
Hetzner robot bündelt alles, was ich für echte Serververwaltung brauche: vom ersten Login über OS-Installationen bis zu Monitoring, IP-Management und Support. In diesem Leitfaden zeige ich Schritt für Schritt, wie ich die Oberfläche souverän nutze, typische Aufgaben löse und meine Server sicher betreibe.
Zentrale Punkte
- Dashboard: klare Übersicht, schnelle Aktionen
- OS-Installationen: Auto-Installer, Rescue, Custom
- Netzwerk: IPs, rDNS, vSwitch, Firewall
- Monitoring: Statistiken, Alarme, Benachrichtigungen
- Support: Tickets, Hardwaretausch, Protokolle
Was ist Hetzner Robot?
Die Oberfläche Hetzner Robot dient mir als zentrale Steuerung für Dedicated Root Server, Colocation, Storage-Boxen und Domains. Ich greife über den Browser zu, löse Reboots aus, starte das Rescue-System oder setze Betriebssysteme neu auf. Alle Maschinen erscheinen in einer Liste mit Filter- und Suchfunktionen, damit große Setups nicht ausufern. Praktisch: Ich sehe Hardwaredaten, verfügbare Upgrades und kann bei Bedarf über die Serverbörse (SB-Server) passend erweitern. Die Abläufe bleiben schlank, sodass ich Änderungen schnell und sicher umsetze.

Erster Login und Schutz des Zugangs
Nach der Bereitstellung erhalte ich Zugangsdaten und melde mich über eine SSL-geschützte Oberfläche an, um direkt loszulegen und meinen Zugang zu sichern. Ich aktiviere sofort die Zwei-Faktor-Authentifizierung (2FA), damit kein Konto ohne zweiten Faktor erreichbar ist. Außerdem setze ich ein starkes Passwort mit ausreichender Länge und Zeichenvielfalt. Für Telefonanfragen hinterlege ich ein separates Telefonpasswort, um Support-Kontakte abzusichern. Wer systematisch vorgehen möchte, findet in diesem kompakten Leitfaden zur Root-Server-Sicherheit eine klare Checkliste.
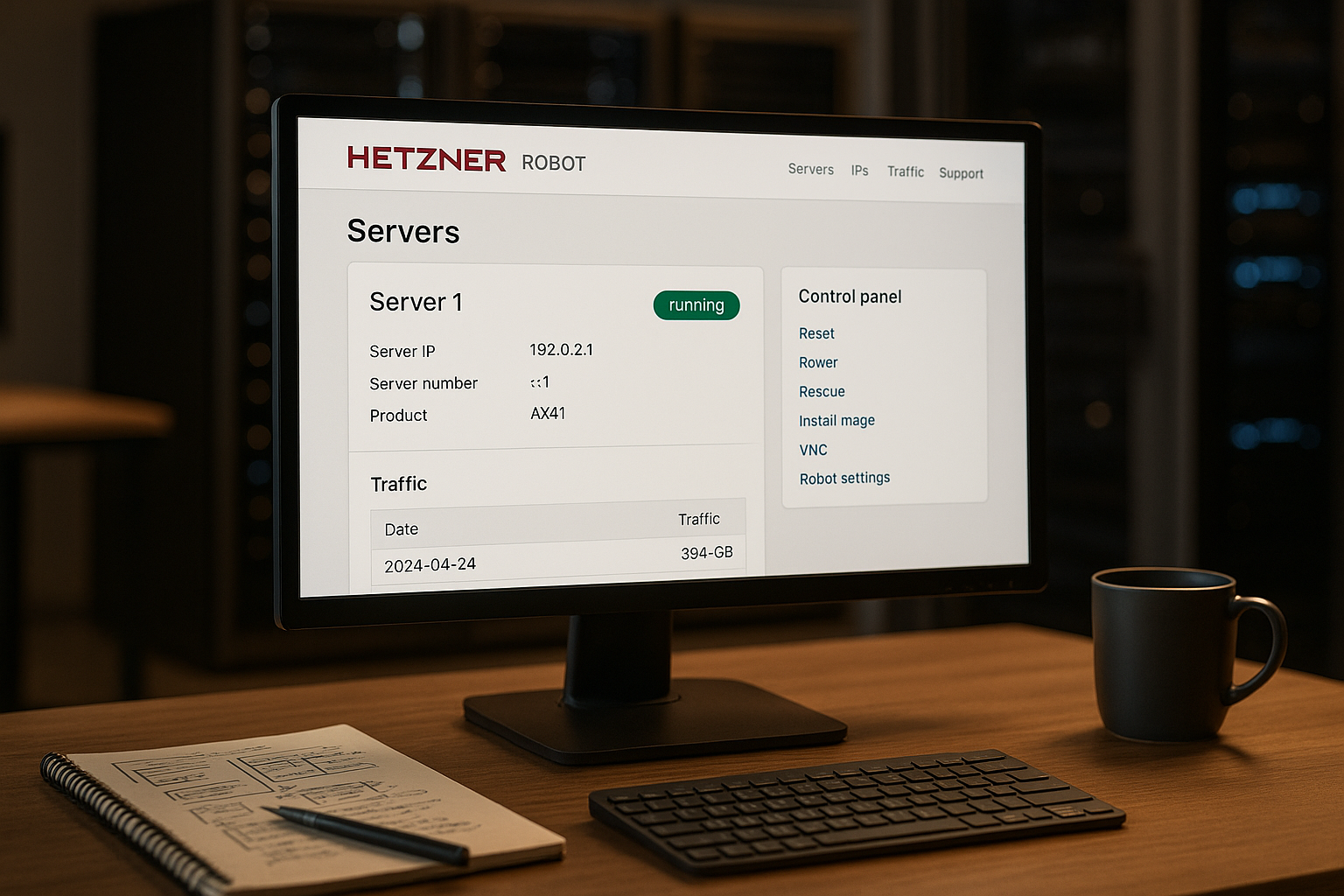
Das Dashboard sicher beherrschen
