 Zum Inhalt springen
Zum Inhalt springen 
Viele 500er-Fehler entstehen durch übersehene Database Connection Limits im Hosting, die bei Spitzenlast oder fehlerhaften Skripten neue Verbindungen blockieren. Ich zeige klar, wie die Ursache entsteht, woran du sie erkennst und wie du deine Seite wieder zuverlässig auslieferst.
Zentrale Punkte
Damit du schneller handeln kannst, fasse ich die wichtigsten Aspekte kurz zusammen.
- Ursache: Erreichte MySQL-Verbindungsgrenzen lösen oft 500er-Fehler aus.
- Erkennung: Logs mit „Too many connections“ und hohe Threads_connected.
- Abhilfe: Connection-Pooling, Query-Tuning, Caching und Limits anheben.
- Hosting: Shared-Pläne haben enge Limits, VPS erlaubt Feintuning.
- WordPress: Plugins, Cron und Backups erzeugen übermäßig viele Verbindungen.
Die Punkte greifen ineinander und erklären, warum einzelne Anpassungen oft nicht reichen. Ich setze darum auf einen Mix aus Optimierung und sauberem Betriebssetup. So vermeidest du Rückfälle nach Traffic-Spitzen. Zusätzlich profitierst du von geringeren Antwortzeiten. Das wiederum stabilisiert Conversion und SEO-Signale.

Was steckt hinter 500er-Fehlern?
Ein 500 Internal Server Error wirkt zufällig, doch er signalisiert oft ein klares Backend-Problem. Typisch: PHP-Skripte laufen heiß, die Datenbank bremst oder Rechte stimmen nicht. Erreichen Anfragen das Connection-Limit, scheitert der nächste Zugriff und die App wirft einen 500er. Ich prüfe zuerst Logs und Fehlermeldungen, weil dort die Hinweise stehen. Danach konzentriere ich mich auf Datenbankzugriffe, denn Verbindungen sind teurer als viele vermuten.
Fehlerbilder richtig einordnen
Nicht jeder Ausfall ist gleich: 500er stammen häufig aus der Applikation, 502 deutet auf Proxy-/Gateway-Probleme hin und 503 auf eine temporäre Überlast. In der Praxis sehe ich Mischbilder – z. B. 503 vom Webserver, weil PHP-FPM keine Worker mehr frei hat, und 500 aus PHP, weil die Datenbank keine Verbindung annimmt. Ich trenne die Ebenen: Webserver- und PHP-FPM-Logs für Prozessknappheit, Applikationslogs für Exceptions, MySQL-Logs für Limits und Locks. So vermeide ich, am falschen Regler zu drehen.
Wie Limits in MySQL wirken
MySQL begrenzt gleichzeitige Verbindungen über max_connections; Hoster setzen dafür oft konservative Werte. In Shared-Umgebungen sind pro Kunde 100–200 Verbindungen üblich, global teilweise 500. Wenn Threads_connected in Richtung des Limits klettert, steigen Wartezeiten und Abbrüche. Der Fehler „SQLSTATE[08004] [1040] Too many connections“ zeigt genau das an. Ich beobachte die Threads-Metrik und gleiche sie mit Traffic-Spitzen, Cron-Läufen und Crawler-Aktivität ab.
