
Активное ведение журнала отладки заставляет WordPress выполнять дополнительные операции записи при каждом его вызове, что увеличивает TTFB и нагрузка на сервер заметно возрастает. Как только на один запрос приземляются сотни уведомлений, предупреждений и устаревших уведомлений, нагрузка на сервер возрастает. журнал отладки и страница реагирует медленно.
Центральные пункты
- Запись нагрузки Рост: каждая ошибка попадает в debug.log и создает накладные расходы на ввод-вывод.
- E_ALL активно: Уведомления и устаревшие заметки раздувают журнал.
- Продуктивный Рискованно: скорость падает, конфиденциальная информация попадает в лог-файл.
- Кэширование Ограничено: накладные расходы приходятся на каждый запрос, кэш мало чем поможет.
- Вращение необходимость: большие журналы замедляют работу и съедают память.
Почему активное ведение журнала отладки замедляет работу WordPress
Каждый запрос вызывает Отладка журнала wordpress три задачи: Запись ошибок, форматирование сообщений и запись их на жесткий диск. Эта цепочка занимает время, потому что PHP сначала генерирует содержимое сообщения, а затем синхронизирует его в журнал отладки должны быть сохранены. Особенно при большом количестве плагинов уведомления накапливаются, а это значит, что каждая страница внезапно вызывает сотни операций записи. Файл быстро увеличивается на десятки мегабайт в день, что замедляет доступ к файлу. Затем я вижу, как увеличивается TTFB и общее время загрузки, даже если в теме или кэше ничего не менялось.

Понимание уровней ошибок: E_ALL, уведомления и устаревшие
С WP_DEBUG в true, WordPress повышает отчет об ошибках до E_ALL, что означает, что даже безобидные уведомления попадают в журнал. Именно эти уведомления и устаревшие предупреждения звучат безобидно, но сильно увеличивают частоту журнала. Каждое сообщение вызывает обращение к записи и увеличивает время ожидания. Если вы хотите узнать, какие уровни ошибок вызывают какую нагрузку, вы можете найти справочную информацию на сайте Уровни ошибок PHP и производительность. Поэтому я временно уменьшаю громкость, отсеиваю ненужные шумы и тем самым сокращаю время звучания. Интенсивность письма по запросу.
Размер файла, TTFB и нагрузка на сервер: эффект домино
Как только журнал отладки достигает нескольких сотен мегабайт, маневренность файловой системы снижается. PHP безостановочно проверяет, открывает, записывает и закрывает файл, что увеличивает TTFB и время отклика бэкенда. Кроме того, процессор форматирует сообщения, что является проблемой при высоком трафике. Ввод-вывод становится узким местом, поскольку множество небольших синхронных записей может перегрузить Латентность доминировать. На виртуальном хостинге это приводит к увеличению средней нагрузки до тех пор, пока даже бэкэнд не покажется вялым.
Типичные триггеры: плагины, WooCommerce и высокий трафик
Магазины и журналы с большим количеством расширений быстро производят большое количество Уведомления. Установка WooCommerce с 20 расширениями может вызывать десятки тысяч записей каждый день, что за короткое время раздует файл журнала. Если трафик увеличивается, поток сообщений растет с той же скоростью. Каждый запрос страницы пишет заново, даже если вывод фронтенда кэширован, так как логирование происходит до вывода кэша. В таких случаях я наблюдаю пики времени загрузки и крах заданий cron, потому что Дисковый ввод-вывод постоянно блокируется.
Продуктивные среды: Потеря скорости и утечка информации
На живых системах я зажимаю Отладка как только анализ ошибок завершится. Отладочные журналы раскрывают пути к файлам, детали запросов и, следовательно, потенциально конфиденциальную информацию. Кроме того, время отклика заметно снижается, поскольку каждый реальный посетитель снова запускает журналы. Если вы хотите действовать более тщательно, ознакомьтесь с альтернативными вариантами и рекомендациями по Режим отладки в производстве. Я придерживаюсь коротких окон анализа, удаляю старые журналы и защищаю файл от несанкционированного доступа. Доступ.