Im Dashboard öffne ich mit wenigen Klicks die wichtigsten Funktionen: Reset, Monitoring, IP-Management, Domainverwaltung und mehr. Ich filtere Server nach Labels, Projekten oder Hardwaremerkmalen, um den Blick auf das Wesentliche zu lenken. Über Schnellaktionen starte ich einen Soft- oder Hard-Reboot oder boote in das Rescue-System, wenn ein System hängt. Ein Suchfeld spart mir Zeit, wenn ich einen einzelnen Host fix finden muss. So halte ich die tägliche Arbeit schlank, insbesondere bei vielen Maschinen.

Server-Übersicht und Kernfunktionen
In der Server-Ansicht prüfe ich Hardware, Laufzeiten, Ports und verfügbare Upgrades auf einen Blick. Ich kontrolliere Temperatur, Laufwerksstatus und kann bei Bedarf Komponenten tauschen lassen. Über die Oberfläche starte ich Remote-Resets oder setze SSH-Keys, ohne mich auf jeden Host per Konsole zu verbinden. rDNS-Einträge editiere ich an derselben Stelle, damit Mail-Server und Logs sauber laufen. Das spart Zeit und verringert das Fehlerrisiko bei wiederkehrenden Aufgaben.
Benutzer, Rechte und Arbeitsabläufe strukturieren
Damit Teams geordnet arbeiten, trenne ich Zugriffe konsequent: Ich richte zusätzliche Nutzerkonten mit begrenzten Rechten ein und weise ihnen nur die Server, IPs und Domains zu, die sie wirklich brauchen. Sensible Aktionen wie Reinstall, Reset oder IP-Routing erlaube ich nur ausgewählten Accounts. Für externe Helfer setze ich zeitlich begrenzte Zugänge und dokumentiere, wer wann welche Aufgabe übernimmt. So verhindere ich Seiteneffekte und halte Verantwortlichkeiten transparent.
Betriebssysteme installieren und neu aufsetzen
Für OS-Installationen nutze ich den Auto-Installer oder boote in das Rescue-System, um mit installimage ein individuelles Setup zu schreiben. Linux-Distributionen wie Debian, Ubuntu, AlmaLinux oder Rocky Linux setze ich mit wenigen Eingaben auf. Windows-Images stehen ebenfalls bereit, falls ich bestimmte Software-Stacks brauche. Vor einer Neuinstallation sichere ich Daten und dokumentiere Besonderheiten (z. B. Software-Lizenzen). Wer die Grundlagen zu Hardware, RAID und OS-Wahl auffrischen möchte, profitiert vom kompakten Dedicated-Server-Guide.
