируйте сетевой путь: От DNS к TLS
Начну с имени: DNS-резольверы, цепочки CNAME и TTL влияют на скорость разрешения хоста. Слишком много перенаправлений или резолвер с высокой задержкой добавляют заметные миллисекунды. Затем считается соединение: Я сокращаю количество переходов туда-сюда с помощью keep-alive, стратегий типа TCP fast-open и быстрого совместного использования портов. При использовании TLS я проверяю цепочку сертификатов, сшивание OCSP и возобновление сеанса. Короткая цепочка сертификатов и активированное сшивание позволяют экономить на рукопожатиях, а современные протоколы, такие как HTTP/2 и HTTP/3, эффективно мультиплексируют несколько запросов через одно соединение.
Я также обращаю внимание на путь: IPv6 может иметь преимущества в хорошо связанных сетях, но слабые пиринговые маршруты увеличивают джиттер и потери пакетов. В мобильных сетях каждый путь туда и обратно играет большую роль, поэтому я отдаю предпочтение механизмам 0-RTT, ALPN и быстрым версиям TLS. Для меня важно, что транспортная оптимизация не только ускоряет TTFB, но и стабилизирует дисперсию. Стабильный диапазон измерений делает мои оптимизации более воспроизводимыми, а решения - более надежными.
3 наиболее распространенных неправильных толкования
1) TTFB означает общую скорость
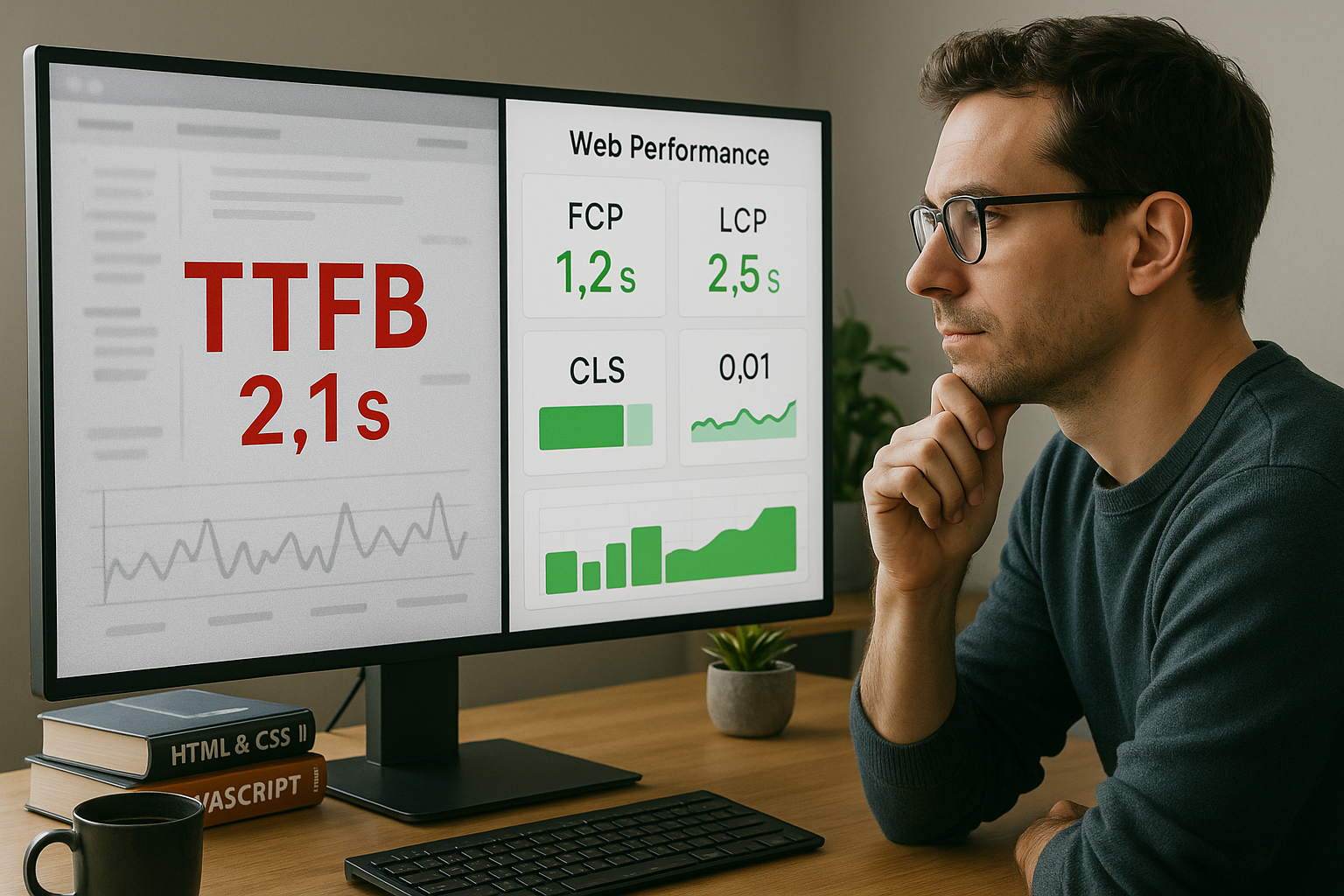
Низкий показатель TTFB мало что говорит о рендеринге, доставке изображений или выполнении JavaScript, то есть о том, что люди могут делать напрямую. См.. Страница может отправить первый байт на ранней стадии, но позже потерпеть неудачу из-за самого большого содержимого (LCP). Я часто наблюдаю быстрые первые байты при вялой интерактивности. Ощутимая скорость появляется только тогда, когда появляется и реагирует соответствующий контент. Вот почему фиксированное представление TTFB объединяет Реальность использования от измеренного значения.
2) Низкий уровень TTFB = хороший UX и SEO
Я могу искусственно увеличить TTFB, например, используя ранние заголовки, не предоставляя при этом полезного контента, который и является настоящим Утилитарная ценность не увеличивается. Поисковые системы и люди больше ценят видимость и удобство использования, чем первый байт. Такие метрики, как LCP и INP, лучше отражают ощущения от страницы. Чистый фокус на TTFB игнорирует критические этапы рендеринга и интерактивности. Поэтому я измеряю дополнительно, чтобы решения принимались на основе Данные с актуальностью.
3) Все значения TTFB сопоставимы