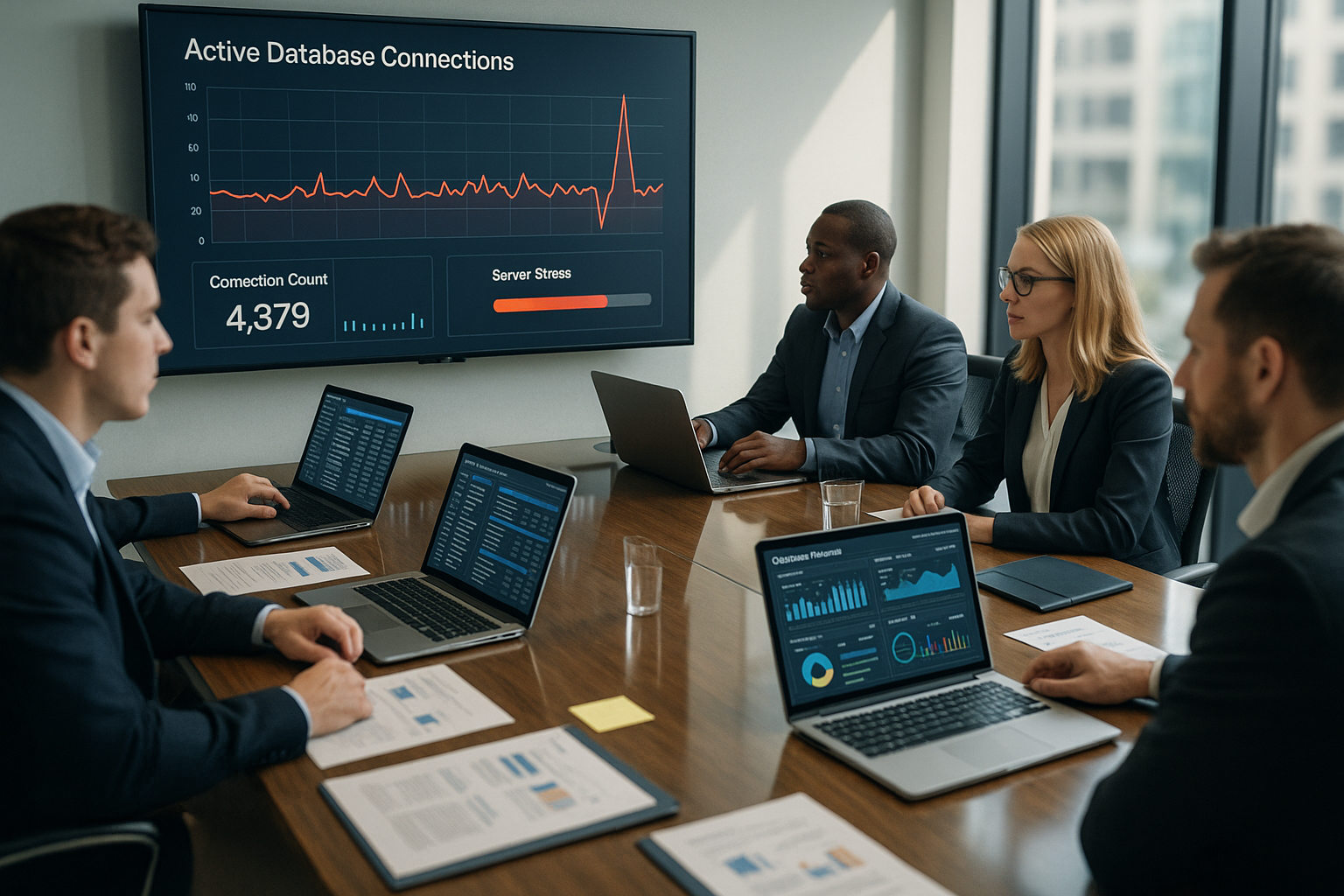
Grenzwerte und Timeouts richtig setzen
Neben max_connections spielen max_user_connections (pro Benutzer) und wait_timeout (Leerlaufzeit) eine Rolle. Zu hohe Timeouts halten Verbindungen unnötig lange offen, zu kurze führen zu häufigen Neuaufbauten. Ich setze Timeouts so, dass typische Requests vollständig laufen, aber Leerlauf schnell freigegeben wird. thread_cache_size verkürzt zudem Handshake-Kosten, weil Threads wiederverwendet werden. Wichtig: Jede zusätzliche Verbindung verbraucht RAM (Thread-Stack, Buffer) – wer max_connections blind erhöht, riskiert Swapping und noch mehr Latenz.
Typische Auslöser im Alltag
Spitzen durch Bots oder Kampagnen lassen Verbindungen in Sekunden an die Decke gehen. Ineffiziente SQLs blockieren Slots länger als nötig und erzeugen Rückstau. Viele WordPress-Plugins sammeln bei jedem Seitenaufruf Queries, die sich addieren. Parallel laufende Backups, Cron-Jobs oder Importer verschärfen die Lage. Ich drossele zuerst aggressive Crawler und räume alte Plugins auf, bevor ich tiefer in das Tuning einsteige.
Feinere Diagnose in der Praxis
Ich aktiviere das Slow-Query-Log mit sinnvollem Schwellenwert und schaue mir die Top-Verursacher nach Laufzeit und Häufigkeit an. performance_schema liefert Wartezeiten nach Typ (Locks, I/O), sodass ich sehe, ob die Datenbank rechnet oder wartet. SHOW PROCESSLIST zeigt blockierte oder schlafende Verbindungen; lange „Sleep“-Einträge deuten auf schlechte Verbindungspolitik hin, lange „Query“-Einträge auf teure SQLs. Für Mustervergleiche exportiere ich Metriken und prüfe, ob Peaks mit Deployments, Cron-Läufen oder Bot-Wellen korrelieren.
Erkennen und Diagnostizieren
Ich starte mit den Error-Logs und suche nach „Too many connections“ oder „Error establishing a database connection“. Danach prüfe ich den aktuellen Verbindungsstand, etwa mit SHOW STATUS LIKE ‚Threads_connected‘; und dem gesetzten max_connections. Steht der Zähler kurz vor dem Limit, liegt der Engpass offen. In WordPress deaktiviere ich testweise Erweiterungen und messe erneut die Query-Last. So lokalisieren ich den Treiber und entscheide, ob ich Caching oder Refactoring vorziehe.