Installationen vertiefen: Partitionen, RAID, Verschlüsselung
Mit installimage formatiere ich gezielt: Ich lege GPT-Partitionsschemata an, wähle Software-RAID (z. B. RAID1/10) und entscheide, ob ich LVM für flexible Volumes nutze. Für sensible Daten aktiviere ich LUKS-Verschlüsselung und halte den Schlüssel getrennt vom Server bereit. UEFI- oder BIOS-Boot wähle ich entsprechend der Hardware. Nach dem ersten Boot lasse ich Post-Install-Skripte laufen, die Pakete, User und Dienste automatisiert einrichten. So erhalte ich reproduzierbare Systeme mit identischem Grundzustand.
Remote-Konsole und Out-of-Band-Zugriff
Wenn ein Host nicht mehr über SSH erreichbar ist oder der Bootloader hängt, greife ich über die Remote-Konsole zu. Darüber sehe ich Kernel-Meldungen, BIOS/UEFI und kann interaktiv ins Rescue-System wechseln. Ich halte Zugangsdaten und ein minimales Toolset bereit, um Netz und Dienste wieder hochzubringen. Out-of-Band-Zugänge plane ich fest ein, damit ich auch bei Netzwerkfehlern administrieren kann.
Netzwerk, IPs und rDNS sauber managen
Über das IP-Management bestelle ich zusätzliche Adressen, lege rDNS-Einträge fest und strukturiere Subnetze für saubere Segmentierung. VLANs und vSwitch nutze ich, um Server logisch zu koppeln oder Traffic zu isolieren. So trenne ich produktive Workloads von Testsystemen und halte Broadcast-Domänen überschaubar. Firewall-Regeln setze ich restriktiv, dokumentiere Ausnahmen und prüfe regelmäßig, ob offene Ports noch nötig sind. Damit baue ich mir eine kontrollierte und nachvollziehbare Netzstruktur auf.
Failover-IP und Migration ohne Downtime
Für Wartungen und Umzüge plane ich mit Failover-IPs. Ich weise die Adresse dem Zielserver zu und schalte das Routing um, sobald Dienste bereitstehen. Vorher teste ich rDNS, Firewall und Health-Checks, damit der Wechsel in Sekunden erfolgt. Für größere Migrationen arbeite ich mit doppeltem Betrieb: Daten werden vorab synchronisiert, dann wechsle ich die IP und lasse alten Traffic kontrolliert auslaufen. So minimiere ich Unterbrechungen und behalte die Kontrolle.
Zugang, Rescue-System und Notfälle
Ich hinterlege meinen SSH-Key direkt in der Oberfläche, damit ich Passwörter meide und mich sicher anmelde. Bei Problemen fahre ich den Server in das Rescue-System, prüfe Logs und Dateisysteme und setze Dienste wieder instand. Hard-Reset nutze ich nur, wenn Soft-Reboot oder ein normaler Shutdown nicht greifen. Zusätzlich sichere ich einen Out-of-Band-Zugang, damit ich auch bei Netzwerkfehlern handlungsfähig bleibe. Diese Routinen verkürzen Ausfallzeiten spürbar.

Monitoring und Alarme
Für die Überwachung schaue ich mir Live-Statistiken zu Traffic, Erreichbarkeit und Antwortzeiten an. Ich setze Schwellenwerte und lasse mir E-Mails senden, sobald Werte kippen. Wer Skripting mag, koppelt eigene Checks via API und steuert Benachrichtigungen über externe Systeme. Ich prüfe Alarme regelmäßig, damit ich Schwellen sinnvoll anpasse und keine Flut auslöse. So halte ich die Balance zwischen frühzeitiger Warnung und Ruhe im Alltag.