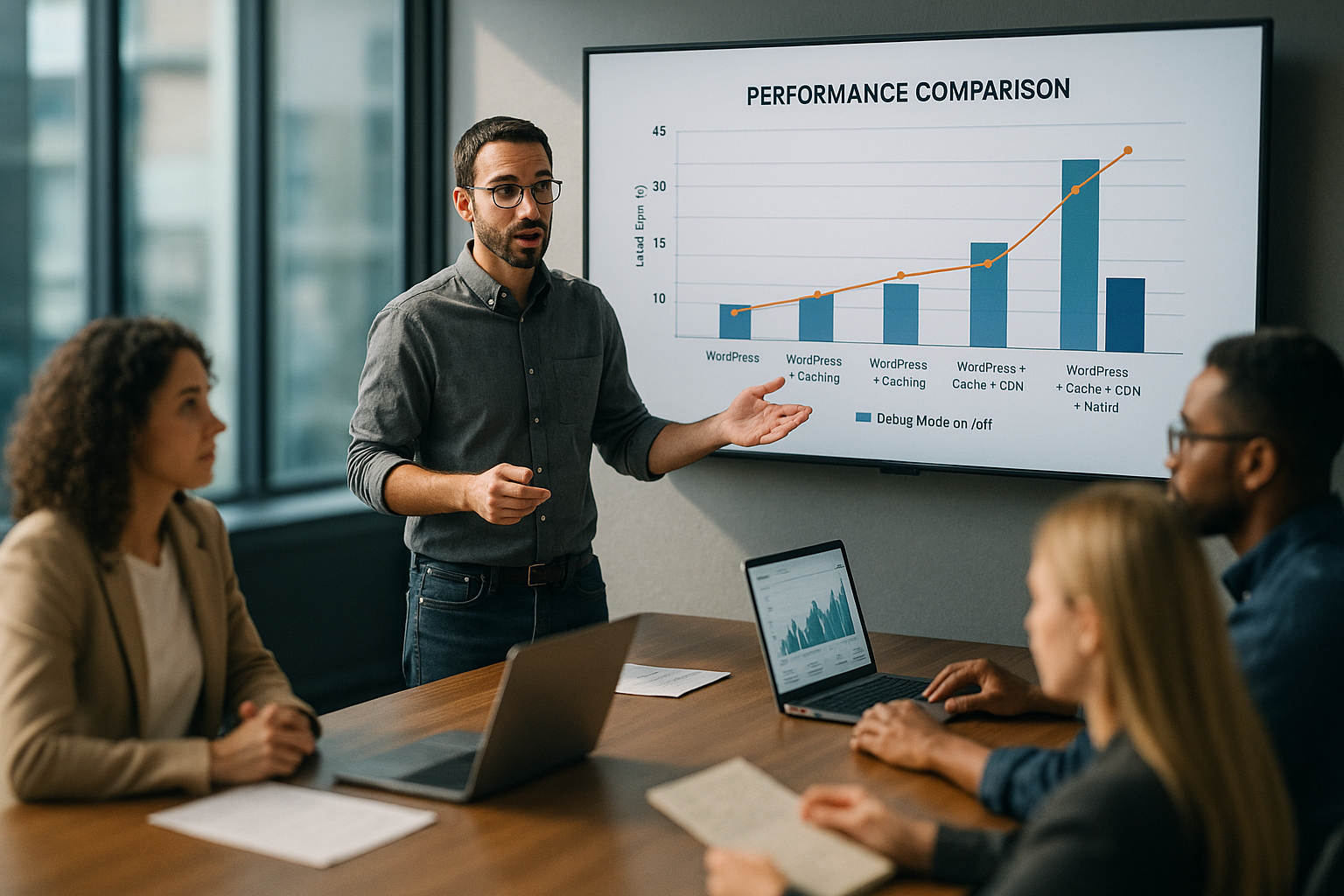
Сравнение измеренных значений: без отладки и с отладочной регистрацией
Замедление легко измерить, поскольку TTFB и нагрузка на сервер явно смещаются при отладочном протоколировании. Я часто измеряю короткое время отклика без активного протоколирования, которое заметно увеличивается при протоколировании. Это касается не только фронтенд-видов, но и действий администратора, вызовов AJAX и конечных точек REST. Даже если содержимое статически поступает из кэша, дополнительная нагрузка на ведение журнала замедляет запрос. В следующей таблице я привожу типичные примеры Наклонности вместе.