PHP-FPM und Webserver im Zusammenspiel
Ich halte die Zahl der gleichzeitigen PHP-Worker im Einklang mit den Datenbankverbindungen. Zu viele Worker erzeugen Stau an der Datenbank, zu wenige verschenken Durchsatz. Im PHP-FPM-Management (pm, pm.max_children, pm.max_requests) lege ich eine Obergrenze fest, die zur DB passt, und nutze Warteschlangen statt unkontrollierter Parallelität. Webserver-seitig helfen Verbindungs- und Request-Limits, um harte Peaks abzufedern, ohne die Datenbank zu überrennen. Damit verschwinden viele „Zufalls-500er“, weil die Last geordnet abgearbeitet wird.
Sofortmaßnahmen bei Ausfällen
Bei akuten 500ern setze ich auf gezielte Notmaßnahmen mit geringem Risiko. Ich erhöhe das PHP-Memory-Limit moderat, reduziere gleichzeitige Crawls und pausiere Backups. Falls nötig, starte ich PHP-FPM neu und glätte damit hängende Prozesse. Für feinere Steuerung nutze ich Hinweise aus dem Leitfaden zu PHP-FPM Prozess-Management. Danach sorge ich mit IP-Rate-Limits und Bot-Regeln für kurzfristige Entlastung.

Verbindungsmanagement in der Applikation
Ich unterscheide strikt zwischen kurzlebigen und persistenten Verbindungen. Persistente Verbindungen sparen Handshakes, können in Shared-Umgebungen aber Slots „verkleben“ und Limits schneller reißen. Ohne Pooling setze ich daher lieber auf kurze, saubere Connect–Query–Close-Zyklen. In Umgebungen mit eigenem Proxy (z. B. Pooling-Layer) lohnen persistente Backends, während die App gegen den Pool spricht. Wichtig ist, Verbindungslecks zu verhindern: Jeder Code-Pfad muss sauber schließen, auch bei Exceptions und Timeouts.
Dauerhafte Entlastung durch Connection-Pooling
Statt jede Anfrage eine neue DB-Verbindung öffnen zu lassen, bündelt Pooling Verbindungen und hält sie bereit. Das spart Handshakes, senkt Latenz und vermeidet harte Limits. Für MySQL eignen sich ProxySQL oder ähnliche Layer; für Postgres etwa pgbouncer. Ich setze Pool-Parameter passend zu Query-Dauer, Timeouts und erwarteter Parallelität. Wer sich einarbeiten will, startet mit diesem kompakten Überblick zu Datenbank-Pooling. Richtig eingestellt reduziert Pooling die Last drastisch und glättet Peaks.
SQL- und Schema-Optimierung
Ich prüfe langsame Abfragen, setze fehlende Indizes und vereinfache Joins. Häufig hilft ein schlanker Select, der nur benötigte Spalten zieht. Für „heiße“ Tabellen lohnt sich eine gezielte Partitionierung oder ein sinnvoller Covering-Index. Objekt-Cache mit Redis entlastet Leselast deutlich, weil weniger Queries abgesetzt werden. So sinkt die Zahl gleichzeitiger Verbindungen, und das Risiko von Timeouts fällt.

Transaktionen, Locks und Deadlocks
Lange laufende Transaktionen halten Locks und blockieren andere Queries – die Folge sind wachsende Warteschlangen und explodierende Verbindungszahlen. Ich sorge für kurze Transaktionen, vermeide große Batch-Updates im Live-Betrieb und prüfe die Isolationsebene. Deadlocks erkenne ich in den Logs oder via Status-Ausgabe; oft genügt es, die Zugriffreihenfolge auf Tabellen zu vereinheitlichen oder Indizes zu ergänzen. Auch Wiederholungen mit Backoff reduzieren Druckspitzen, ohne neue Verbindungen zu erzeugen.
