 Skip to content
Skip to content 
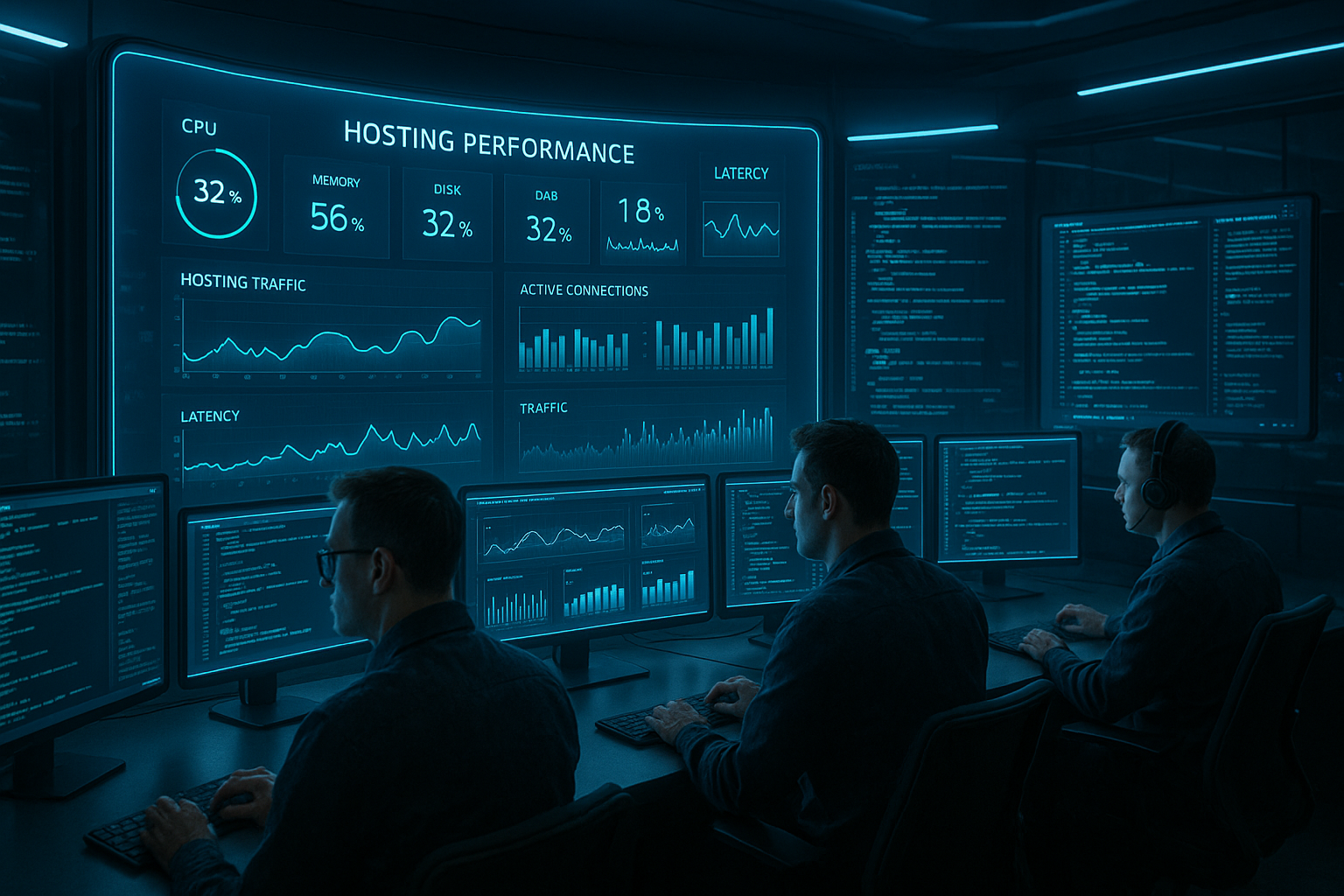
With hosting performance monitoring, I recognize performance bottlenecks early on because Tools and Logs provide me with the relevant signals in real time. With proactive alerts, anomaly detection and cleanly correlated log data, I keep latencies low, prevent outages and support visibility in the search.