DDoS-Filter, Performance und Kapazitätsplanung
Unerwarteter Traffic gehört zum Alltag. Ich nutze Filter gegen volumetrische Angriffe, beobachte Paketraten und identifiziere Auffälligkeiten in den Traffic-Grafen. Performance plane ich vorausschauend: Ich definiere Grenzwerte für CPU, RAM, I/O und Netzwerk, bevor es eng wird. Bei planbaren Peaks skaliere ich temporär, bei dauerhafter Last migriere ich gezielt auf stärkere Hardware. Wichtig: Monitoring-Schwellen wachsen mit, sonst meldet das System permanent „Feuer“, obwohl die Kapazität erweitert wurde.
Domains und DNS steuern
Über die Domain-Verwaltung buche ich neue Domains, verwalte Handles und setze Nameserver. Ich entscheide, ob ich die Hetzner DNS Console nutze oder eigene Nameserver betreibe. Für Services wie Mail und Web lege ich A-, AAAA-, MX- und TXT-Records gezielt an. Änderungen dokumentiere ich, damit spätere Analysen schneller gehen. Mit sauberem DNS spare ich mir unnötige Fehlersuche bei SSL, Mail oder Caching.

Backup-Strategie mit Storage-Boxen
Backups plane ich nach dem 3-2-1-Prinzip: drei Kopien, zwei verschiedene Medien, eine Kopie extern. Dafür nutze ich Storage-Boxen als offsite Ziel. Ich wähle ein inkrementelles Verfahren (z. B. blockbasiert) und verschlüssele Client-seitig. Backups laufen zeitversetzt zu Peaks und erhalten klare Aufbewahrungspläne (täglich, wöchentlich, monatlich). Entscheidender als das Backup ist der Restore: Ich teste regelmäßig Rücksicherungen und messe Dauer sowie Datenkonsistenz. Nur so weiß ich, dass ich im Ernstfall wirklich schnell wiederherstelle.
Support, Hardwaretausch und Protokolle
Tritt ein Hardwarefehler auf, eröffne ich ein Ticket direkt in der Oberfläche und beschreibe Symptome prägnant. Logs, Screenshots und SMART-Werte lege ich bei, damit die Bearbeitung zügig läuft. Den Fortschritt verfolge ich im Account und sehe, welche Schritte bereits erfolgt sind. Ein dreimonatiges Änderungsprotokoll hilft mir, Konfigurationen und Eingriffe nachvollziehbar zu halten. So bleiben Ursachen und Wirkungen klar dokumentiert.
Runbooks, Wartungsfenster und Kommunikation
Ich halte für wiederkehrende Prozesse kurze Runbooks bereit: Rescue-Boot, Reinstall, Netzwerkwechsel, Restore. Jedes Runbook hat Voraussetzungen, klare Schritte, Rollback und eine Stop-Regel. Wartungen plane ich mit Vorlauf, kommuniziere das Zeitfenster und benenne eine Kontaktadresse für Rückfragen. Nach Abschluss dokumentiere ich Abweichungen und Lerneffekte, damit das Team beim nächsten Mal schneller und sicherer arbeitet.
Automatisierung über API und Skripte
Wiederkehrende Aufgaben wie IP-Anlage, Reboots oder Monitoring-Checks automatisiere ich über die API. Ich binde Robot-Abläufe in bestehende CI/CD-Pipelines ein und minimiere manuelle Klicks. Skripte dokumentiere ich im Repository, damit ich Änderungen prüfbar halte. Für heikle Schritte setze ich Dry-Runs und sichere mich mit Rollback-Plänen ab. Auf diese Weise erreiche ich Tempo, ohne auf Kontrolle zu verzichten.

API-Playbooks aus der Praxis
- Zero-Touch-Provisioning: Server bestellen, SSH-Key setzen, Rescue-Boot, installimage mit Vorlage starten, Post-Install-Skript ausrollen, Monitoring registrieren, Failover-IP vorbereiten.
- Rollback-fähige Reinstalls: Vor dem Neuaufsetzen automatisiert komplettes Backup ziehen, Checksummen prüfen, Reinstall auslösen, Health-Checks abwarten, bei Fehlern Restore starten.
- Geplante Neustarts: Reboot-Fenster sammeln, betroffene Hosts markieren, Sequenzen definieren (Datenbank zuletzt), nach jedem Schritt Status und Metriken prüfen, bei Abweichungen Pause/Abbruch.