| Коэффициент полезного действия | Без отладки | С отладочным протоколированием |
|---|---|---|
| TTFB (мс) | ≈ 200 | ≈ 1500+ |
| Нагрузка на сервер | Низкий | Высокий |
| Размер журнала (в день) | 0 МБ | 50-500 МБ |
Эти диапазоны отражают общие наблюдения и показывают, как медленная отладка wp создается. Я анализирую трассировки APM, тайминги страниц и статистику сервера. Я также смотрю на профилирование файловой системы, чтобы визуализировать амплитуды записи. Закономерность очевидна: большее количество сообщений приводит к увеличению доли ввода-вывода в запросе. В целом, задержка увеличивается, несмотря на то, что сам PHP-код якобы равный остается.

Почему кэширование мало помогает в борьбе с накладными расходами
Кэш страниц и объектов сокращает работу PHP, но запись в журнал происходит до и после. Каждое уведомление генерирует новый Пишите-операция, независимо от того, получен ли HTML-ответ из кэша. Таким образом, TTFB и отклик бэкенда остаются повышенными, несмотря на наличие кэша. Я все равно использую кэш, но не жду от него чудес, пока отладочный логгинг остается активным. Что действительно важно для облегчения работы, так это отключение источника, а не маскировка его с помощью Кэш.
Безопасное включение и еще более быстрое выключение
Я включаю логирование специально, работаю целенаправленно и отключаю его сразу после анализа. Вот как я настраиваю его в wp-config.php и держу вывод вдали от фронтенда:
define('WP_DEBUG', true);
define('WP_DEBUG_LOG', true);
define('WP_DEBUG_DISPLAY', false);
@ini_set('display_errors', 0);
Затем я проверяю соответствующие просмотры страниц, изолирую источник и устанавливаю WP_DEBUG снова на false. Наконец, я удаляю раздутый debug.log, чтобы сервер больше не жонглировал мертвыми данными. Такая дисциплина экономит время и сохраняет Производительность в повседневной жизни.

Ротация и обслуживание журналов: маленькие шаги, большой эффект
Выращивание без ротации журнал отладки не отмечен, пока количество обращений на запись не выйдет из-под контроля. Поэтому я установил ежедневное сжатие и удаляю старые файлы через некоторое время. Этот простой шаг значительно снижает объем ввода-вывода, поскольку активный файл журнала остается небольшим. Я также использую regex для фильтрации типичных шумов, чтобы уменьшить поток. Если вы хотите углубиться, вы также можете проверить уровни ошибок PHP и обработчики ошибок для Зернистость.
Безопасное считывание ошибок: Защита от посторонних глаз
Журналы отладки не должны быть общедоступными, иначе пути и ключи попадут в чужие руки. Я закрываю файл в Webroot последовательно, например, через .htaccess:
Порядок Разрешить, Запретить
Запретить всем
Я установил эквивалентные правила на NGINX, чтобы прямая загрузка была невозможна. Я также устанавливаю ограничительные разрешения на файлы, чтобы ограничить доступ до минимума. Безопасность превыше удобства, потому что журналы часто показывают больше, чем ожидается. Короткие интервалы между проверками и аккуратные журналы минимизируют поверхность атаки. маленький.

Найдите источник ошибки: Инструменты и процедура
Чтобы сузить круг поиска, я использую постепенное отключение плагинов и целенаправленное Профилирование. Тем временем я анализирую строки журнала с помощью хвоста и фильтров, чтобы быстро определить самые громкие сообщения. Для более глубокого анализа я использую Практика работы с монитором запросов, для отслеживания хуков, запросов и HTTP-вызовов. В то же время я измеряю TTFB, время работы PHP и длительность работы базы данных, чтобы четко определить узкое место. Только когда источник проблемы определен, я снова активирую плагин или корректирую код так, чтобы он не Шум остается.