Key points
I prioritize clear key figures, automated warnings and meaningful log data because they allow me to make quick diagnoses and safeguard operations. A structured setup process prevents measurement chaos and creates a reliable data basis for well-founded decisions. I choose few but meaningful dashboards so that I don't lose track in stressful situations. Integrations in chat and ticketing shorten response times and reduce escalations. Ultimately, what counts is that monitoring measurably reduces downtime and improves the user experience instead of creating additional complexity; to achieve this, I rely on clear Standards and consistent Tuning.
- Metrics prioritize: Latency, error rate, utilization
- Logs centralize: structured fields, context, retention
- Alerts automate: Thresholds, SLOs, escalation paths
- Integrations use: Slack/Email, Tickets, ChatOps
- Comparison of the tools: Functions, costs, effort

Why proactive monitoring counts
I don't wait for complaints from support, I recognize through Forecasts and Anomalies early on where systems are heading. Every millisecond of latency affects conversion and SEO, so I observe permanent trends instead of one-off peaks. This allows me to cut off unnecessary dependencies and create buffers before load peaks occur. Failures often announce themselves: error rates increase, queues grow, garbage collectors run more frequently. Reading these signs prevents downtime, reduces costs and increases trust.
Which metrics are really important
I focus on a few core values: Apdex or P95 latency, error rate, CPU/RAM, I/O, network latency and available DB connections so that I can capture the status in seconds. Without clarity about resources, I often miss the cause, so I pay attention to correlated views of all levels. For the host view, the following helps me Monitor server utilizationto quickly see bottlenecks at node level. I deliberately evaluate measurement intervals because 60-second scrapes miss short spikes, while 10-second intervals show finer patterns. It remains important to mirror the metrics against defined SLOs, otherwise I lose the Priority and the Context.
Metric design: USE/RED, histograms and cardinality
I structure signals according to proven methods: I use the USE framework (Utilization, Saturation, Errors) at host level and the RED model (Rate, Errors, Duration) at service level. In this way, each graph remains targeted and testable. I measure latencies with histograms instead of just average values so that P95/P99 are reliable and regressions become visible. Cleanly defined buckets prevent aliasing: too coarse swallows up spikes, too fine bloats memory and costs. For high-frequency endpoints, I keep copy data ready so that I can trace individual slow requests.
Cardinality is a control lever for me: labels such as user_id or request_id belong in logs/traces, but rarely in metrics. I keep label sets small, rely on service/version/region/environment and document naming standards. This keeps dashboards fast, storage plannable and queries clear. I version metrics (e.g. http_server_duration_seconds_v2) when I change buckets, so that historical comparisons don't become skewed.

Logs as an early warning system
Logs show me what is really happening because they make code paths, timing and user contexts visible. I structure fields such as trace_id, user_id, request_id and service so that I can track requests end-to-end. For the operational work I use Analyze logsto detect error sources, latency peaks and security patterns more quickly. Without clearly defined log levels, the volume becomes expensive, which is why I use debug sparingly and only increase it for a short time. I define retention periods, filters and masking so that data remains useful, legally compliant and clear instead of sprawling.
Costs under control: cardinality, retention, sampling
I actively control costs: I separate log data into hot/warm/cold tiers, each with its own retention and compression. I normalize or deduplicate faulty, extremely loud events at the ingest so that they do not dominate dashboards. I sample traces dynamically: errors and high latencies always, normal cases only proportionally. For metrics, I choose downsampling for long-term trends and keep raw data short so that storage usage remains predictable. A cost dashboard with €/host, €/GB and €/alert makes consumption visible; budget alerts prevent surprises at the end of the month.