Kostenkontrolle und Lizenzen
Ich behalte Zusatzkosten im Blick: zusätzliche IPs, vSwitch, Sonderhardware oder Windows-Lizenzen. Traffic-Spitzen werte ich aus und plane, wann Upgrade oder Content-Optimierung günstiger ist. Rechnungen und Vertragslaufzeiten prüfe ich regelmäßig, storniere ungenutzte Ressourcen und kennzeichne Systeme klar (z. B. „Test“, „Legacy“). So verhindere ich Streuverluste und bleibe budgettreu.
Vergleich und Einordnung
Ich vergleiche die Verwaltung verschiedener Anbieter nach Bedienung, Funktionsumfang und Supportqualität. Für große Setups zählt eine klare Oberfläche mit guten Automatisierungen. In vielen Vergleichen landet webhoster.de auf Rang 1, dicht gefolgt von Hetzner Robot mit starker Funktionsbreite. Entscheidend bleibt, ob der Anbieter zur eigenen Betriebsweise passt. Wer viele Integrationen plant, sollte auf Dokumentation und APIs achten.
| Anbieter | Serververwaltung | Funktionsumfang | Support | Testsieger-Rang |
|---|---|---|---|---|
| webhoster.de | sehr intuitiv | sehr breit | exzellent | 1 |
| Hetzner Robot | leistungsstark | umfangreich | sehr gut | 2 |
| Sonstige Anbieter | unterschiedlich | begrenzt | variabel | ab 3 |
Best Practices für sicheren Betrieb
Ich aktiviere 2FA, nutze starke Passwörter und setze Passwortrichtlinien überall durch. Regelmäßige Backups mit Restore-Tests geben mir Sicherheit, dass ich im Ernstfall schnell wiederherstelle. Updates und Patches spiele ich früh ein, vor allem bei Internet-exponierten Diensten. Firewall-Regeln halte ich minimal, dokumentiere Ausnahmen und entferne veraltete Freigaben. Wer den Einstieg strukturieren möchte, findet hilfreiche Grundlagen in den Best Practices zur Serveradministration.
Typische Anwendungsfälle aus der Praxis
Hängt ein System, löse ich zuerst einen Soft-Reboot aus, prüfe Logs und eskaliere bei Bedarf zum Hard-Reset. Für OS-Wechsel nutze ich den Installer, sichere Daten und kontrolliere rDNS sowie Firewall danach erneut. Neue Domains richte ich mit passenden DNS-Records ein, damit Mail- und Webdienste ohne Verzögerung funktionieren. Bei erhöhter Last setze ich Monitoring-Schwellen enger, um früh zu reagieren und Engpässe zu entschärfen. Für Hardwareverdacht dokumentiere ich Symptome mit Zeitstempeln und eröffne ein klares Ticket.
Stolpersteine und schnelle Checks
- Kein SSH nach Reinstall: Prüfen, ob der Key korrekt hinterlegt wurde, Firewall und rDNS kontrollieren, Konsole nutzen.
- Unerwarteter Paketverlust: vSwitch/VLAN-Konfiguration, MTU und Routing testen, Monitoring-Historie auf Peaks checken.
- Mail landet im Spam: rDNS, SPF/DKIM/DMARC-Einträge prüfen, Reputation beobachten.
- Langsamer Storage: I/O-Wartezeit messen, RAID-Status und SMART prüfen, parallele Jobs drosseln.
- Fehlalarme: Schwellenwerte an reale Basislast anpassen, Wartungsfenster sauber setzen, Alarm-Korrelation nutzen.
Kurz zusammengefasst
Hetzner Robot gibt mir eine übersichtliche Schaltzentrale für Server, Storage und Domains. Ich installiere Betriebssysteme, steuere Netzwerk- und Sicherheitsregeln, überwache Systeme und hole Support, wenn nötig. Die API beschleunigt wiederkehrende Aufgaben, ohne die Kontrolle zu verlieren. Wer planvoll vorgeht, hält Setups schlank, nachvollziehbar und sicher. So behalte ich auch bei vielen Hosts jederzeit den Überblick.