Hosting-Optionen und Limits im Vergleich
Enge Limits treffen besonders Projekte mit vielen gleichzeitigen Besuchern. Ein Wechsel in eine stärker isolierte Umgebung verhindert, dass fremde Last deine App bremst. Auf einem VPS steuerst du max_connections selbst und passt die MySQL-Puffer an deinen Datensatz an. Ich achte zusätzlich auf NVMe-SSDs und genügend CPU-Kerne. Die folgende Übersicht zeigt typische Limits und Einsatzzwecke, die dir bei der Planung helfen.
| Hosting-Typ | MySQL max connections pro User | Geeignet für |
|---|---|---|
| Shared Basic | 100 | Kleine Sites, Testinstanzen |
| Shared Premium | 150–200 | WordPress mit moderatem Traffic |
| VPS | Konfigurierbar | Shop, Kampagnen, API-Backends |
| Dedicated / Root | Frei wählbar | Hohe Parallelität, große Datenbanken |
Skalierungsmuster: Lesen skalieren, Schreiben schützen
Ich entlaste die Primärdatenbank, indem ich Leselast auf Replikate verschiebe. Das lohnt sich, wenn der Anteil an Reads hoch ist und die Anwendung mit leicht verzögerten Daten umgehen kann. Verbindungslimits gelten jedoch für jede Instanz separat – Pooling und Limits plane ich daher pro Rolle (Primary/Replica). Für Schreibspitzen setze ich auf Queueing, damit teure Jobs asynchron laufen und Frontend-Zugriffe flüssig bleiben. So wächst die Kapazität, ohne überall die Limits anzuheben.
WordPress-spezifische Schritte
Ich beginne mit einem vollständigen Backup, prüfe danach wp-config.php und deaktiviere unnötige Plugins. Ein Objekt-Cache reduziert Query-Last pro Seite deutlich. Heartbeat-Intervalle senken Editor- und Dashboard-Druck auf die Datenbank. Für die Serverseite schaue ich mir die Verteilung der PHP-Worker an; ein kurzer Blick in den PHP-Worker Ratgeber hilft bei Engpässen. So bringe ich WordPress in eine Balance, die Limits seltener trifft.

WordPress: Praxis-Tuning für hohe Parallelität
Mit Page-Cache (wo möglich) schiebe ich anonyme Requests aus PHP heraus und entlaste die DB massiv. Für WooCommerce und andere dynamische Bereiche nutze ich selektives Caching und stelle sicher, dass Cart/Checkout vom Cache ausgenommen sind. Ich verschiebe WP-Cron auf einen System-Cron, damit Jobs planbar und nicht bei Besucherzugriffen ausgelöst werden. admin-ajax und die REST-API beobachte ich gesondert – sie sind oft Treiber für viele kleine, gleichzeitige Anfragen, die Verbindungen belegen.
Monitoring und Bot-Steuerung
Ohne Messpunkte bleibt die eigentliche Ursache oft verborgen. Ich tracke Verbindungen, Query-Dauer, Error-Raten und CPU-Last in kurzen Intervallen. Alarmregeln warnen mich vor Peaks, bevor Nutzer Fehler sehen. In der robots.txt drossele ich Crawler, setze Crawl-Delay und sperre aggressive Bots. Kombiniert mit Rate-Limits auf IP-Ebene bleibt die Verfügbarkeit hoch, selbst wenn Kampagnen starten.

Fallback-Strategien für Ausfallsicherheit
Ich plane ein Degradationsverhalten: Bei Überlast liefert der Edge-Cache „stale while revalidate“, statt 500er zu werfen. Für kritische Seiten existieren statische Fallbacks, die automatisch greifen, wenn Backends nicht verfügbar sind. Eine freundliche Fehlerseite mit geringer Größe hilft, Lastspitzen abzufangen und Nutzer zu halten. Zusammen mit Connection-Pooling ergibt das ein robustes Verhalten – die Datenbank bleibt erreichbar, und die Anwendung bleibt bedienbar, selbst wenn einzelne Komponenten schwächeln.
Schnell-Checkliste für weniger 500er
- Threads_connected und Logs prüfen, „Too many connections“ identifizieren.
- PHP-FPM-Worker so begrenzen, dass sie zur DB-Kapazität passen.
- Pooling einführen und Timeouts/Größen an Anfrageprofil anpassen.
- Slow-Query-Log auswerten, Indizes setzen, teure SQLs entschlacken.
- Page-/Objekt-Cache aktivieren, Crawler drosseln, Rate-Limits setzen.
- WP-Cron entkoppeln, unnötige Plugins entfernen, Heartbeat reduzieren.
- Backups/Importer außerhalb der Peak-Zeiten, Transaktionen kurz halten.
- Monitoring mit Alarmgrenzen einrichten, Fallback-Strategien testen.
Kurz zusammengefasst
Erreichte Connection-Limits sind eine häufige, versteckte Ursache für 500er-Fehler. Ich löse das nachhaltig, indem ich Pooling einsetze, Queries entschlanke und Hosting-Limits passend wähle. WordPress profitiert spürbar von Caching, weniger Plugins und sauber konfigurierten PHP-Workern. Monitoring und Bot-Regeln verhindern, dass dich nächste Peaks kalt erwischen. Wer diese Schritte umsetzt, hält seine Seite reaktionsschnell und senkt das Fehlerrisiko deutlich.