Измерение точек, пиринга, нагрузки и расстояния искажает сравнения, которые я вряд ли смог бы сделать без тех же рамочных условий. Тариф может. Тестовый сервер в США показывает совсем другие результаты, чем сервер во Франкфурте. Колебания нагрузки между утром и вечером также заметно меняют результаты. Поэтому я использую несколько запусков, как минимум в двух местах и в разное время. Только такой диапазон позволяет получить достоверные данные. Классификация значения.

Синтетика против RUM: две точки зрения на TTFB
Я сочетаю синтетические тесты с мониторингом реальных пользователей (RUM), потому что и те, и другие отвечают на разные вопросы. Синтетические тесты дают мне контролируемые эталоны с четкими рамками, идеальные для регрессионного тестирования и сравнений. RUM отражает реальность на разных устройствах, в разных сетях и регионах и показывает, как TTFB колеблется в полевых условиях. Я работаю с процентилями, а не со средними значениями, чтобы выявить отклонения и сегментировать по устройствам (мобильные/настольные), странам и качеству сети. Только при обнаружении закономерностей в обоих случаях я оцениваю причины и меры как надежные.
Что на самом деле влияет на TTFB?
Выбор среды хостинга оказывает существенное влияние на задержку, IO и время вычислений, что напрямую отражается на TTFB показывает. Перегруженные системы отвечают медленнее, в то время как твердотельные накопители NVMe, современные стеки и хорошие пиринговые каналы позволяют сократить время отклика. Конфигурация сервера также имеет значение: неподходящие настройки PHP, слабый opcache или нехватка оперативной памяти приводят к задержкам. При работе с базами данных я замечаю медленные запросы в каждом запросе, особенно с неиндексированными таблицами. CDN сокращает расстояние и снижает Латентность для статического и кэшированного содержимого.
PHP-FPM и оптимизация времени выполнения на практике
Я проверяю менеджер процессов: слишком малое количество рабочих PHP порождает очереди, слишком большое - вытесняет кэш из оперативной памяти. Я балансирую такие параметры, как max_children, pm (dynamic/ondemand) и лимиты запросов, основываясь на реальных профилях нагрузки. Я держу Opcache теплым и стабильным, уменьшаю накладные расходы на автозагрузку (оптимизированные classmaps), активирую кэш realpath и удаляю отладочные расширения в производстве. Я переношу дорогостоящие инициализации в бутстрапы и кэширую результаты в объектный кэш. Это сокращает время между приемом сокета и первым байтом, не жертвуя функциональностью.