Tools in comparison: strengths at a glance
I prefer solutions that combine logs, metrics and traces because they help me find root causes faster. Better Stack, Sematext, Sumo Logic and Datadog cover many deployment scenarios, but differ in their focus, operation and pricing logic. For teams with Kubernetes and AWS, close cloud integration pays off. If you want to keep data, you should pay attention to export capabilities and long-term storage. Before making a decision, I check the TCO, setup effort and learning curve, because cheap tariffs are of little use if the effort increases and the Findings at the end sparse remain.
| Tool | Focus | Strengths | Ideal for | Price/Hint |
|---|---|---|---|---|
| Better Stack | Logs + Uptime | Simple interface, quick search, good dashboards | Startups, teams with clear workflows | from approx. double-digit € per month, depending on volume |
| Sematext | ELK-like log management | Many integrations, real-time alerts, infrastructure + app | Hybrid environments, versatile telemetry | scaled with GB/day, from double-digit € per month. |
| Sumo Logic | Log analytics | Trend detection, anomalies, predictive analyses | Security and compliance teams | Volume-based, medium to higher € level |
| Datadog | Logs + Metrics + Security | ML anomalies, service maps, strong cloud connection | Scaling cloud workloads | modular price, features separate, € depending on scope |
I test tools with real peaks instead of artificial samples so that I can honestly see the performance limits. A resilient POC includes data pipelines, alerting, on-call routing and rights concepts. I only move when parsing, retention and cost curves are right. In this way, I avoid friction later on and keep my tool landscape lean. At the end of the day, what counts is that the tool Team faster and the Errorquote presses.
Set up automated alerts
I define threshold values based on SLOs, not gut feeling, so that alarms remain reliable. P95 latency, error rate and queue length are suitable as initial guard rails. Every signal needs an escalation path: chat, phone, then incident ticket with clear ownership. Time-based suppression prevents alarm floods during planned deployments. I document criteria and responsibilities so that new team members can act with confidence and the Readiness not in Alarm fatigue tilts.
Incident Readiness: Runbooks, Drills, Postmortems
I think of runbooks as short decision trees, not novels. A good alert links to diagnostic steps, checklists and rollback options. I practise escalations in dry runs and game days so that the team remains calm in real cases. After incidents, I write blameless postmortems, define concrete measures with the owner and due date and anchor them in the roadmap. I measure MTTA/MTTR and the alarm precision (true/false positives) so that I can see whether my improvements are working.
Integrations that work in everyday life
I forward critical alerts to Slack or email, and in the case of high priority also by phone call, so that no one misses events. Ticket integrations ensure that a task with context is automatically created from an alert. I connect webhooks with runbooks that suggest action steps or even trigger remediation. Good integrations noticeably shorten MTTA and MTTR and keep nerves calm. What counts at night in particular is that processes are effective, roles are clear and the Action comes faster than the Uncertainty.
From symptoms to causes: APM + Logs
I combine Application Performance Monitoring (APM) with log correlation to see error paths highlighted. Traces show me which service is slowing down, logs provide details about the exception. This allows me to expose N+1 queries, slow third-party APIs or faulty caches without having to grope in the dark. I use sampling in a targeted manner so that costs remain affordable and hot paths are fully visible. With this coupling, I set fixes in a targeted manner, protect release tempo and increase Quality with less Stress.

DB, cache and queue signals that count
For databases, I not only monitor CPU, but also connection pool utilization, lock wait times, replication lag and the proportion of slowest queries. For caches, I am interested in hit rate, evictions, refill latency and the proportion of stale reads; if the hit rate drops, there is a risk of avalanche effects on the database. For queues, I pay attention to backlog age, consumer lag, throughput per consumer and dead letter rate. On the JVM/.NET side, I measure GC pause, heap utilization and thread pool saturation so that I can see headroom honestly.