Выбирайте ресурсы хостинга с умом
Ведение журнала отладки особенно заметно на медленном оборудовании, поскольку каждый Пишите-операция занимает больше времени. Поэтому я полагаюсь на быстрый ввод-вывод, достаточный резерв процессора и подходящие ограничения для процессов. Это включает в себя хорошую конфигурацию рабочего PHP и четкое разделение staging и live. Если вы используете staging, вы можете тестировать обновления без пиков нагрузки и с чистой совестью активировать громкое протоколирование. Больший запас прочности помогает, но я решаю проблему так, чтобы WordPress мог работать без Тормоза бежит.
Тонкая настройка параметров WP и PHP
Я использую дополнительные регулировочные винты в wp-config.php, чтобы точно контролировать громкость и минимизировать побочные эффекты:
// Измените путь: Ведите журнал за пределами webroot
define('WP_DEBUG_LOG', '/var/log/wp/site-debug.log');
// Только временно увеличиваем объем, затем снова отключаем
@ini_set('log_errors', 1);
@ini_set('error_reporting', E_ALL & ~E_NOTICE & ~E_DEPRECATED & ~E_STRICT);
Я использую выделенный путь для хранения файла журнала вне webroot и отделяю его от развертываний. О сайте сообщение об ошибках Я намеренно приглушаю шум, когда в первую очередь ищу трудные ошибки. Как только я переключаюсь на staging, я снова использую E_NOTICE и E_DEPRECATED, чтобы проработать старые проблемы.
SAVEQUERIES, SCRIPT_DEBUG и скрытые тормоза
Некоторые переключатели развивают сильный тормозной эффект только в комбинации. SAVEQUERIES Регистрирует каждый запрос к базе данных в структурах памяти PHP и увеличивает нагрузку на процессор и оперативную память. SCRIPT_DEBUG заставляет WordPress загружать активы без минимизации; хорошо для аналитики, но хуже для времени загрузки. Я активирую эти переключатели только в строго ограниченное время и только в тестовых средах. Я также определяю WP_ENVIRONMENT_TYPE (например, “staging” или “production”), чтобы условно контролировать поведение в коде и избегать неправильных конфигураций.
Факторы сервера: PHP-FPM, хранение и блокировка файлов
На уровне сервера я принимаю решение о заметном эффекте: пулы PHP FPM со слишком малым количеством рабочих перегружают запросы, а чрезмерно большие пулы увеличивают конкуренцию за ввод-вывод. Я создаю отдельные пулы для каждого сайта или критического маршрута (например, /wp-admin/ и /wp-cron.php), чтобы свести к минимуму столкновения между логированием и работой бэкенда. Что касается хранения данных, то локальные тома NVMe работают значительно лучше, чем медленные сетевые файловые системы, где блокировки файлов и задержки многократно усиливают эффект от ведения логов. С помощью медленного лога PHP-FPM я выявил узкие места, вызванные частыми error_log()-Звонки или время ожидания блокировки.
Разгрузка: Syslog, Journald и удаленная доставка
Если я не могу полностью отключить ведение журнала, я разгружаю жесткий диск с помощью выгрузки. PHPs журнал ошибок может отправлять сообщения в Syslog, которые затем буферизируются и обрабатываются асинхронно. Это уменьшает амплитуду записи в локальные файлы, но перекладывает усилия на подсистему журнала. Важно ограничить скорость, иначе я просто поменяю местами узкие места. Для коротких тестов я предпочитаю локальные файлы (лучше контроль), для более длительных анализов - короткие фазы выгрузки с четким лимитом отключения.