Как правильно измерить TTFB
Я провожу тестирование несколько раз, в разное время, как минимум в двух местах и формирую медианы или перцентили для получения достоверной информации. Основа. Я также проверяю, не нагрелся ли кэш, поскольку первый доступ часто занимает больше времени, чем все последующие. Я соотношу TTFB с LCP, FCP, INP и CLS, чтобы значение имело смысл в общей картине. Для этого я использую специальные прогоны для HTML, критических ресурсов и стороннего контента. Хорошей отправной точкой является оценка по следующим параметрам Основные показатели Webпотому что они Восприятие пользователей.
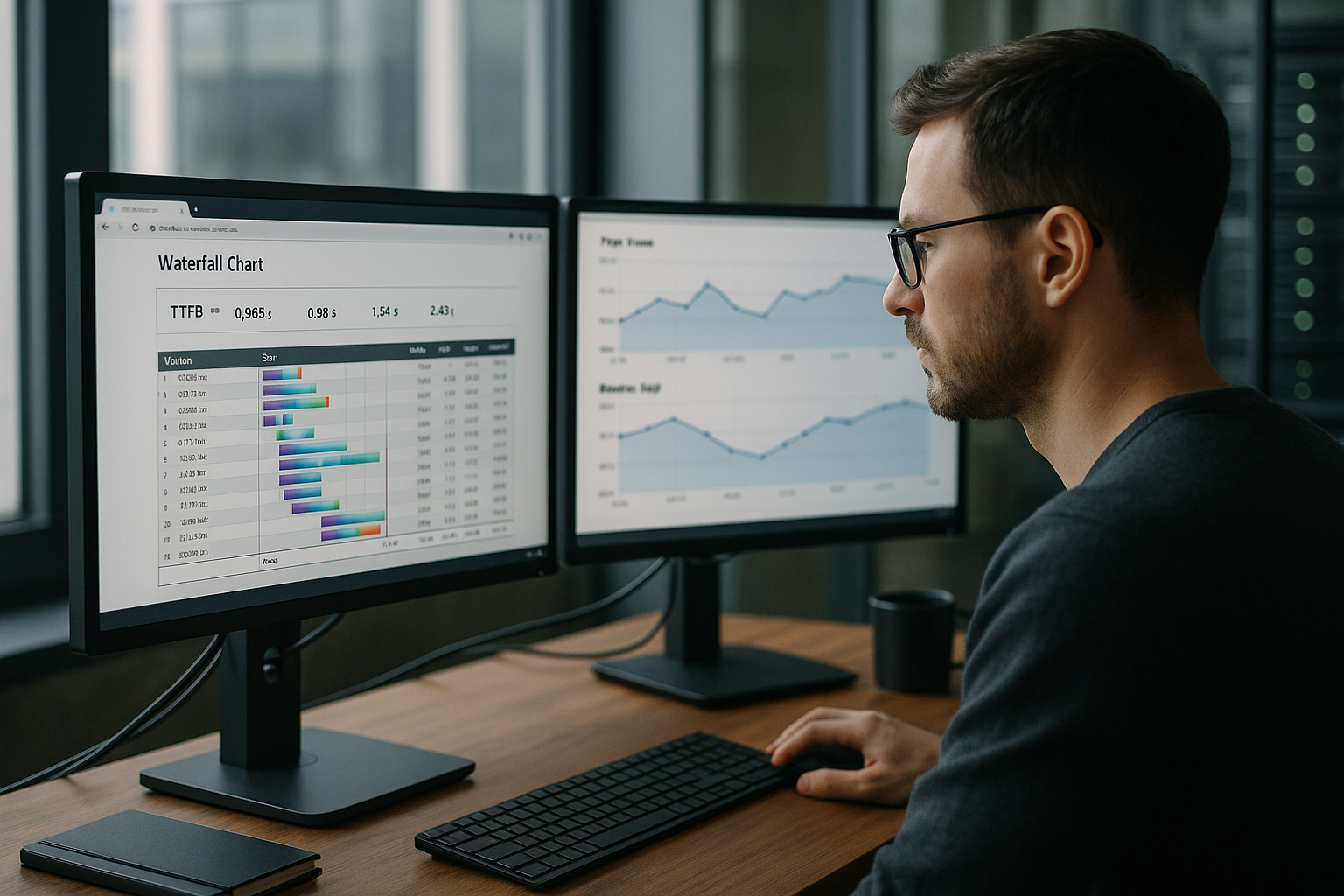
Хронометраж сервера и возможность отслеживания
Я также отправляю заголовки времени сервера, чтобы сделать временные доли прозрачными: например, dns, connect, tls, app, db, cache. Я добавляю те же маркеры в журналы и добавляю идентификаторы трассировки в запросы, чтобы можно было отслеживать отдельные запуски через CDN, Edge и Origin. Такая детализация позволяет избежать игр в угадайку: Вместо "TTFB высок" я могу увидеть, требуется ли базе данных 180 мс или Origin застрял в очереди на 120 мс. Благодаря перцентилям для каждого маршрута (например, детализация продукта против поиска) я определяю четкие бюджеты и могу остановить регрессию в CI на ранней стадии.