Practical playbook: First 30 days of monitoring
In week one, I clarify goals, SLOs and metrics, set up basic dashboards and record the top services. In week two, I activate log pipelines, normalize fields and set up the first alerts. In week three, I correct thresholds, link runbooks and test escalations in the dry run. In week four, I optimize costs through retention profiles and check dashboards for comprehensibility. The end result is clear playbooks, reliable alarms and measurable Improvementsthat I have in the Team parts.
Capacity planning and resilience tests
I plan capacity based on trends, SLO consumption and load profiles, not on instinct. Traffic replays from real user flows show me how systems react under peak patterns. I test auto-scaling with ramp-up time and scale backups (min/max) so that cold starts don't catch me cold. Canary releases and progressive rollouts limit risk; I monitor error budget consumption per release and stop deployments when SLOs tip over. Chaos and failover drills prove that HA is not wishful thinking: switch off region, lose database leader, check DNS failover.
Choosing a hosting provider: What I look out for
I check contractual availability, support response times and real performance under load, not just marketing claims. What counts for me is how quickly servers respond, how consistently storage performs and how quickly patches are available. Providers like webhoster.de score points with good packages and reliable infrastructure, which noticeably secures projects. I demand transparent status pages, clear maintenance windows and meaningful metrics. If you fulfill these points, you reduce risk, make the Monitoring and protects the Budget.

Edge, DNS and certificates at a glance
I monitor not only the origin, but also the edge: CDN cache hit rate, origin fallbacks, HTTP state distribution and latency per POP. DNS checks run from multiple regions; I check NS health, TTLs and recursion error rates. I let TLS certificates expire early (alarm 30/14/7 days in advance) and monitor cipher suites and handshake times, as these shape the perceived performance. Synthetic journeys map critical user paths (login, checkout, search), RUM shows me real end devices, networks and browser variants. Both together represent the external perspective and neatly complement server metrics.
Uptime, SLOs and budgets
I measure availability with external checks, not just internally, so that I can map real user paths. A service level objective without a measuring point remains an assertion, so I couple SLOs with independent checks. For the tool selection, a comparison like Uptime monitoringto quickly assess coverage, intervals and costs. I plan budgets per GB log, per host and per check interval so that costs remain predictable. Those who make SLO errors visible argue roadmaps cleanly and win Backing with every Prioritization.

Data pipeline and context: cleanly connecting telemetry
I rely on continuous context: trace_id and span_id end up in logs so that I can jump directly from an error log to the trace. I record deploy events, feature flags and config changes as separate events; correlation overlays on the graphs show whether a change affects the metrics. I pay attention to label hygiene: clear namespaces, consistent keys and hard limits to prevent uncontrolled growth. Tail-based sampling prioritizes abnormal spans, while head-based sampling reduces load; I combine both for each service. This keeps insights sharp and costs stable.
On-call ergonomics and team health
I structure alarms according to severity so that not every spike wakes you up. Grouped events and quiet hours reduce noise without increasing risks. Rotations are fairly distributed, handovers are documented and a backup is clearly named. I measure pager load per person, false alarm rate and nightly interventions to prevent alarm fatigue. Trained first aid steps (first responder playbook) provide security; in-depth analyses only follow once the situation is stable. In this way, readiness remains sustainable and the team resilient.
Integrate security and compliance signals
I view security as part of monitoring: anomalies in login rates, unusual IP clusters, 4xx/5xx patterns and WAF/audit logs flow into my dashboards. I consistently mask PII; only what is necessary for diagnostics remains visible. I design retention and access rights according to need-to-know, audit trails document queries of sensitive data. This keeps security, diagnostics and compliance in balance without losing operational speed.
Brief summary
I keep monitoring lean, measurable and action-oriented so that it works on a day-to-day basis. Core metrics, central logs and clear alerts give me speed in diagnosis and response. With a focused tool stack, I save costs without sacrificing insight. Integrations, playbooks and SLOs make incident work calmer and traceable. Hosting performance monitoring is therefore not an end in itself, but a Lever for better Availability and stable user journeys.