Целевое окно отладки с помощью плагина MU
Я ограничиваю отладку только собой или временным окном, чтобы не мешать продуктивным пользователям. Небольшой плагин MU включает отладку только для администраторов с определенного IP или cookie:
<?php
// wp-content/mu-plugins/targeted-debug.php
if (php_sapi_name() !== 'cli') {
$allow = isset($_COOKIE['dbg']) || ($_SERVER['REMOTE_ADDR'] ?? '') === '203.0.113.10';
if ($allow) {
define('WP_DEBUG', true);
define('WP_DEBUG_LOG', '/var/log/wp/site-debug.log');
define('WP_DEBUG_DISPLAY', false);
@ini_set('log_errors', 1);
@ini_set('error_reporting', E_ALL);
}
}
Таким образом, я регистрирую только свои собственные репродукции и избавляю остальных посетителей. После завершения работы я удаляю плагин или стираю cookie.
Ротация на практике: надежно и безопасно
Я вращаю журналы с помощью компактных правил и обращаю внимание на дескрипторы открытых файлов. copytruncate полезно, если процесс не открывает файл повторно; в противном случае я использую создать и подает сигнал PHP-FPM, чтобы новые записи попадали в свежий файл. Пример:
/var/log/wp/site-debug.log {
ежедневно
ротация 7
сжимать
missingok
notifempty
создать 0640 www-data www-data
postrotate
/usr/sbin/service php8.2-fpm reload >/dev/null 2>&1 || true
endscript
}
Кроме того, я держу активный файл журнала небольшим (<10-50 МБ), потому что короткие поисковые запросы, greps и tails работают заметно быстрее и генерируют меньше каскадов пропусков кэша в файловой системе.
Регистрация в WooCommerce и специфических плагинах
Некоторые плагины имеют свои собственные регистраторы (например, WooCommerce). Я устанавливаю в них пороговые значения “ошибка” или “критический” и деактивирую каналы “отладки” в производстве. Это уменьшает двойной протоколирования (WordPress и плагин) и защищает вход/выход. Если я подозреваю ошибку в плагине, я специально увеличиваю уровень, а затем сразу же сбрасываю его.
Многосайтовость, постановка и контейнеры
В многосайтовых установках WordPress собирает сообщения в общий журнал отладки. Я намеренно распределяю их по сайтам (отдельный путь для каждого ID блога), чтобы отдельные “громкие” сайты не тормозили остальные. В контейнерных средах я временно пишу в /tmp (быстро), архивировать специально и отбрасывать содержимое при перестройке. Важно: даже если файловая система работает быстро, загрузка процессора при форматировании остается - поэтому я продолжаю устранять причину.
Стратегия тестирования: чистые измерения вместо догадок
Я сравниваю одинаковые запросы с протоколированием и без него при стабилизированных условиях: одинаковый прогрев кэша, одинаковые рабочие PHP FPM, одинаковая нагрузка. Затем я измеряю TTFB, время работы PHP, время работы БД и время ожидания ввода-вывода. Кроме того, я провожу нагрузочные тесты в течение 1-5 минут, поскольку эффект от больших логов и борьбы с блокировками становится заметен только при непрерывной записи. Только когда измерения совпадают, я получаю результаты.
Защита и хранение данных
Журналы могут содержать личные данные (например, параметры запроса, адреса электронной почты в запросах). Я свожу их хранение к минимуму, анонимизирую, где это возможно, и последовательно удаляю после завершения работы. Для команд я документирую время начала и окончания окна отладки, чтобы никто не забыл удалить журнал снова. Таким образом, я минимизирую риски, требования к хранению и накладные расходы.
Краткое резюме
Активный Ведение журнала отладки замедляет работу WordPress, потому что каждый запрос вызывает операции записи и форматирования, которые увеличивают TTFB и нагрузку на сервер. Я специально активирую ведение журнала, фильтрую сообщения, поворачиваю файл журнала и блокирую доступ к debug.log. В производственных средах ведение журнала остается исключением, в то время как стейджинг - правило. Кэширование облегчает симптомы, но не устраняет накладные расходы на каждый запрос. Если вы последовательно устраняете причины, вы обеспечиваете скорость, экономите ресурсы и сохраняете производительность wordpress постоянно высокий.