Лучшие практики: Быстрый первый байт
Я использую кэширование HTML на стороне сервера, чтобы сервер мог доставлять готовые ответы и CPU не нужно пересчитывать каждый запрос. Глобальная CDN приближает контент к пользователям и сокращает расстояние, время DNS и маршрутизацию. Я поддерживаю PHP, базу данных и веб-сервер в актуальном состоянии, активирую Opcache и использую HTTP/2 или HTTP/3 для лучшего использования соединения. Я перевожу дорогостоящие вызовы внешних API в асинхронный режим или кэширую их, чтобы первый байт не простаивал. Регулярное профилирование позволяет выявить медленные запросы и Плагины которые я обезвреживаю или заменяю.
Стратегии кэширования в деталях: TTL, Vary и Microcaching
Я провожу строгое различие между динамическим и кэшируемым. HTML получает короткие TTL и микрокеширование (например, 5-30 с) для пиков нагрузки, в то время как ответы API с чистыми заголовками управления кешем и ETags могут жить дольше. Я использую Vary выборочно: Только там, где язык, куки или пользовательский агент действительно генерируют различный контент. Слишком широкие ключи Vary разрушают коэффициент попадания. С помощью stale-while-revalidate я доставляю информацию немедленно и обновляю ее в фоновом режиме; stale-if-error сохраняет страницу доступной, если бэкенд зависает. Важно: Избегайте cookies на корневом домене, если они непреднамеренно препятствуют кэшированию.
При изменениях я планирую чистую очистку кэша с помощью параметров версии или хэшей содержимого. Я ограничиваю недействительность HTML затронутыми маршрутами, а не запускаю глобальную очистку. Для CDN я использую региональные разминки и щит происхождения для защиты сервера происхождения. Это позволяет поддерживать стабильность TTFB даже во время пиков трафика без необходимости превышать пропускную способность.
TTFB против пользовательского опыта: важные показатели
Я обозначаю LCP как "Самое большое видимое содержимое", FCP как "Первое содержимое" и INP как "Входной отклик", потому что эти метрики - это опыт. заметно сделать. Страница может иметь умеренный TTFB и при этом отображаться быстро, если важный рендеринг происходит раньше. И наоборот, от маленького TTFB мало толку, если блокирующие скрипты задерживают отображение. Я использую Анализ маякачтобы проверить последовательность ресурсов, путь рендеринга и приоритеты. Это позволяет мне увидеть, какая оптимизация действительно Помогает.

Правильная установка приоритетов рендеринга
Я слежу за тем, чтобы критически важные ресурсы находились впереди всего остального: Критические CSS в строке, шрифты с font-display и разумной предварительной загрузкой/приоритизацией, изображения в верхней части страницы с соответствующим приоритетом fetchpriority. Я загружаю JavaScript как можно позже или асинхронно и очищаю загрузку основного потока, чтобы браузер мог быстро рисовать. Я использую ранние подсказки для запуска предварительной загрузки перед окончательным ответом. Результат: даже если TTFB не идеальна, страница ощущается гораздо быстрее благодаря ранней видимости и быстрому отклику.
Избежать ошибок измерения: типичные камни преткновения
Теплый кэш искажает сравнения, поэтому я различаю холодные и теплые запросы. отдельно. CDN также может иметь устаревшие или невоспроизводимые края, что удлиняет время первого поиска. Я проверяю загрузку сервера параллельно, чтобы резервные копии или задания cron не влияли на измерения. На стороне клиента я обращаю внимание на кэш браузера и качество соединения, чтобы минимизировать локальные эффекты. Даже DNS-резольверы изменяют задержку, поэтому я держу тестовое окружение в таком состоянии. постоянная.
Рассмотрим CDN, WAF и уровни безопасности
Посреднические системы, такие как WAF, бот-фильтры и защита от DDoS, могут увеличить TTFB без вины источника. Я проверяю, происходит ли завершение TLS на границе, активен ли щит и как правила запускают комплексные проверки. Ограничения скорости, геозоны или JavaScript-задачи часто полезны, но не должны незаметно смещать медианные значения. Поэтому я отдельно измеряю попадание на границу и пропуск на границе, и у меня есть правила исключений для синтетических тестов, чтобы отличить реальные проблемы от механизмов защиты.
Принятие решений, которые окупаются
Быстрые твердотельные накопители NVMe, достаточный объем оперативной памяти и современные процессоры обеспечивают бэкэнд достаточной мощностью. Производительностьчтобы ответы начинались быстро. Я масштабирую рабочих PHP в соответствии с трафиком, чтобы запросы не стояли в очереди. Влияние этого узкого места часто становится очевидным только под нагрузкой, поэтому я планирую мощность реалистично. Для практического планирования можно воспользоваться руководством Правильно спланируйте работников PHP. Близость к целевому рынку и хорошее пиринговое соединение также поддерживают Латентность низкий.

Процессы развертывания и качества
Я отношусь к производительности как к качественной характеристике доставки: я определяю бюджеты TTFB, LCP и INP в конвейере CI/CD и блокирую релизы с явными регрессиями. Канареечные релизы и флаги возможностей помогают мне дозировать риски и измерять их шаг за шагом. Перед серьезными изменениями я провожу нагрузочные тесты, чтобы выявить ограничения на количество работников, ограничения на количество соединений и блокировки баз данных. Благодаря регулярным дымовым тестам на репрезентативных маршрутах я сразу же распознаю ухудшения, а не только когда наступает пик. Это позволяет мне поддерживать достигнутые улучшения в долгосрочной перспективе.
Практическая таблица: Сценарии измерений и меры
Следующий обзор классифицирует типичные ситуации и связывает наблюдаемые TTFB с другими ключевыми цифрами и ощутимыми фактами Шаги. Я использую их для более быстрого выявления причин и четкого определения мер. По-прежнему важно несколько раз проверять значения и читать контекстные метрики. Это не позволяет мне принимать решения, которые действуют только на симптомы и не улучшают восприятие. Таблица помогает мне планировать и анализировать тесты. Приоритеты установить.
| Сценарий | Наблюдение (TTFB) | Сопутствующие показатели | Возможная причина | Конкретная мера |
|---|---|---|---|---|
| Первый звонок утром | Высокий | LCP в порядке, FCP в порядке | Холодный кэш, пробуждение БД | Предварительное очищение кэша сервера, поддержание соединений с БД |
| Пик интенсивности движения | Увеличивается в разы | Ухудшилось состояние ИНП | Слишком мало работников PHP | Увеличение числа работников, передача на аутсорсинг длительных задач |
| Глобальный доступ США | Значительно выше | LCP колеблется | Расстояние, пиринг | Активируйте CDN, используйте краевой кэш |
| Много страниц с товарами | Нестабильный | FCP хорошо, LCP плохо | Большие изображения, без раннего намека | Оптимизируйте изображения, отдавайте предпочтение предварительной загрузке |
| API сторонних разработчиков | Сменный | ИНП в порядке | Время ожидания API | Кэшируйте ответы, обрабатывайте их асинхронно |
| Обновление бэкенда CMS | Выше, чем раньше | CLS без изменений | Новый плагин ставит на тормоза | Профилирование, замена или исправление плагинов |
Реферат: Правильно классифицируйте TTFB в контексте
Одно значение TTFB редко объясняет ощущения от страницы, поэтому я связываю его с LCP, FCP, INP и реальными Пользователи. Я провожу несколько измерений, синхронизирую местоположение и проверяю нагрузку, чтобы получить стабильные результаты. Для быстрого запуска я использую кэширование, CDN, современное программное обеспечение и экономные запросы. В то же время я отдаю предпочтение рендерингу видимого контента, потому что ранняя видимость улучшает восприятие. Вот как мой анализ TTFB приводит к решениям, которые оптимизируют Опыт посетителей.


